通过 Redis 可以很简单的利用多种数据结构实现复杂的业务。最常见的莫过于缓存服务这一互联网不可或缺的重要部分,本文也将顺着缓存的思路梳理 Redis Cluster 的样貌,以对其形成更加扎实的认识。
缓存的需求
新起一个业务时,因为早期流量稀少,且有快速交付产品的需求,工程师们往往会选择直接读写数据库。
而当流量逐渐上升,DB 负荷增加,慢慢地响应变慢,甚至有宕机的风险,此时需要增加一层缓存,避免频繁读取数据库,结构类似下面:
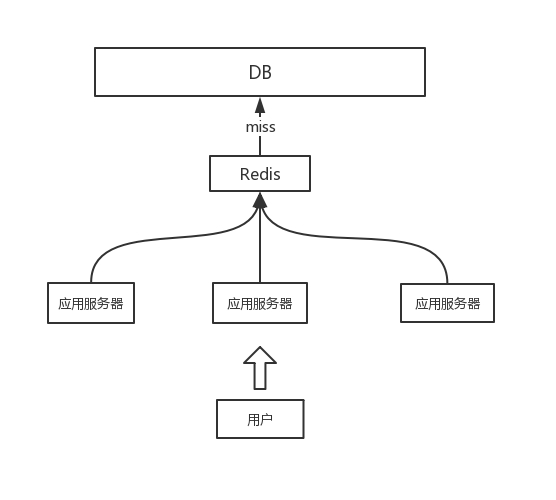
当流量增加时,可以增加应用服务器的数量,进行横向扩展。不过,慢慢地 Redis 缓存服务就会遇到两大问题:
单机 Redis 内存大小有限,已经放不下缓存的数据了
业务流量太高,所有请求都会经过 Redis,到达 QPS 极限
这是单机模式在流量和数据量增大时必然会遇到的问题,本质上是单台计算机在内存和网络吞吐上的存在容量极限。基于当前计算机的特点,解决此问题的方案有两个:
大型机,用更强悍的大型机来暂时 hold 住当前的性能需求
分布式,将数据分散到多台机器上
一般情况下,长久可靠的方案一般都是采用数据分片的策略,让单机变成集群。将数据量和性能需求打散到多台机器上,分而治之。
单机到集群
将数据和请求分散到多台机器上,可以较好的解决上面流量和数据量两个方面的问题。不过紧接着得思考:
- 如何让流量分散到多台机器上?
如何让数据分散到多台机器上?
如何让后期集群扩容更加便捷?
流量本质上是读写数据时产生的,数据的分布会引导流量的分布,所以前两个问题本质上是一个问题。
当前最广泛的数据分布策略是通过哈希算法,对 Redis 缓存来说,就是对 Key 计算哈希值,理想情况下的哈希值计算有几个特点:
相同的 key,每次哈希计算的值都一样(可保证数据分布是稳定的)
不同的 key,哈希计算的结果是均匀分布的(可保证数据均匀分布在多台机器上)
对哈希值取模就可以得到数据应该分布到哪台机器上,这样便可以让数据分散到多台机器。对于上面的单机模式来讲,现在多了一部分工作,就是在读写 Key 时需要先计算一下 Key 应该在哪台机器上,为了将这部分工作收拢,Redis 集群代理这个角色便出现了,它负责计算 key 应该存放到哪个节点,对应的也知道去哪个节点取对应的数据。
从应用服务器来看它就是一台 Redis 服务器,常见的有 twemproxy 等。
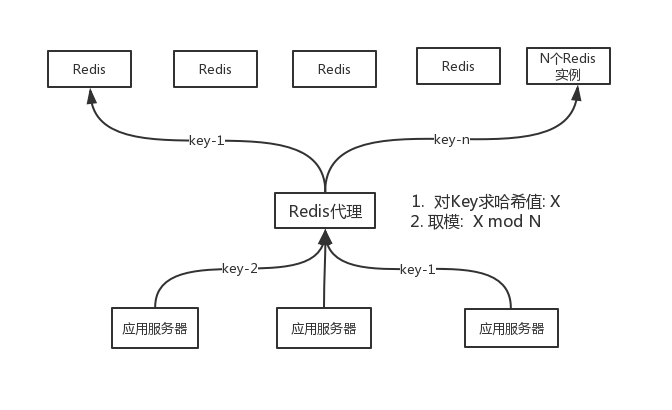
流量会根据哈希取模的操作分散到多个 Redis 服务器上,所有流量通过代理统一分发,代理本身也可以扩展为多台,来分散流量,只要各个 Redis 代理使用相同的哈希取模策略即可。
到此万事大吉,除了集群扩展的便捷性。上面的模式知道 Redis 实例的确切数量 N,在其基础上取模,而当 Redis 数量增加或减少时,此套机制则面临挑战。X mod N 的计算方式,当 N 发生变化时,大部分计算结果也会变化,这会导致大部分 Key“重新分布”,影响面很广。
为了减轻节点数变化时对数据分布的影响,在代理选择数据分布时不能使用简单粗暴的哈希取模,而应该使用一致性哈希。
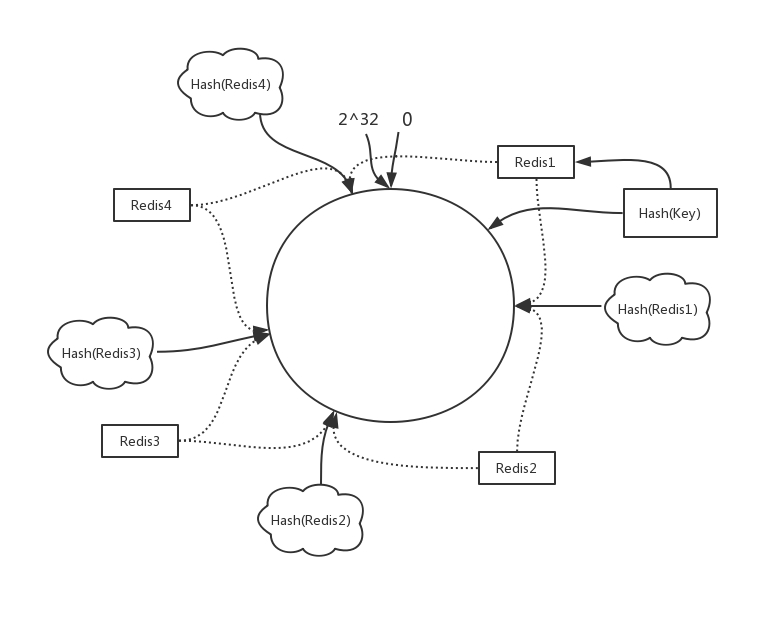
特定的哈希函数输出值有特定的区间,例如 [0, 2^32], 函数输出最小值 0,最大 2^32。一致性哈希将这个区间抽象地看作一个闭合的圆。
假设当前有 4 个实例,将各个 redis 实例做哈希计算 (可以用 ip:端口),哈希值都会落到区间中,由于哈希函数的均匀性,这个闭合的圆会被切分成 4 个弧 (虚线)。
Hash(key) 的值落到哪个弧上,则这个 key 的数据就存放到对应的 Redis 实例上, 每个 Redis 实例上汇集的数据都是 Key 的哈希值在一段特定的连续区间内,而简单的哈希取模方式则汇聚的是断断续续分散的区间。当有 Redis 实例新增或移除时,对数据的分布影响是有限的,只会影响其本身和相近的弧中的部分数据,这使得集群扩展的代价小了很多。
Redis Cluster
上面的群集方式,仍然有大概两个缺点:
需要中心化的代理,有性能损耗,且难支持 pipeline
节点增减时数据迁移困难,难以搞清楚到底需要迁移哪些数据
Redis Cluter 实现了完全去中心化、线性扩展的集群方案。针对数据迁移的问题,Redis 提出了哈希槽的概念,每个集群中固定有 [0,16383],总共 16384 个槽,每个 key 属于某个特定的哈希槽,通过CRC16算法和公式
slot=CRC16(key)/16384
来计算 key 属于哪个槽。这些槽会被大致均匀地分布在集群的实例上。如果有三个实例 A, B, C:
Node A contains hash slots from 0 to 5500.
Node B contains hash slots from 5501 to 11000.
Node C contains hash slots from 11001 to 16383.
理论上集群最多可以有 16384 个节点,每个节点负责一个槽。
哈希槽的设计对节点数据迁移很友好,节点会记录每个槽中存在哪些 key,当要新加入一个节点 D 时,在 ABC 中分别挑一部分槽的数据移动到 D 就行,移除也是一样,集群可便捷地进行线性扩展。
Redis Cluster 没有中心化的代理节点,集群中的每个节点都可以暴露出来作为 client 节点接受读写请求。
但是每个节点实际上只有一部分数据,通过公式可以知道,每个 key 其实是确切地属于某个哈希槽的,每个节点负责的哈希槽其实也是确定的。集群中每个节点都有一份数据分布“地图”,每个节点都知道 key 应该在哪个实例上,映射关系被保存在一个数组中,通过 index 可以 O(1) 读取:
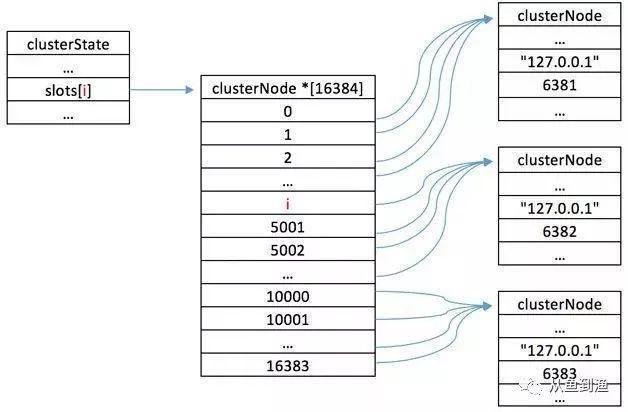
当有请求到达某个节点,但 key 没有存放到自己的节点上时,Redis 会返回特定的 MOVED 重定向,告诉请求方,这个 key 属于哪个槽,在哪个节点上 (ip:port)。
GET xxxxx
对于常规的请求方就非常痛苦了,因为还要处理重定向的情况。
这对 client 的要求一下子变高了,每个 client 需要知道上图的数据分布,维护和每个 Redis 实例的连接,每个请求前先计算 key 在哪个实例上,再选择对应的连接将请求发送出去。同时类似 pipeline 的操作将变得更加复杂。如果数据分布发生了变化,client 还需要及时进行更新,这种新的 client,被称为 Smart Client,也就是常说的 SDK,这里有更多的信息 (https://redis.io/clients)
这种 Smart Client 开发难度较以前相对较大,而且每个 client 都需要维护一份分布数据,当集群分布发生变化时,每个 client 都得重新刷新分布数据状态,这并不算一个好的结果,因为集群复杂性暴露给了调用方,即使只是 SDK。
为了应对这种情况,对 client 屏蔽集群信息,一种新的代理又重新出现,代理会维护集群数据分布的数据,可以集中地支持像 pipeline 这样的操作,让 client 保持简单。饿了么的 corvus 就是其中一种实现 (https://github.com/eleme/corvusSmart),它实际上就是一个 Proxy,实现了 Smart Client 处理集群信息的功能,有几个明显的优点:
让 Client 保持简单,不必关心集群复杂性
Proxy 可以简单扩展到多实例,无中心化问题,因为 Redis Cluster 的数据分布策略是稳定不变的
可以集中支持 pipeline 等操作,也可以同时支持 memecache 等协议
这种和业务解耦的 Smart Proxy 模式被广泛的使用,当然代价是会增加分布式系统的复杂性,适合有明确团队分工的中大厂使用。
分布式特性
从单节点变成集群,分布式复杂性一下变高,有几个问题值得思考:
节点间的状态、槽归属、主从信息如何同步?
如何保证信息同步的可靠性?
第一个问题有个常规的解决方案,就是用一个状态同步服务进行统一管理,比如 zookeeper。所有节点将自己的状态上报 zookeeper 统一汇总,然后和各节点实时同步。
这种中心化的处理方式实时性、可靠性都较高,但引入了新的依赖点,依赖点本身的性能和可靠可能会引发新的问题。redis cluster 选择了实时性相对较低的去中心化方案。
信息的同步通过大概两种方式进行:
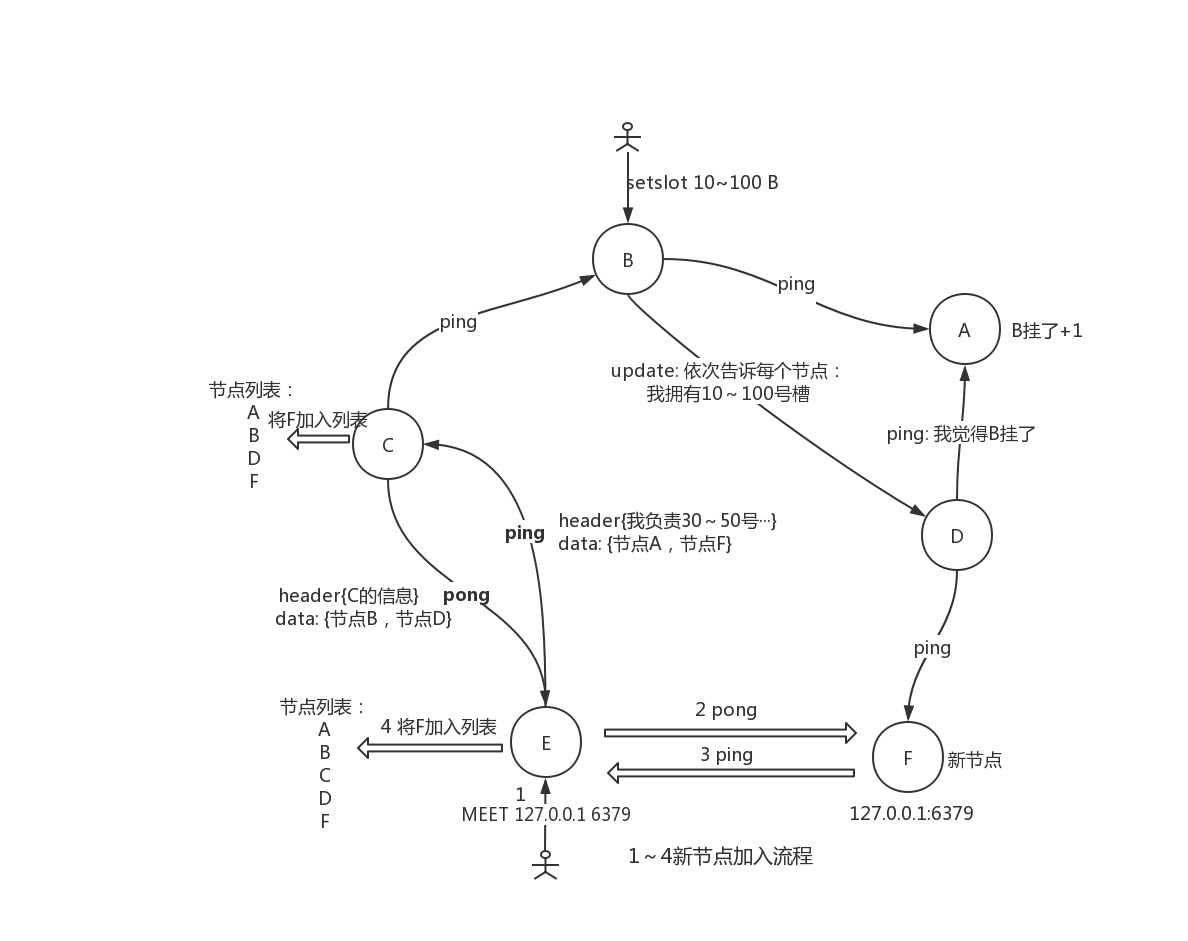
节点间定时 (clusterCron) 相互发送心跳包 (ping) 来探测健康度、发现新节点、交换信息等
全局广播 (遍历节点分别发消息) 来更新关键的信息 (槽归属变更、主从变更、节点故障、索取投票等)
定时任务每 100ms 执行一次,遍历所有节点,分别发送 ping 消息,消息体 (clusterMsg) 分为两个部分:
header, 包含节点自己的信息,自己负责的槽、名字、ip 端口、状态等等
消息体 (clusterMsgData), 在节点列表中随机选 1/10 个 (至少 2) 其他节点的信息 (ip 端口、名称、最近心跳时间等)
每个节点在收到 ping 后会回复 pong 消息作为回应,pong 消息体内容和 ping 消息类似,除了返回自己本身的信息,还会一些其他节点的信息,实现信息互换。
节点收到 ping 或 pong 消息后,会检查节点信息,如果没有和对应节点发生过链接,则会将其加到自己的节点列表中 (会去 ping)。这样便实现了节点自动发现,新加入的节点一会儿就可以被所有节点知道。
这种传播信息的方式被称作gossip协议。
union clusterMsgData { /*集群消息详情*/
/* PING, MEET and PONG */
struct {
/* ping/pong/meet 交换的节点信息放在这个数组中 */
clusterMsgDataGossip gossip[1];
} ping;
/* FAIL 谁挂了*/
struct {
clusterMsgDataFail about;
} fail;
/* PUBLISH pub/sub的支持*/
struct {
clusterMsgDataPublish msg;
} publish;
/* UPDATE 更新槽的归属 */
struct {
clusterMsgDataUpdate nodecfg;
} update;
};
typedef struct {
char sig[4]; /* Siganture "RCmb" */
uint32_t totlen; /* Total length of this message */
uint16_t ver; /* Protocol version, currently set to 0. */
uint16_t notused0; /* 2 bytes not used. */
uint16_t type; /* ping pong publish fail update 等几种 */
uint16_t count; /* Only used for some kind of messages. */
uint64_t currentEpoch; /* 当前节点的epoch,用作分布式环境一致性校验 */
uint64_t configEpoch; /* The config epoch if it's a master, or the last
epoch advertised by its master if it is a
slave. */
uint64_t offset; /* Master replication offset if node is a master or
processed replication offset if node is a slave. */
char sender[CLUSTER_NAMELEN]; /* Name of the sender node */
unsigned char myslots[CLUSTER_SLOTS/8]; /*一个bitmap记录当前负责的槽*/
char slaveof[CLUSTER_NAMELEN];
char notused1[32]; /* 32 bytes reserved for future usage. */
uint16_t port; /* Sender TCP base port */
uint16_t flags; /* Sender node flags */
unsigned char state; /* Cluster state from the POV of the sender */
unsigned char mflags[3]; /* Message flags: CLUSTERMSG_FLAG[012]_... */
union clusterMsgData data; /*集群消息详情*/
} clusterMsg; /* 集群消息*/
集群消息通过上面的两个结构体封装,clusterMsg 中:
clusterMsgData data 是集群消息详情,包含消息的内容
其他的就是消息的 header,主要包含发送者的信息
总结一下,信息通过集群消息进行同步,有两种形式:
ping/pong口口相传,信息像谣言一样在集群中一传十十传百。用于新节点发现、问题节点投票、主从关系、复制偏移量等等,实时性较低。
直接通知,遍历每个节点,依次通知。用于宣布新的槽归属、下线某个故障的 master 节点、slave 转为 master 等等,实时性相对较高。
集群的信息同步问题,通过 gossip 和直接通知的方式解决了。那么如何解决信息的可靠性呢?
假设 A 和 B 同时宣布自己负责 10~100 号槽,该信谁?
假设 C 的更新信息由于网络问题延迟到达了,是否会覆盖新数据?
在单机环境中,这个问题相对好解决,事件发生时取一个时间戳,数据以时间戳大为准。
但在去中心化的集群中,时钟无法保证同步。需要额外想办法解决,redis cluster 选择的方案是:逻辑时钟。
每个节点都有一个逻辑时钟,是一个整型数字。每当集群中有更新事件发生时这个时钟会加一,上文结构体中的 configEpoch 就是当前节点的逻辑时钟值,用来管理槽归属等事件。
每个节点收到其他节点的集群消息时,会去比对 configEpoch 的值。如果发送方的 configEpoch 大于本地的 configEpoch 值,说明有新的更新事件发生,则将发送方带来的数据更新到本地。
否则会忽略这条消息中的节点信息。
当某个节点要发送更新消息时,它会先将 configEpoch 更新,然后再发送集群消息,这样才会被其他节点认可。同样的策略在于 slave 提升为 master 时一样,不过用了另一个独立的逻辑时钟 currentEpoch。
由于新的 configEpoch 值是通过加一来创建的,这就必然导致多个节点持有的 configEpoch 会重复,导致无法判断事件的发生顺序。如果冲突的节点各自负责的槽完全不相关,那么不会出问题,但真实场景肯定会有重叠的情况。
为了解决这个问题,redis cluster 设计了一套算法来保证各个节点持有的 configEpoch 彼此唯一:
如果一个 master 节点发现其他 master 持有相同的 configEpoch。
并且此 master 逻辑上持有较小的 nodeID(字典序)
然后此 master 将自己的 currentEpoch 加 1,并作为自己新的 configEpoch。(自己检测,然后更新,在 ping 时会带出去)
如果更新后继续遇到重复的 configEpoch,那么重复走上面的逻辑,直到没有冲突。
槽迁移过程
当集群中新增一个节点时,首先通过 meet 让其被集群中其他节点发现并彼此相连。随后则需要迁移部分槽到新节点上,这涉及槽归属的变更,同时需要将此修改信息同步到各个节点,下面来看一下整个过程。
通过 redis-trib reshard 可以迁移部分槽到新的节点,假设实际上是从 A 节点迁移 10~100 号槽到新节点 B。
A 上槽 10~100 的状态设置为 MIGRATING
B 上槽 10~100 的状态被设置为 IMPORTING
通过 migrate 将对应槽中的 key 从 A 拷贝到 B
当槽迁移完毕后,会清除 A 和 B 的对应槽的迁移状态
B 在清除状态时,会发送 update 消息告诉其他节点新的槽归属(configEpoch 会更新),其他节点会更新状态,告诉 client 重定向到 B
如果在迁移过程中,client 对槽中的 key 发起请求:
迁移过程中,如果对应 key 还在 A 上,则 A 会正常处理。
如果 key 已经拷贝到 B,但还未迁移完毕,此时 A 会将 client 的请求临时重定向到 B(ASK 错误,表示 key 正在迁移到 B 节点)。
client 会向 B 节点发送 ASKING,随后发起向 B 发起重试
B 根据 ASKING 命令设置的状态,会处理对应 key(此时 B 还未清除 IMPORTING 状态)
当 A 和 B 都成功清除了迁移状态,还未更新状态的 client 会收到其他节点的 MOVED 重定向,client 记录本次重定向关系后,一切回复正常。
redis cluster 在这个地方有个 bug(本文基于 3.2 源码),在清除 A 和 B 的状态时,必须要先清除 B 的状态,让 B 先广播槽的归属,再清除 A 的状态。
如果 A 先清除状态,到 B 成功广播槽归属的这段时间内,槽的归属是混沌的。
A 会将请求重定向到 B,因为 A 知道槽已经迁移到了 B
B 会将请求重新重定向到 A(因为状态还未清除,未迁移完毕)
在这个短暂的间隙中,请求对应 key 的 client 会收到连续的重定向,导致报错。 redis-trib 脚本在清除状态时,有时会先清除 A 再清除 B,就会导致上面的问题。
故障转移
最后简单介绍一下故障转移,当某个 master 一下宕机了:
其他节点如何感知?
如何让对应 master 的 slave 接管?
节点间 ping/pong 会交换大概 1/10 的节点信息,信息中包含节点的状态。当节点 A ping 节点 B,但未在指定时间内得到回复时,A 就认为 B 疑似宕机了。
在 A 和 C 交换信息时,如果 B 在交换的节点列表中,那么 C 就会得知 A 认为 B 疑似宕机了,此时 C 会在自己本地记录中将 B 疑似宕机的计数加一。
B 疑似宕机的消息会在集群中慢慢传播开来,如果其他节点也发现 B 没有响应了,也会通过 ping 告诉其他节点。当某个节点 D 发现自己本地记录的 B 疑似宕机计数值>(集群节点数/2 + 1) 时 (计数有一个时效性),说明集群中一半以上的节点都认为 B 宕机了。
此时 D 会广播一个 fail 消息,正式公布 B 宕机的消息,B 对应的 slave 也会收到消息。
此时 B 的一个或多个 slave 会更具相应的算法计算优先级 (数据同步状态等),某个优先级高的 slave 会广播 CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST 消息,寻求各个 master 投票同意它成为新的 master(currentEpoch++)。
如果在当前 currentEpoch 内,有超过一半的 master 同意 slave 成为新的 master,那么这个 slave 就会做两件事:
标记前 master 的槽全部由它接管、设置自己为 master
将这个状态广播出去,实现故障转移
如果投票未能过半数,其他 slave 节点会继续重试,直到故障成功转移。client 和新的 master 建立新链接,服务恢复正常。
