-
解决问题的套路:数据库高写入挑战 at December 27, 2021
说的好,我补充点。你这个是技术降级时的思路,没办法了才列优先级。业务视角上所有都是重要的,缺一不可。正常情况下,技术也是可以都做好的。
-
解决问题的套路:数据库高写入挑战 at December 26, 2021
你这个分析很到位,只是理想骨感,好多时候业务方案受限于基建生态和打通成本。当规模和成本进一步增大到难以承受时,最终会倒逼走向你的方案。
-
创业一年随想 at November 11, 2021
说句忠言,你要想清楚到底是谁在创业?谁在以为自己在创业?(实际上?)
-
【上海】B 站招聘后端工程师 (golang) -- 直推 at June 27, 2021
咱社区的格局是超越语言的

-
【上海】B 站招聘后端工程师 (golang) -- 直推 at June 22, 2021
确实值得学习
-
【上海】B 站招聘后端工程师 (golang) -- 直推 at June 22, 2021
海纳百川,先奔小康

-
gRPC 系列 (四) 框架如何赋能分布式系统 at January 19, 2021
服务发现中心会定时心跳,发现挂了会立即摘掉。caller 可以针对挂掉的情况利用 grpc 做一次无缝重试
-
直播 -- 如何解决高并发下的热点挑战 at November 21, 2020
这是微服务的结构,没 web-server 的概念,缓存数据就是放在对应服务进程的内存里。核心就是探测到热点后,在内存里维护一份完整的数据,外部流量从内存读,不透到缓存层,只有定时刷新的请求才会透到下游,如此便让缓存系统避开流量洪峰的冲击。
-
直播 -- 如何解决高并发下的热点挑战 at November 21, 2020
业务上基于流量随时可能翻倍的前提预设,如果设 80% 告警,意味着发现问题时,redis 可能已经被打挂了。本质在于试图提前发现隐患。
-
Rails 没落了吗?为什么我们的社区如此冷清? at July 01, 2020
现在创业公司都招 golang 了,不完全是创业公司少的原因。
-
DHH 最新博客——“雄伟巨石”可以成为“城堡” at June 07, 2020
分工只是结果而已。大公司的老板不是 sb,不会招一大堆人来,然后为了分工再搞一套体系。
招更多的人、用复杂的架构,都是为了解决实际的问题。
任何工具,都需要思考对应的场景、需求、成本,然后才做出考量和选择。
用一句话总结:小公司用微服务的是 sb,大公司不用微服务是找死。
-
DHH 最新博客——“雄伟巨石”可以成为“城堡” at June 07, 2020
我来胡说八道几句。
DHH 的问题在于没有到有复杂业务、流量洪峰的公司做事情,所以拿着单体架构沾沾自喜。单体架构是一个极低成本,实现软件功能的途径,虽然大公司会搞很多微服务,但是像后台系统这种在大公司也是单体存在的,选择是基于场景的。这扯出了第二个问题,大部分在谈微服务的人都在出的问题。
没有基于实际需要、场景分析,就对微服务一顿狂喷,或者不限制地吹捧。
你看看发表评论的人是不是这样?一会儿分山头、势力范围、政治斗争、我觉得 XX 好,尽喷些滑稽的话,丝毫没有从业务、实际问题、解决方案、解决成本、实际场景去分析问题,然后基于问题对微服务、单体等架构模式发表观点。
举个例子,假设某人有一笔钱,问该怎么处理好呢?是放保险柜、交给老婆管、放银行、买股票基金、黄金、国债?选哪个好,有很多人就开始说了,国债稳定低风险、股票能赚钱、银行最保险还能取··· 就差有人问“你的钱金额多大,你对现金需求是怎样的,你对增值风险的期望是?···”
业界对微服务早就有极其明确的观点:不要轻易使用,但也是复杂场景下唯一的选择。
假设就做个后台系统,逻辑简单,QPS 不足一千,对稳定性要求不高。这在哪家大公司我像都更容易选择单体结构,但现实是,大公司微服务构建成本、基础设施极为健全,所以可能会往拆分上靠,但目标是怎么快怎么来。
但是你有月活 1 亿,甚至日活 1 亿呢?用单体架构就是找死,在研发效率、硬件成本、稳定性、鲁棒性、问题分析···等各个方面都是致命的问题。微服务架构是唯一的路,虽然成本高,但只要基础设施健全,好处是极为明显的。
很多人就喜欢盯着某的小业务需求,去分析思考用什么架构,一个小的或者独立的功能需求,不管怎么看,单体架构都和合适,也简单。但把眼光稍微抬高一点点看,假设公司有上百个这种业务呢?各个业务间都关联,有层次之分呢?有流量洪峰呢?怎么做让整体架构的熵最低,理解成本最低,互相调用成本最低,迁移成本最低等等 N 多种成本考量呢?
微服务架构是一种基于全局的考量,不是基于单个业务、单个功能的。也只是一种解决问题的途径和思维方式。
之前写从上帝视角看微服务时,就对很多评论感到心寒,悲剧的是,还有很多人点赞叫好,钻到小角落里不出来。
言辞有些激烈,但本意是希望社区能有更多角度、更有深度的思考,这样才能让 ruby-china 走向更好。
-
Redis 6.0 多线程 IO 处理过程详解 at May 31, 2020
这个问题很棒。
分为两种情况,看如何定义单个 client。
情况一:单个 client 和 redis 保持一个长连接,每个请求都是通过这个长连接发出。这个长连接在 redis 这边来看就是一个 socket。多线程 IO 是针对 socket 并发的,单个 socket 的内容 (例如 pipeline 一堆命令),都是顺序执行的。不存在乱序问题,命令的执行本身没有并发,依然是单线程串行执行的。多线程 IO 是并发读写 socket,并不处理命令。命令的执行顺序就是 tcp 发包的顺序,这个是有序的。
情况二:你说的 client,每发送一个命令都用一个新的 TCP 连接,在 redis 来看就是多个 socket(也是多个 client),此时谁先处理完就说不清楚了。
我画的图上有些歧义,我先改一下
-
多线程的 Redis at May 17, 2020
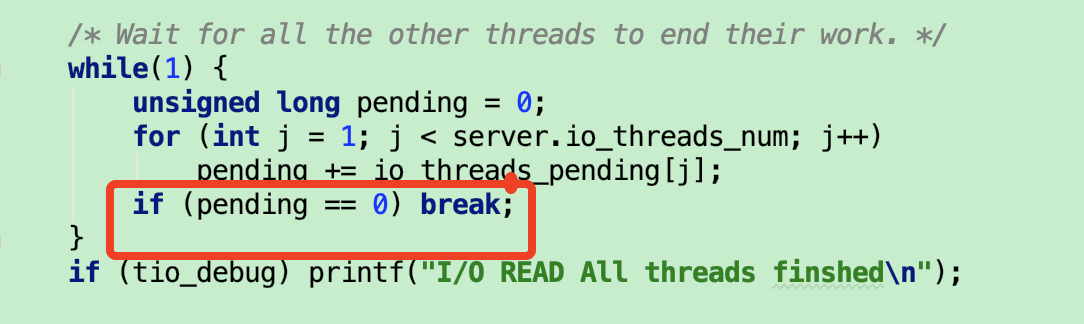 阻塞时检测的是,IO 线程是否还有任务。等处理完了才继续往下。
阻塞时检测的是,IO 线程是否还有任务。等处理完了才继续往下。这些任务是在执行时添加的,如果 任务数< 线程数,那有些线程就拿不到任务,它的待处理任务就是 0。
分配了任务的线程,在处理好 IO 事件后,pending 就会清零,没拿到任务的线程 pending 本来就是 0,所以不会阻塞。
这个点,在计划写文章捋清楚。到时再交流哈。
-
微服务如何做聚合接口? at April 10, 2020
这个很常见。
以直播业务来讲,用户进房间时,会调用一个核心接口。这个接口就是一个 APP 网关提供的,resp 比较大,这个接口内部,会调用 20~40 个下游,通过 golang 并发拉取。将各个下游的数据及逻辑做统一处理后返回。(见过直播琳琅满目的界面你会懂的)
尽管这个网关接口聚合了 30+ 个下游的逻辑,APP 进房间依然会调用好多个接口,有各种用途。你让 APP 进房间分别调用这些接口?肯定不能这么做。
聚合的原因很明显:
- 降低了页面打开的耗时。聚合接口将页面核心数据用一路 tcp 请求解决。如果几十个接口同时请求,用户侧到 SLB 的公网连接非常多,受网络影响的可能性大增。
- 降低了客户端代码的复杂性。一个页面,渲染的数据通过多个接口获取,客户端的渲染逻辑不敢想象,数据达到时间不一致,页面会很不稳定,要不就等所有接口都返回才渲染,那耗时就是最差的那个连接。安卓端处理了这种多请求的逻辑,IOS 是不是还要处理一次?服务端一个接口就可以把这个复杂性解决,而且很简单,一个并发等待就可以解决。
- 提升可靠性。假设上百万人短时间窗口进房间,请求一个核心接口,很容易对这个接口的数据统一做降级、缓存、保障。如果单独请求几十个请求,配限流就把人累死了。
- 改善工程水平。服务端逻辑聚合、复用能力提升。代码都在一起,查看逻辑、扩展、解决问题都很快。更重要的是,服务端的业务治理可以自然分层、拆分。数据流的聚合、分层、分流链路清晰,便于统一规划。
- 其他
slb -> 聚合层 -> 大量调用各种下游 -> 下游再调各种下游 -> 缓存、DB 这种结构,需要将服务端做分层,聚合层、服务层、数据层。如果业务复杂度不高,建议不搞。
-
【上海】薄荷科技诚聘 Ruby 工程师 2 名 at March 29, 2020
关于假期 30 分钟内必须回 dingding 消息的事情,晚上有点兴奋,我多几句嘴。
如果我是管理层,我会制定一个轮班机制:
- 每天有一个人轮班,有问题在 dingding@他,只有值班那天 Ta 才会注意群消息
- Ta 来判断事情是怎么回事,对客服等作出响应。如果是可以延后慢慢处理的,直接归档就行,如果紧急的,直接给对应模块负责人打电话
- 每个人不用每天下班都对手机消息一惊一乍的
- 很多时候所谓的”故障“是临时或无关紧要的,或者值班的人就可以简单解决
用大腿想一下,每个人都要在下班时盯着群消息,一惊一乍的。这个综合成本有多高,有多少无效劳动和心智消耗,需要加多少工资才能弥补上。
-
【上海】薄荷科技诚聘 Ruby 工程师 2 名 at March 29, 2020
你这个还是 KPI,只是换了一个说法。
- OKR 是要暴露一个目标 Objective:
App 产品和技术系统高质量开发和运行 - 通过多个 KeyAction 拆解关键步骤和环节,以达到上面的 Objective,核心是要体现出思路、解决方案、关键途径等。
- keyAction 需要有多个有梯度的 KeyResult,KeyResult 是衡量 keyAction 的执行质量和目标水位,需要给出明确、有梯度、可循序渐进达到的标准,有些目标不是一下就能达到,要分步。
App 崩溃率万分之一以内
这个是一个 KeyResult,还应该有对应的梯度,比如 99% 是勉强及格,99.99 是及格,99.999 是超越预期等等。
可是 KeyAction 呢?如何达到这个目标呢?通过什么途径?用什么方法? (建议补充出来,不要藏知识)
OKR 的精髓是一个思考框架,帮助组织将大的 Objective 拆成小 Objective,并往下层分发。Objective -> KeyAction -> KeyResult 这些点的落地、拉通、对齐、筛选就是在设定一整套体系、解决方案、解决途径、解决步骤。
通过提出一个目标,走一遍 OKR 流程,可以引导出解决方案,这是一个方法论,超越 KPI 的地方。
- OKR 是要暴露一个目标 Objective:
-
【译】快乐的和平主义者(下架) at March 21, 2020
互联网的数据,多跳一层流量减少 80%。连微信都在想办法减少跳入层级···,不过得看你想要的是什么。
-
想了解 Java 微服务横行的当下,还有多少人用 Rails 的? at March 16, 2020
中大厂的大规模分布式系统,微服务、容器化是唯一的出路。一方面是为了复杂度分解,细化协作分工、提高整体研发效率和稳定性,必须要这么做。
微服务确实能解决很多问题,让很多东西更容易实施。但一旦拆分后,整体的复杂度会提升十倍以上,主要是分布式体系中网络复杂度和链路复杂度。这需要有相当强大的基础设施来降低这种复杂度,主要是强悍的框架和基础库、pass 能力、数据采集、基础服务、工具链。最难的是要让这些东西保持稳定性和迭代能力,这需要堆非常多的人,一个部件都需要一个团队。
估计你这边人力资源投入不够,这套东西又烧钱又耗人力。
-
一文理解 Redis Cluster at March 14, 2020
我重新上传一下
-
直播 -- 弹幕系统简介 at March 09, 2020
你们 router 的定位是什么?如何设计的,为啥要广播。
我问了一下 bilibili 实际使用,本文中 Router 的设计有些直接废掉了,有些换成了 redis,将 Router 逻辑直接合到 logic。 因为有状态的 Router 一旦挂掉非常麻烦,必须要做高可用,数据还得做强一致性。
其他节点挂掉后,直接重新拉起来就行,影响不大。
-
从 LRU 到 LIRS at March 08, 2020
有个“重复的块不算”的表述,但前后没有统一,导致少了 1
-
远程办公:如何提高自制力? at February 12, 2020
用了较大的成本去增加自己“贪玩”的成本,也许可以尝试从根上去解决问题。 比如分析迷恋手机的原因是什么? 是对信息的焦虑,还是其他等等,针对性地采取策略。 解决了这个,就不用太麻烦了。
-
在公司里为各种业务逻辑做算法优化,却感觉不如商务人员聊天做 PPT 受重视 at January 18, 2020
很多技术 just 工具而已,非高科技的程序员是工具人。
各个互联网公司用制造业的手法,将流程强化、动作固化、标准细化,追求高效率、低成本。
人只是运转机器中的螺丝和零部件,各个职业经理人做的事情就两件:1.搭建机器 2.让各个部件能更容易被替换。
其实纵观整个行业,除了极高水平的科技外(这个能改造规则),对公司价值最高的都是:销售&营销。
IT 部门算个啥呢,本来就是底层的执行层,被告知要干啥干啥,产品经理把逻辑和图都给你准备好了。
知道要做啥&为什么要做&如何选择优先级,远比执行本身更有价值。
-
从 LRU 到 LIRS at January 18, 2020
感谢你的反馈
-
一个 MySQL 死锁案例分析 --Index merge when update at November 29, 2019
一起学习,感谢你的回复
-
直播 (上) -- 底层逻辑浅析 at October 29, 2019
在有直播业务的公司搬砖。 其实直播那套眼花缭乱的业务都是很“成熟”的技术应用,一般技术团队都能搞,稳定性就看公司的基础设施建设了。 核心的是,音视频采集、加工、传输、分发这套工业流程体系,就是传说中的推拉流。 这里面有无数的算法技术智慧结晶,稍微了解了一下膜拜不已。
-
表中只有两个 id 字段的优化问题 at July 07, 2019
这个不存在优化问题,表结构已经很简洁了,也许可以考虑如何缓存供货关系,不要一直查 DB。等数据量大到一定程度,你应该会选择按照 [供货商 ID] 分库分表了。
-
我的透明创业实验 at May 20, 2019
程序员的正确姿势
-
如何看待 996.ICU at April 28, 2019
996.icu 是社会对劳动密集型、可替代性强、年龄敏感、壁垒不高等等强应用型职业面临的严峻挑战的一种善意提醒。
这种职业状态是很大一部分程序员职业发展可能的最终状态。
世上大部分抗议都是效果不大的,只有尽可能想办法避开。
以上说给我自己听的。