今年年底将要发布的 Redis6.0 会支持“多线程”,消息已经通过官方渠道发出。
其实严格意义上来讲,Redis 并不是单线程。它也有后台线程在工作,处理一些较为缓慢的操作,例如无用连接的释放、大 key 的删除等等。
但是客户端命令的请求获取 (socket 读)、解析、执行、内容返回 (socket 写) 等等都是由一个线程处理,所有操作是一个个挨着串行执行的 (主线程),这也是 Redis 有“单线程”定义的来源。
单线程机制使得 Redis 内部实现的复杂度大大降低,Hash 的惰性 Rehash、Lpush 等等“线程不安全”的命令都可以无锁进行。
但是这套机制也使得 Redis 的 QPS 难以更上一层楼。Redis 本身的数据结构设计,内存管理已经做得接近尽善尽美。要 Redis 单机性能进一步提升,引入多线程并发处理任务是最直观的方案之一,和 memcached 对齐。
多线程的机制有两大直观优点:
- 可以充分利用服务器 CPU 资源,目前主线程只能利用一个核
- 多线程任务可以分摊 Redis 同步 IO 读写负荷
第一点,多线程执行提高并发度,进而提升 QPS 比较好理解。第二点需要单独做下解释。
常规情况下,Redis 使用的是同步非阻塞 IO,通过多路复用机制 (linux 上用 epoll) 封装成事件驱动机制。非阻塞 IO 在调用时不会导致进程因为等待 IO 事件而阻塞,通过 epoll 的机制,在 IO 事件发生时通过异步的方式通知用户态进程处理,这点极大地提高了 IO 的处理效率,事件模型大概如下:
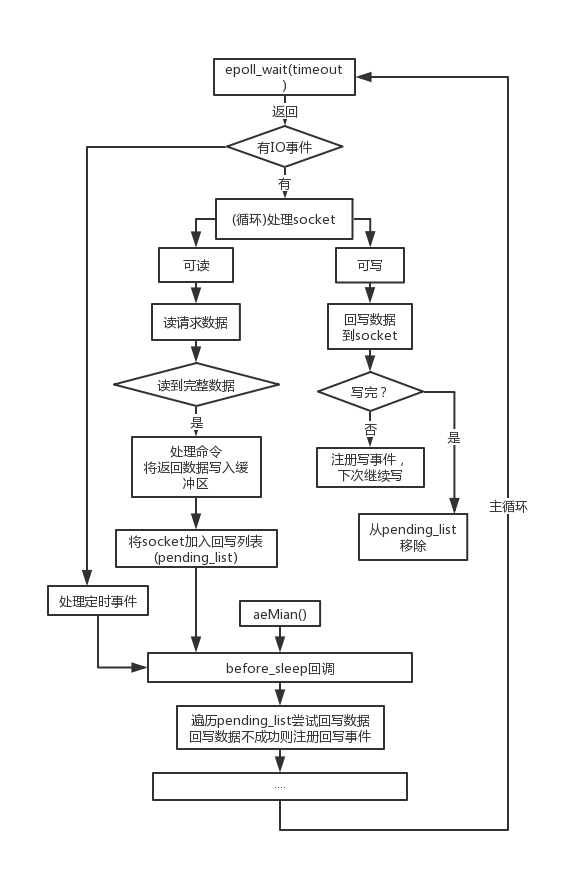
Redis 抽象了一套 AE 事件模型,将 IO 事件和时间事件融入一起,同时借助 epoll 的回调特性,使得 IO 读写都是非阻塞的,实现高性能的网络处理能力。加上 Redis 基于内存的数据处理,这便是“单线程,但却高性能”的核心原因。
但 IO 数据的读写依然是阻塞的,这也是 Redis 目前的主要性能瓶颈之一,特别是在数据吞吐量特别大的时候,具体情况如下:
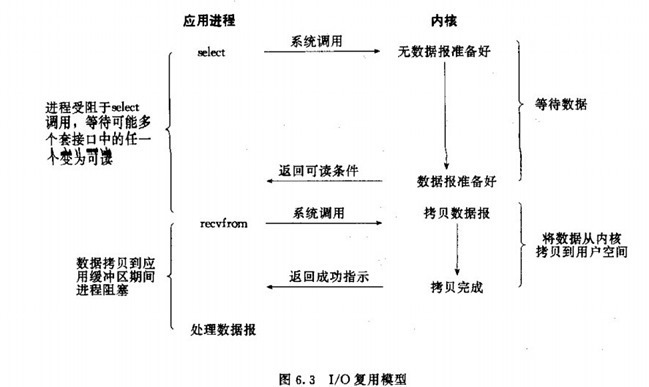
上图的下半部分,当 socket 中有数据时,Redis 会通过系统调用将数据从内核态拷贝到用户态,供 Redis 解析用。这个拷贝过程是阻塞的,术语称作“同步 IO”,数据量越大拷贝的延迟越高,时间消耗也越大,糟糕的是这些操作都是单线程处理的。(写 reponse 时也是一样)
这是 Redis 目前的瓶颈之一,Redis6.0 引入的“多线程”机制就是对于上诉瓶颈的优化。
核心思路是,将主线程的 IO 读写任务拆分出来给一组独立的线程执行,使得多个 socket 的读写可以并行化。(命令的执行依然是主线程串行执行)
核心流程大概如下:
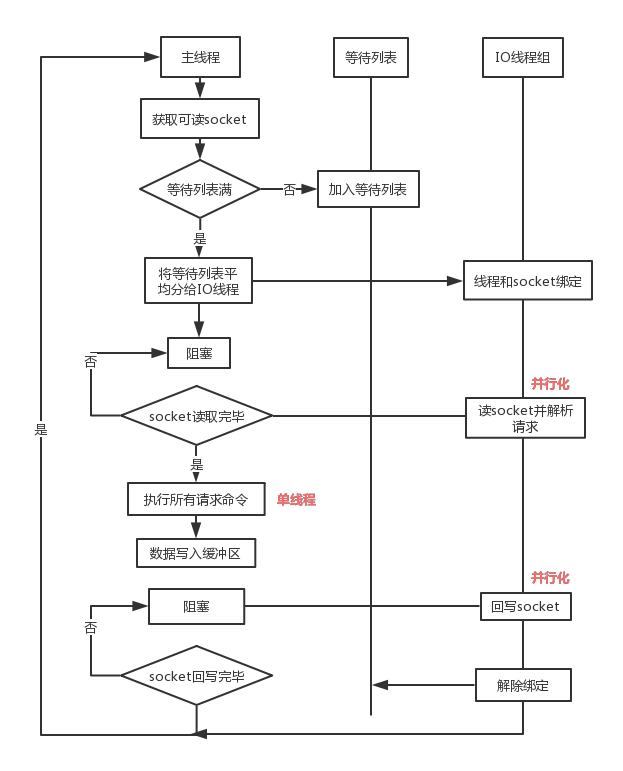
流程简述如下:
- 主线程获取 socket 放入等待列表
将 socket 分配给各个 IO 线程(并不会等列表满)
主线程阻塞等待 IO 线程读取 socket 完毕
主线程执行命令 - 单线程(如果命令没有接收完毕,会等 IO 下次继续)
主线程阻塞等待 IO 线程将数据回写 socket 完毕(一次没写完,会等下次再写)
解除绑定,清空等待队列
有如下特点:
- IO 线程要么同时在读 socket,要么同时在写,不会同时读或写
- IO 线程只负责读写 socket 解析命令,不负责命令处理(主线程串行执行命令)
- IO 线程数可自行配置(目前代码限制上限为 512,默认为 1(关闭此功能))
经过有心人士的压测,目前性能能提高 1 倍以上。
不过目前有些疑问:
IO 线程数的设置应该按照怎样的标准设置
如果有慢 client 拖慢了整个读写过程怎么办?(主线程在阻塞)(搞清楚这个伪问题,才真正理解 reids 多线程 IO)
谈下你的观点?
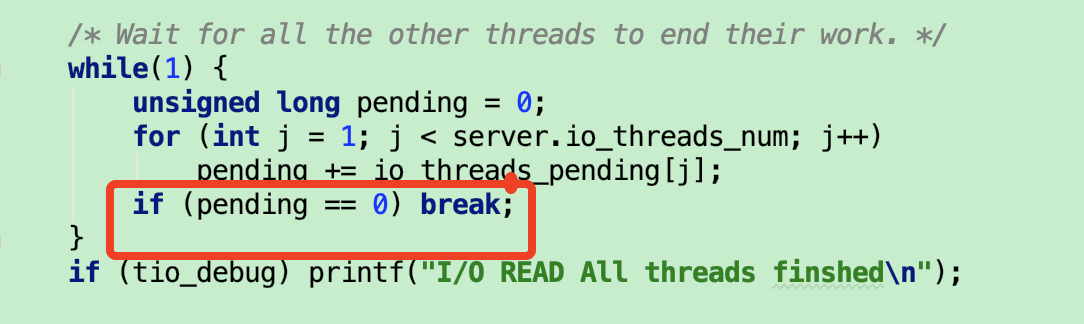 阻塞时检测的是,IO 线程是否还有任务。等处理完了才继续往下。
阻塞时检测的是,IO 线程是否还有任务。等处理完了才继续往下。