本系列分为四大部分:
- gRPC 系列 (一) 什么是 RPC?
- gRPC 系列 (二) 如何用 Protobuf 组织内容
- gRPC 系列 (三) 如何借助 HTTP2 实现传输
- gRPC 系列 (四) 框架如何赋能分布式系统
前面的系列,我们已经从技术要素透视了 RPC 的本质,包括其三大要素:语义约定、网络传输、编解码。以及 gRPC 如何通过 Protobuf 和 HTTP2 实现这三大要素,并达到更低成本、更高效率、更高性能等终极目标。
本文我们将回归到 RPC 的使用场景:分布式系统。从分布式系统的角度,来看待 gRPC 这个框架。框架本身的含义就意味着是一个集成者、整合者,提供出简单、全面的使用界面,以灵活适应不同的环境,并对外屏蔽足够多的细节。
简单讲,框架的本质是技术落地的最后一厘米,为大规模低成本使用提供直接支撑。
分布式系统
现代技术架构,已经重构了众多场景的生产关系,一方面服务海量的用户,另一方面承载了无数极重要的业务,并要及时作出调整,以适应环境的变化。
这都使得技术系统,在保证灵活和效率的同时,还必须要有高度的稳定性和健壮性,任何一次故障都会带来难以估计的直接损失,还有背后商业上的信用本钱。
受限于现代计算机的技术特性,以及通信的基础设施。一个技术系统想要在大流量下保持高健壮性、高稳定性,必然要将代码和数据分散在数量庞大的机器上,这些分散的机器一起组成一个个闭合的技术系统,完整业务需求由这些系统一起合作分工实现,这样便诞生了分布式的概念。
分布式场景下,系统中的子系统或模块间需要相互通信,或传递信号,或传输数据。这就自然导致了 RPC 的诞生。这种通信场景可以简单分为三类:
- 集群间的通信。如 Redis 集群基于 gossip 的数据交换,一般直接基于 TCP,一般会收敛于子系统内部。
- 数据传输。应用读写 MySQL、Redis 等数据系统,一般直接基于 TCP,场景定制性高。
- 消息传递。微服务之间相互接口调用。这种偏上层业务,需要适应复杂繁多的场景,并提供高度的可复用性、适应性、扩展性。所以一般会基于 TCP 再做一层封装,如 HTTP2。
到此,我们可以从分布式系统的角度发现: RPC 是分布式系统通信的一种工具。
而 gRPC 则是这种分布式系统通信场景中,偏上层应用的一种通信工具,也就是上面的第 3 类,我们且称为业务型分布式系统。
本文将聚焦业务分布式系统通信场景来展开对 gRPC 的学习。
业务分布式系统
业务性分布式系统,可以对应于传统的单体应用。当一个单体应用以微服务或 SOA 等方式拆分后,就变成了一个分布式系统,这也是大中型互联网公司的后台系统。
为了从虚到实地落地知识,我们暂且简单地把业务性分布式系统等价于微服务系统,从微服务的角度来看待 gRPC,才算是真正将讨论点落实到了实际环境中。
实际上,gRPC 就是微服务类系统间通信的核心工具。到此,我们基本上将知识结构及相关关系梳理完毕,完成宏观和微观间的互通。接下来着眼于微服务系统的通信需求,看 gRPC 是如何为其赋能的。
所谓赋能,用人话来讲,就是能低成本大规模使用,一般就几个需求:
- 有良好的适应能力。对于部分核心能力可以通过插件实现定制化能力,适应不同的环境。
- 提供关键性问题解决方案。例如高效率的并发模型、加密、压缩等等。
- 有足够的扩展能力。能通过配置、注入等方式灵活实现扩展功能或开启部分功能。
- 足够简单。屏蔽底层细节,能无脑上手使用,不需要懂 http2、protobuf、IO 模型等等是什么
接下来我们就从以上几个点,来展开对 gRPC 的学习。由于框架庞大复杂,受限于作者水平和使用经验,讨论将聚焦于几个核心点展开。
业务系统的通信需求
分布式系统中服务的相互调用看似复杂,其实本质就是两个点间的点对点通信,点与点相互连接串起一张网。
点与点通信进一步拆解后,在微观可以分为调用方和服务方的关系,大部分情况下就是单向调用,在 stream 模式下可升级为相互调用,但每一次调用都不会逃离调用方和服务方两个角色。这为我们提供了很好的突破口,搞清楚了两点之间的调用,也自然能延伸全局。
当 A 要调用 B 时,问题就来了。
适应能力
服务发现
- A 要能得知 B 的可调用地址
- B 的部署方式可能多种多样
B 可能是以微服务的形式注册,通过注册中心可以拉到其节点列表,不同的公司注册中心实现也千差万别。但也可能是只暴露出了一个代理的地址 (如 Nginx/lvs),甚至实现了传统的 DNS 模式。
业务发展过程中什么情况都可能有,大概率是一个大杂烩。gRPC 作为一个落地的框架就必须要有足够的适应能力,覆盖繁杂的情形,通过提供自定义接入能力 (插件),以适应复杂的环境。
为此 gRPC 仿造 RFC 的标准设计了一套名称发现协议 [1],一个服务的标示可以表示如下:
scheme://authority/endpoint_name
- scheme 表示要使用的名称系统,例如 DNS,或一套自己的服务发现系统,例如 ectd、Eureka、consul,或任意自研服务发现系统的名字。
- authority 表示一些特定于方案的引导信息,例如对于 DNS,authority 可以提供一个解析 endpoint_name 的地址,相当于 DNS 服务器。(一般在 DNS 模式下才有用)
- endpoint_name 表示一个服务的具体名字。例如 login-service
例如使用 DNS 时,B 服务的地址可以设计为:dns://somedns.com/addrOfServerB,其内涵为B服务通过dns这种名称系统来发现,B具体的地址可以定时轮询somedns.com得知(带上参数addrOfServerB),实际请求发往解析得到的具体IP:port,这套机制即可满足上面我们说的暴露代理地址的模式。
而常规的微服务模式则是有一个服务注册中心,B 服务的实例启动后将自己注册到服务中心,调用方通过服务中心拉取到可调用地址。目前的技术现状是,每个公司都恨不得自己搞一套服务注册系统,而实际上这就是中大厂的现状。通过插件接入对接自己的服务发现系统是不可绕过的刚需。
假设我们这套服务注册中名字为 discovery,那 B 服务的地址也可以表示为:
discovery://someauthority/appID_B
B 服务的可用地址通过 discovery 来获取。具体怎么获取呢?gRPC 其实将这种能力完全外放了。提供了名称系统注册能力,实际上就是一个 interface:
type Builder interface {
Build(target Target, cc ClientConn, opts BuildOptions) (Resolver, error)
Scheme() string
}
// 注册一个名称系统
resolver.Register(&Builder{scheme: "discovery"})
向 B 服务发送请求前,会解析discovery://someauthority/appID_B出 scheme 的值,并用使用对应注册的名称系统来获取可调用的节点。相当于 gRPC 将这部分能力外放出去了。具体如何通过 appID_B 去获取可调用的地址列表,gRPC 不管,由使用方自己实现。当部署节点发生变化时,调用 gRPC 的接口 (NewAddress/UpdateState) 通知其即可。[2]
简单理解为以下过程:
- 注册一个名称系统的实例到 gRPC(一般启动时注册,可以注册任意数量)
- A 通过 gRPC 调用 B 时,gRPC 会解析出 B 的 scheme,从注册的名称系统获得可用的服务地址列表,一般是一批 IP:port(IP:port 如何得到 gRPC 不关心,使用方根据自身情况实现即可)
- gRPC 针对 IP:port 建立网络连接
- gRPC 将请求发出去,接收回复
通过上面的方式,使用方按照 scheme://authority/endpoint_name 定好服务名字,并实现相应的接口 (可调用地址的获取、变更等),注册到 gRPC,便可以适应复杂的分布式调用场景。
假设某个公司由于山头过多,实现了多个服务发现系统,短时间内还难以统一,服务分散注册到这几个系统。在用 gRPC 时,也能轻松应对。
服务注册现状:
discovery://someauthority/appID_B appID_B 通过自研discovery系统注册
etcd123://someauthority/appID_C appID_C 通过自研etcd123系统注册
consul456://someauthority/appID_D appID_D 通过自研consul456系统注册
启动时向 gRPC 注册名称系统:
import "google.golang.org/grpc/resolver"
resolver.Register(&Builder{scheme: "discovery"})
resolver.Register(&BuilderEtcd{scheme: "etcd123"})
resolver.Register(&BuilderConsul{scheme: "consul456"})
当 A 通过 gRPC 调用 B、C、D 时,会解析出 schema,从注册的名称系统来获取实际调用地址。调用示例 [3]。Resolver 实现示例 [4]。
负载均衡
上面解决了获取可调用地址的问题,紧接着问题又来了,如何做负载均衡?一批可调用的地址中,到底选哪个,怎么选?
常规的负载均衡算法非常多,如轮询、随机、耗时最短、加权随机等等,由于技术系统的异构性,很多时候难以简单随机轮询。gRPC 为了提供出足够强的适应性,把负载均衡的策略也外放了。使用者可以在启动时设置负载均衡的对象,通过插件可只定义策略。
type PickerBuilder interface {
// gRPC将建立好的所有连接传给负载均衡器,创建一个picker
Build(readySCs map[resolver.Address]balancer.SubConn) balancer.Picker
}
type Picker interface {
// 从gRPC给的连接中选一个可调用的节点返回给gRPC
Pick(ctx context.Context, info PickInfo) (conn SubConn, done func(DoneInfo), err error)
}
具体的实现相对简单:
- gRPC 会将封装好的网络连接丢给负载均衡对象,当连接变化时,由 PickerBuilder 新 Build 一个 picker。
- 每次调用前调用 picker Pick 一个节点出来供使用
- Pick 接口会返回一个 done 函数,rpc 调用完毕后会回调,支持回传一些 balancer.DoneInfo
- balancer.DoneInfo 里面支持一些 metadata,也就是服务方可以通过 HTTP2 的 header 回传的一些 key:value
- 服务方可以在返回请求时,将自己的 CPU、负载等反映压力的数据写到 metadata 中,这些数据可以通过 done 函数回写到 picker,供决策使用。
根据上面开放的能力,例如你可以实现一种叫 p2c 的策略 [5],先随机选择两个节点,然后根据记录的对端 CPU 负载等多种参数,最后选择一个最佳节点。这种相比轮询或随机具有更强的适应能力,可以避开部分出问题的节点。
总结下,gRPC 对于负载均衡提供了以下能力:
- 负载均衡策略外放
- 支持 done 回调,透传服务方的一些数据 (需要在服务方支持,通过 grpc.SetTrailer 写入流即可)
- 支持透传自定义命名系统回传的 metadata,这个里面可以携带众多信息,如权重等等。(resolver 包 struct Address)
基于这些特性,便可以自由实现花样百出的负载均衡策略。
整体结果简单示意图如下:
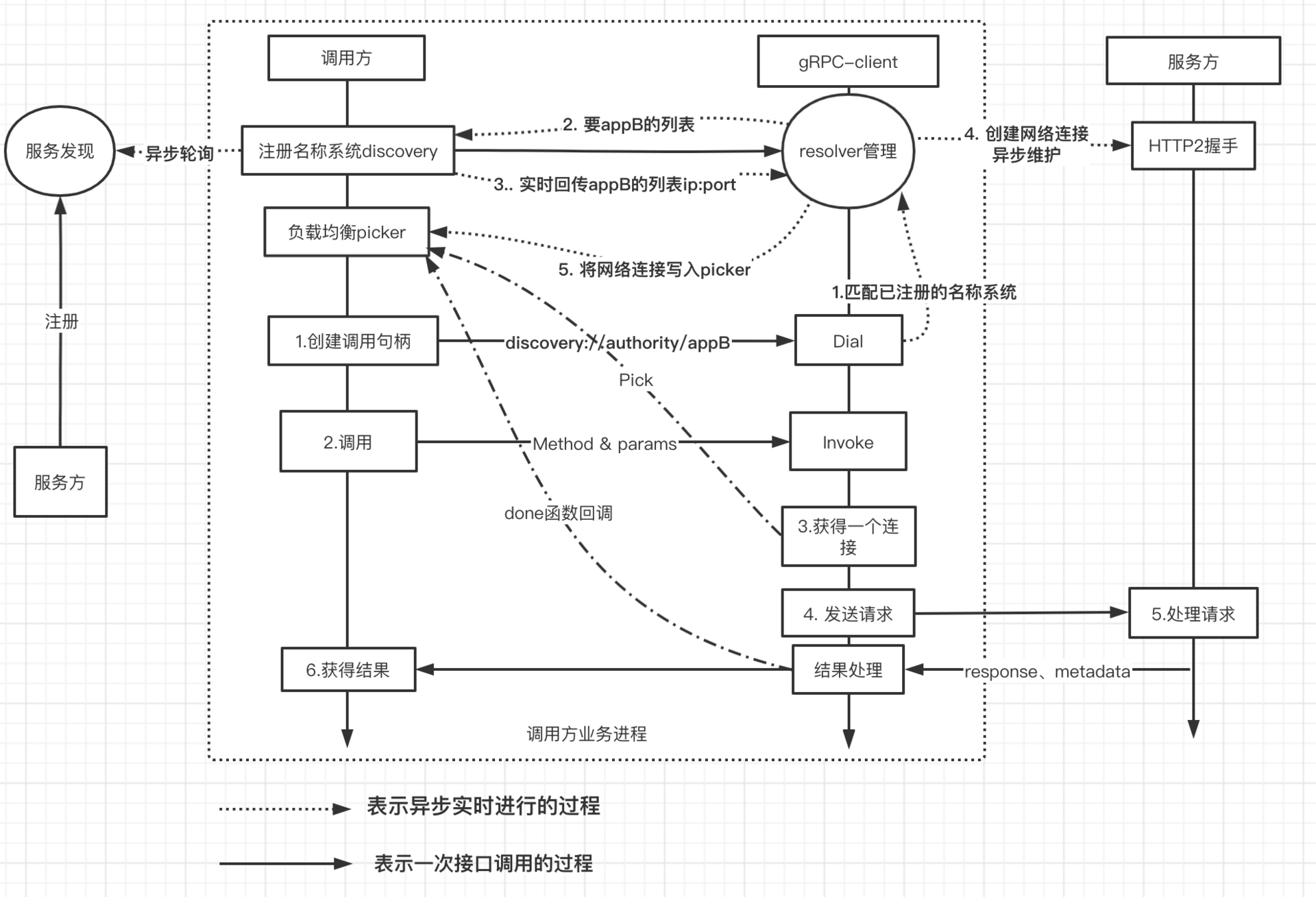
关键问题
框架在整合编解码、网络传输等 feature 同时,也需要提供部分核心功能,这些功能往往是系统刚需,存在重复劳动的地方。最常见的就是并发模型。
并发模型一般是针对服务方而言的,服务方需要有高效率的 IO,在资源有限的情况下一方面快速处理请求,另一方面提供足够高的并发能力,实现高吞吐低延迟。
这些都可以认为是 C10k 问题 [6] 的延伸。传统的服务方基于阻塞 IO 实现请求读写,这样一个线程/进程只能同时处理一个请求。当用户量暴增后,不能来一个请求就 fork 一个子进程或创建一个线程来处理,这样资源扛不住。
所以得有更有效率的策略,得让一个线程/进程能同时处理多个请求。这便诞生了多路复用 [7] 的需求。让一个线程同时监听多个 socket 的状态,谁就绪才处理谁,而不是依赖操作系统的接口直接 hang 住,白白浪费 CPU 时间。(select/epoll)
为了能实现高吞吐的目标,一方面要尽量减少在 IO 上的无效等待,另一方面要利用好多核。
- 要减少无效等待,最好的策略之一就是基于事件驱动。
- 要利用多核,就需要和 CPU 数量相匹配的线程数量来并发处理请求。同时尽量减少上下文切换
于是便诞生了大名鼎鼎的 Reactor 模型 [8],linux 环境下大量号称高并发 server 都是实现了 Reactor 模型,例如 java 系的 netty。
每一个好的 RPC 框架势必要提供高吞吐的并发模型,也就相当于实现 Reactor,屏蔽网络 IO 处理这堆复杂的细节,解决服务方高吞吐的刚需,让小白上手就能高并发。
在 golang 出现之前,大量的语言例如 Java、python、ruby 等的 rpc 框架都要自己实现 Reactor 模型实现高吞吐,这其实是应用层的重复劳动。golang 从语言层面下沉了类似的实现,通过实现 netpoller[9],让 golang 程序的网络 IO 读写规避掉无意义的等待,和上下文切换。简单讲就是几点:
- golang runtime 封装了非阻塞 IO,给应用程序暴露成阻塞 IO
- 当 goutouting 操作一个未就绪的 socket 时,操作系统会返回 error,runtime 会拦截这个 error,将该 socket 加入状态监听队列 (可以简单认为是一个 epoll),并将该 gourouting 挂起
- 当监听到对应 socket 可读/可写时,会将对应的 gourouting 找到并让其立即等待执行
- 第 2,3 步周而复始,从 gourouting 角度自己在操作阻塞 IO,然而并没有 CPU 时间浪费在等待上,也没有线程上下文切换
这样的结果就是 golang 的相关应用程序不再需要实现 Reactor 模型,来一个请求则创建一个 gourouting 去处理就行,这极大简化了并发模型。
扩展能力
了解一般框架的人都知道,有不少标配能力,以提供高度自由的扩展功能,一般通过几种方式提供:
1. 自定义插件
例如上面的服务发现、负载均衡。因为 gRPC 天然和 protobuf 绑定,谈到扩展插件,就不得不提及 gRPC 在编码层的解耦。
因为使用 protobuf 的前提是你得有对应的.proto 文件,这样才能进行编解码。但有些场景下,类似代理的角色没法持有所有的 proto,这便限制了下面的场景:
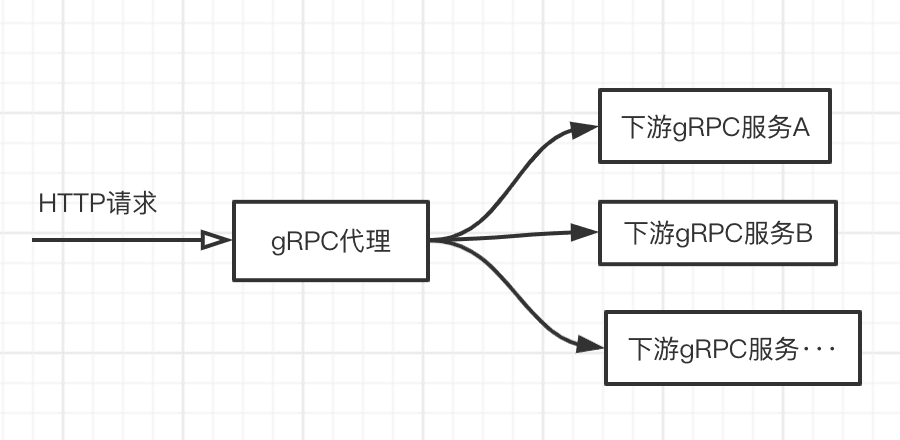
假设有一个 http 的场景需要调用 gRPC 的接口实现功能,这需要有一个近似透传的代理来实现,但都通过 protobuf 包装数据,代理则要持有所有下游的 proto 文件,这不现实。
但如果将编解码的方式解耦出来,例如通过 JSON 进行编解码,便能轻松解决问题,这带来了极大的灵活性。在 http 和 gRPC 的混用融合上价值不菲,而且 gRPC 请求的调用调试也可以像 http 那样简单。
gRPC 提供了 codec 的插件注入能力,以实现自定义编解码:
type Codec interface {
Marshal(v interface{}) ([]byte, error)
Unmarshal(data []byte, v interface{}) error
Name() string
}
// 注册一个编解码插件
import "google.golang.org/grpc/encoding"
encoding.RegisterCodec(JSON{}) // JSON实现了上面的interface
grpc.CallContentSubtype(JSON{}.Name()) // 通过option指定使用JSON
只要服务方也注册了,且下游参数能通过 json 反序列化成 struct 对象,则调用便顺利进行。
type Req struct {
Platform string `protobuf:"bytes,1,opt,name=platform,proto3" json:"platform" form:"platform" validate:"required"`
Build int64 `protobuf:"varint,2,opt,name=build,proto3" json:"build" form:"build"`
XXX_NoUnkeyedLiteral struct{} `json:"-"`
XXX_unrecognized []byte `json:"-"`
XXX_sizecache int32 `json:"-"`
}
2. 配置 - 调用时通过 option 注入
gRPC 可以通过 option 配置提供多种能力,例如:
- 自动重试。(RetryableStatusCodes)
- 加密
- 压缩
- 超时定制
3. 拦截器 (Interceptor),有些也称 middleware
拦截器可以在调用方和服务方同时存在。一般用来实现熔断、限流、日志收集、open-tracing、异常捕获、数据统计、鉴权、数据注入等等多种功能。可以一层包一层,支持任意数量。
插句题外话,上面大部分扩展能力一般是以 SDK 的方式独立于业务代码,但都是运行在同一个进程中。如果把上面分布式治理部分功能剥离出来集中治理优化,并和业务进程隔离部署,就是一个 ServiceMesh 落地雏型。
屏蔽细节
作为落地的最后一厘米,框架要尽最大能力屏蔽底层细节,特别是 HTTP2 相关细节:如何建立网络连接,如何发送数据,如何保持连接状态等等。gRPC 在这方面做得很好,使用方只需要注册实现几个接口,便可能无脑 run 起来。
以下是一个简单的 gRPC 核心对象关系图:
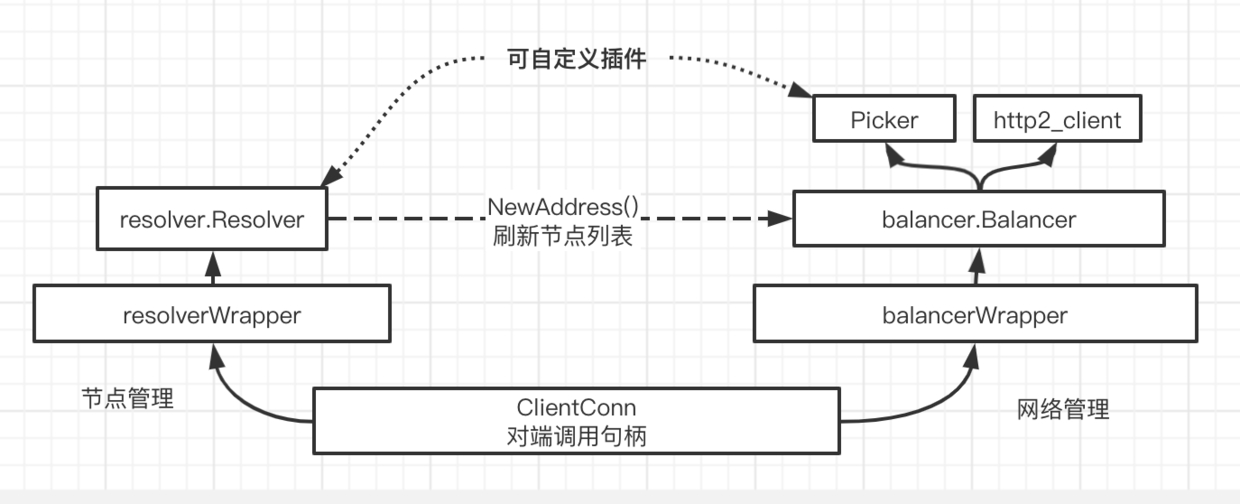
对于使用方而言,只需要实现 Resolver 插件提供可调用的列表,以及 Picker 如何选择节点的逻辑。其余复杂的状态管理、网络处理等等都被完全屏蔽。
开源参考资料
- [1] https://github.com/grpc/grpc/blob/master/doc/naming.md
- [2] https://github.com/grpc/grpc-go/blob/v1.35.0/resolver/resolver.go#L194
- [3] https://github.com/bilibili/kratos-demo/blob/master/api/client.go#L15
- [4] https://github.com/go-kratos/kratos/blob/v0.6.0/pkg/net/rpc/warden/resolver/resolver.go#L31
- [5] https://github.com/go-kratos/kratos/blob/v0.6.0/pkg/net/rpc/warden/balancer/p2c/p2c.go#L110
- [6] https://blog.csdn.net/chenrui310/article/details/101685827
- [7] https://draveness.me/redis-io-multiplexing/
- [8] https://tech.youzan.com/yi-bu-wang-luo-mo-xing/
- [9] https://morsmachine.dk/netpoller