引
大半年前,看到 Redis 即将推出“多线程 IO”的特性,基于当时的各种资料,和 unstable 分支的代码,写了《多线程的 Redis》,浅尝辄止地介绍了下特性,不够华也不实。本文将深入到实处,内容包含:
- 介绍 Redis 单线程 IO 处理过程
- 单线程的问题
- 解析 Redis 多线程 IO 如何工作
要分析多线程 IO,必须先搞清楚经典的单线程异步 IO。文章会先介绍单线程 IO 的知识,然后再引出多线程 IO,如果已经熟悉,可以直接跳到多线程 IO 部分。
接下来我们一起啃下这两块大骨头。代码基于: https://github.com/antirez/redis/tree/6.0
异步 IO
Redis 核心的工作负荷是一个单线程在处理,但为什么还那么快?
- 其一是纯内存操作。
- 其二就是异步 IO,每个命令从接收到处理,再到返回,会经历多个“不连续”的工序。
(为避免歧义,此处的异步处理 IO 不是“同步/异步 IO”,特指 IO 处理过程是异步的,描述的对象是处理过程。)
假设客户端发送了以下命令:
GET key-how-to-be-a-better-man?
redis 回复:
努力加把劲把文章写完
要处理命令,则 redis 必须完整地接收客户端的请求,并将命令解析出来,再将结果读出来,通过网络回写到客户端。整个工序分为以下几个部分:
- 接收。通过 TCP 接收到命令,可能会历经多次 TCP 包、ack、IO 操作
- 解析。将命令取出来
- 执行。到对应的地方将 value 读出来
- 返回。将 value 通过 TCP 返回给客户端,如果 value 较大,则 IO 负荷会更重
其中解析和执行是纯 cpu/内存操作,而接收和返回主要是 IO 操作,这是我们要关注的重点。以接收为例,redis 要完整接收客户端命令,有两种策略:
- 接收客户端命令时一直等,直到接收到完整的命令,然后执行,再将结果返回,直到客户端收到完整结果,然后才处理下一个命令。这叫同步。同步的过程中有很多等待的时间,例如有个客户端网络不好,那等它完整的命令就会更耗时。
- 客户端的 TCP 包来一个才处理一个,将数据追加到缓冲区,处理完了就去立即找其他事做,不等待,下一个 TCP 包来了再继续处理。命令的接收过程是穿插的,不连续。一会儿接收这个命令,一会儿又在接收另一个。这叫做异步,过程中没有额外的空闲等待时间。
用聊天的例子做对应,假设你在回答多个人的问题,也有同步和异步的策略:
- 聊天框中显示“正在输入”时,你一直等 ta 输入完毕,然后回答 ta 的问题,再发送出去,发送时会有等待,常规表现就是有个圆圈在转。你等发送完毕后,才去回答另一个人的问题。同步
- 显示“正在输入”时,不等 ta,而是去回答其他输入完毕的问题,回答完后,不等发送完毕,又去回答其它问题。异步
很显然异步的效率更高,要实现高并发必须要异步,因为同步有太多时间浪费在等待上了,遇到网络不好的客户端直接就被拖垮。异步的策略简单可总结如下:
- 网络包有数据了,就去读一下放到缓冲区,读完立马切到其他事情上,不等下一个包
- 解析下缓冲区数据是否完整。如完整则执行命令,不完整切到其他事情上
- 数据完整了,立即执行命令,将执行结果放到缓冲区
- 将数据给客户端,如果一次给不完,就等
下次能给时再给,不等,直到全部给完
事件驱动
异步没有零散的等待,但有个问题是,如果 redis 不一直阻塞等命令来,咋个知道“网络包有数据了”、“下次能给时”这两个时机?如果一直去轮训问肯定效率很低,要有个高效的机制,来通知 redis 这两个时刻,由这些时刻来触发动作。这就是事件驱动。
一个新TCP包来了、可以再次发给客户端数据这两个时机都是事件。与之对应的就是 redis 和客户端之间 socket 的可读、可写事件 [1] ,就像微信聊天中新消息提醒一样。linux 中的 epoll 就是干这个事的,redis 基于 epoll 等机制抽象出了一套事件驱动框架 [2],整个 server 完全由事件驱动,有事件发生就处理,没有就空闲等待。
单线程 IO 处理过程
redis 启动后会进入一个死循环 aeMain,在这个循环里一直等待事件发生,事件分为 IO 事件和 timer 事件,timer 事件是一些定时执行的任务,如 expire key 等,本文只聊 IO 事件。
epoll 处理的是 socket 的可读、可写事件,当事件发生后提供一种高效的通知方式,当想要异步监听某个 socket 的读写事件时,需要去事件驱动框架中注册要监听事件的 socket,以及对应事件的回调 function。然后死循环中可以通过 epoll_wait 不断地去拿发生了可读写事件的 socket,依次处理即可。
可读可以简单理解为,对应的 socket 中有新的 tcp 数据包到来。
可写可以简单理解为,对应的 socket 写缓冲区已经空了 (数据通过网络已经发给了客户端)
一图胜前言,完整、详细流程图如下:
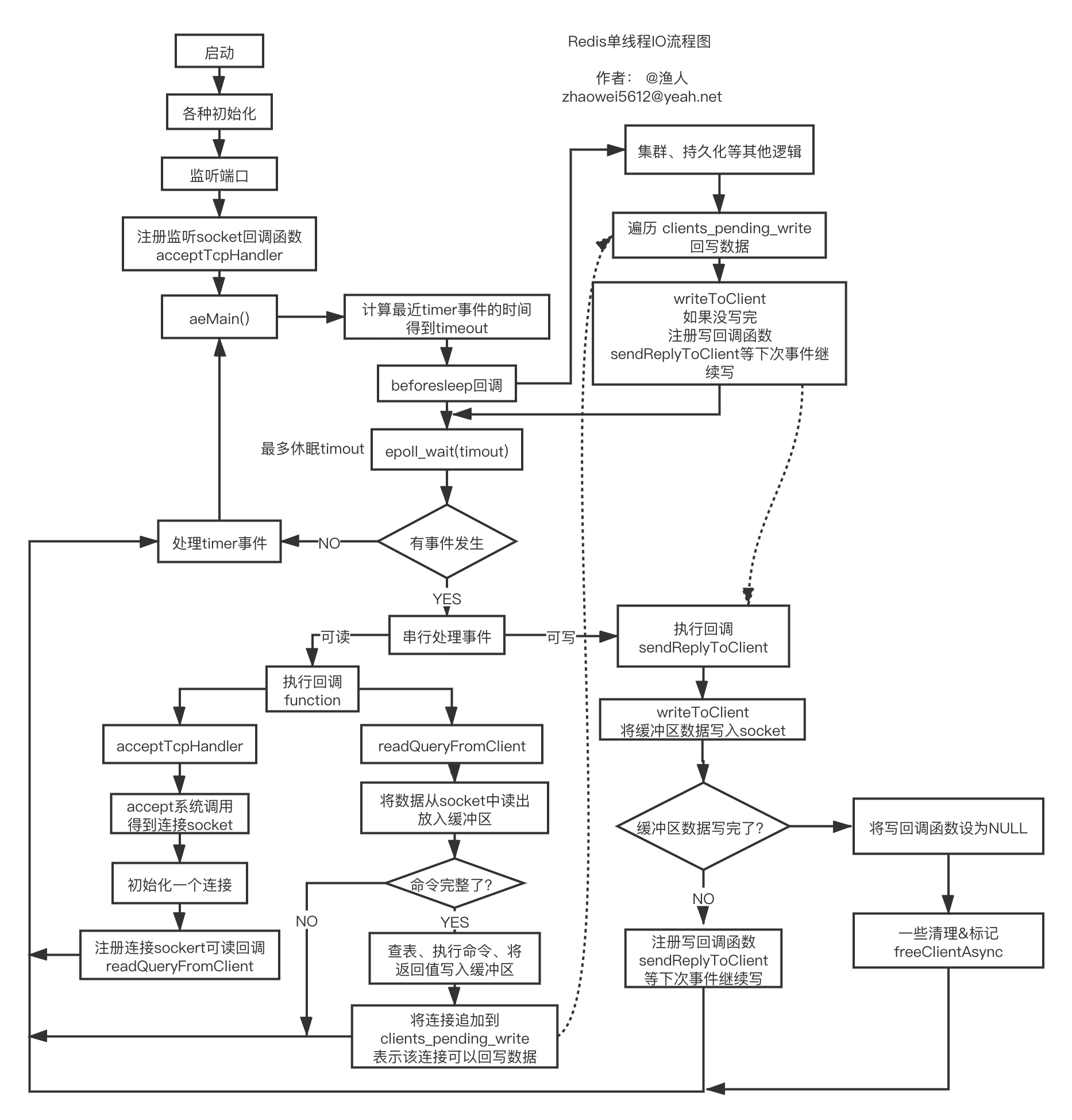
- aeMain() 内部是一个死循环,会在 epoll_wait 处短暂休眠
- epoll_wait 返回的是当前可读、可写的 socket 列表
- beforeSleep 是进入休眠前执行的逻辑,核心是回写数据到 socket
- 核心逻辑都是由 IO 事件触发,要么可读,要么可写,否则执行 timer 定时任务
- 第一次的 IO 可读事件,是监听 socket(如监听 6379 的 socket),当有握手请求时,会执行 accept 调用,得到一个连接 socket,注册可读回调 createClient,往后客户端和 redis 的数据都通过这个 socket 进行
- 一个完整的命令,可能会通过多次 readQueryFromClient 才能从 socket 读完,这意味这多次可读 IO 事件
- 命令执行的结果会写,也是这样,大概率会通过多次可写回调才能写完
- 当命令被执行完后,对应的连接会被追加到 clients_pending_write,beforeSleep 会尝试回写到 socket,写不完会注册可写事件,下次继续写
- 整个过程 IO 全部都是同步非阻塞,没有浪费等待时间
- 注册事件的函数叫 aeCreateFileEvent
单线程 IO 的瓶颈
上面详细梳理了单线程 IO 的处理过程,IO 都是非阻塞,没有浪费一丁点时间,虽然是单线程,但动辄能上 10W QPS。不过也就这水平了,难以提供更多的自行车。
同时这个模型有几个缺陷:
- 只能用一个 cpu 核 (忽略后台线程)
- 如果 value 比较大,redis 的 QPS 会下降得很厉害,有时一个大 key 就可以拖垮
- QPS 难以更上一层楼
redis 主线程的时间消耗主要在两个方面:
- 逻辑计算的消耗
- 同步 IO 读写,拷贝数据导致的消耗
当 value 比较大时,瓶颈会先出现在同步 IO 上 (假设带宽和内存足够),这部分消耗在于两部分:
- 从 socket 中读取请求数据,会从内核态将数据拷贝到用户态(read 调用)
- 将数据回写到 socket,会将数据从用户态拷贝到内核态(write 调用)
这部分数据读写会占用大量的 cpu 时间,也直接导致了瓶颈。如果能有多个线程来分担这部分消耗,那 redis 的吞吐量还能更上一层楼,这也是 redis 引入多线程 IO 的目的。[3]
多线程 IO
上面已经梳理了单线程 IO 的处理流程,以及多线程 IO 要解决的问题,接下来将目光放到:如何用多线程分担 IO 的负荷。其做法用简单的话来说就是:
- 用一组单独的线程专门进行 read/write socket 读写调用(同步 IO)
- 读回调函数中不再读数据,而是将对应的连接追加到可读 clients_pending_read 的链表
- 主线程在 beforeSleep 中将 IO 读任务分给 IO 线程组
- 主线程自己也处理一个 IO 读任务,并自旋式等 IO 线程组处理完,再继续往下
- 主线程在 beforeSleep 中将 IO 写任务分给 IO 线程组
- 主线程自己也处理一个 IO 写任务,并自旋式等 IO 线程组处理完,再继续往下
- IO 线程组要么同时在读,要么同时在写
- 命令的执行由主线程串行执行 (保持单线程)
- IO 线程数量可配置
完整流程图如下:
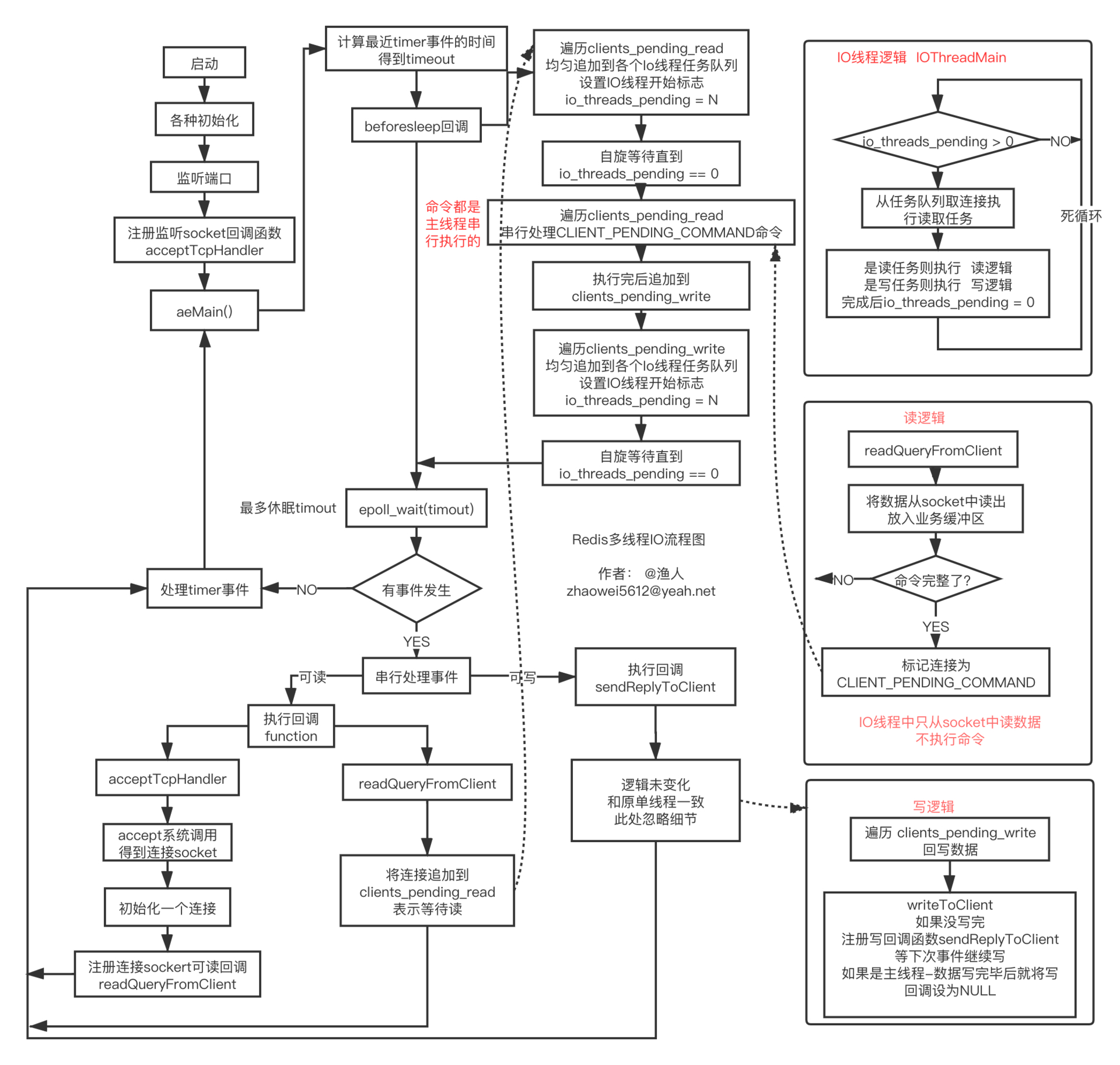
beforesleep 中,先让 IO 线程读数据,然后再让 IO 线程写数据。读写时,多线程能并发执行,利用多核。
将读任务均匀分发到各个 IO 线程的任务链表 io_threads_list[i],将 io_threads_pending[i] 设置为对应的任务数,此时 IO 线程将从死循环中被激活,开始执行任务,执行完毕后,会将 io_threads_pending[i] 清零。函数名为:handleClientsWithPendingReadsUsingThreads
将写任务均匀分发到各个 IO 线程的任务链表 io_threads_list[i],将 io_threads_pending[i] 设置为对应的任务数,此时 IO 线程将从死循环中被激活,开始执行任务,执行完毕后,会将 io_threads_pending[i] 清零。函数名为:handleClientsWithPendingWritesUsingThreads
beforeSleep 中主线程也会执行其中一个任务 (图中忽略了),执行完后自旋等待 IO 线程处理完。
读任务要么在 beforeSleep 中被执行,要么在 IO 线程被执行,不会再在读回调中执行
写任务会分散到 beforeSleep、IO 线程、写回调中执行
主线程和 IO 线程交互是无锁的,通过标志位设置进行,不会同时写任务链表
性能据测试提升了一倍以上 (4 个 IO 线程)。 [4]
欢迎您的提问、指正、建议等。首发在这里
