直播是人类智慧的极佳体现,通过技术将模拟数据数字化,打破自然界光线和声音传播的刚性约束,实现隔空重放,让信息摆脱物理学的约束低成本传播,并自然地实现价值放大。
在手机 APP、浏览器等终端上,我们可以通过一个个窗口,便捷地看到那些隔空重放的信息,或一个鲜活的人或一场热闹的戏或一堆精美的物品,商业上的人、场、”货“都能在这个虚拟的载体上呈现。
这个载体我们一般称为直播间,或者叫房间。也引出不少耳熟的词汇,如进房间、出房间、开启房间等等。
直播的场景天然以人为核心,场由人造,“货”因人而存在,可以是商品、声音、荷尔蒙甚至陪伴。正因如此,业务上会想方设法围绕人营造热点,房间热度越高越好,影响力越大越好。通过热点房间连接到更多的人,多一双眼睛,就多一份价值。同时,基于人的内容天然会出现马太效应,大部分的流量因少部分人产生。
不管是自然属性还是人为干预,直播的业务都必然呈现显著的冷热分布。
业务爱热点、观众爱热点,几乎所有人都爱热点。除了做技术的小哥哥小姐姐。因为容易出问题啊。
热点
当下的技术系统之所以能为海量用户提供服务,其原因在于不同用户制造的访问压力,被技术系统分散在了不同的服务器之上。机器数量随着人 (数据量) 增加,只要访问压力和数据量能近似均匀地分摊到不同机器上,同时服务大规模的用户群体便不是问题。
但热点天然会打破这种规律,常规情况下数据分散存放于服务器之中,但当海量的用户访问同一份数据时,访问压力就会集中在某部分服务器之上,一旦超过服务器承受能力,业务便面临瘫痪的风险。
在直播业务中,房间信息则是热点中的重灾区,以下是一个业务依赖示意图:
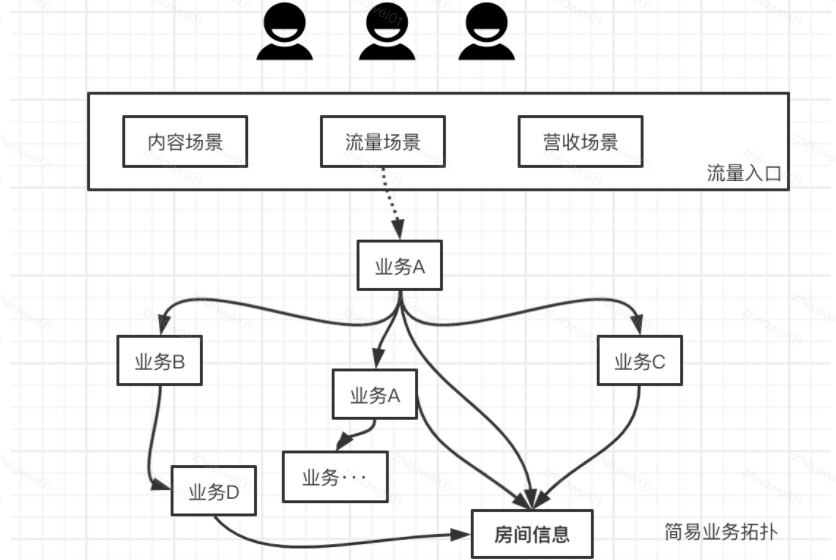
房间信息提供标题封面、状态、标签等一系列数据,在直播各个核心业务场景中,被广泛且深度依赖。一方面被众多业务场景强依赖,一旦房间信息故障,涉及的业务将直接不可用,典型的场景则是进房间,故障后房间内不可播放。另一方面会在业务流程中被依赖,在依赖链条中可能会被再次依赖。
这直接导致房间信息服务面临业务流量几倍~几十倍不等的请求数放大,在此基础上要保证足够的可用性。
例如刚刚过去的 S10[1],单房间动辄同时在线数百万。期间一个活动、一次开场背后都是热点流量洪峰。S10 房间在各个流量、业务场景中均可会露出,决赛期间房间信息 QPS 峰值达数十万,其中热点相关数据几乎可占到一半。
热点问题的本质在于,热点导致的访问压力没有被均匀地分散开,压力集中的情况下一旦洪峰足够强大,能轻易让服务瘫痪,而这不是简单堆机器所能解决的。
这需要房间信息服务,根据自身业务场景,设立一套能探测热点、解决热点的机制。
理论支撑
思考如何解决问题前,我们先来寻求一些理论上的参考,将知识串起来。
几乎所有的具体技术落地,都是以理论为根基,根据自身实际情况,综合成本及取舍来实现,方式途径千差万别,但万变不离其宗。理论给予我们两个作用:
- 提供设计思路,并奠定优化方向
- 提供一套框架去分析理解其它技术设计
CAP 定理是定位于分布式环境中,各个节点需要相互通信、相互分享数据的场景。于本文讨论的点有一定的相关性,或多或少我们能有所借鉴。
CAP 三大概念:
- C 一致性。对某个指定的客户端来说,读操作保证能够返回最新的写操作结果。核心:从客户端角度要求数据完全一致。
- A 可用性。非故障节点在合理的时间内返回合理的响应。核心:及时返回合理的数据 (不一定是最新的)。
- P 分区容忍性。当出现网络分区后,系统能继续提供服务。核心:在节点之间的数据拷贝和通信出现问题后,整个系统还能对外提供服务 (系统不瘫痪)。
CAP 定理很简洁,就是说分布式系统中 (节点相互通信、相互分享),只能同时保证以上两个。
由于分布式系统相互通信依赖网络,而网络不能保证绝对可靠,所以分布式系统时不时可能出现“分区”,也就是节点间相互通信失败。而在部分节点通信失败时,系统其实在正常工作。
也就是说分区容忍性天然存在,当分区发生时,系统天然可用。不管你愿不愿意,P 都已经给你选好了。所以接下来,系统要么是 AP,要么是 CP。为了一致性 C,当分区 P 时,需要禁止写入,所以 CP 牺牲了 A;为了可用性 A,当分区时,不同的节点数据会不一致,所以 AP 需要牺牲一致性。
以上是 CAP 理论的一些基本点,其存在前提是节点间存在相互通信拷贝数据,且数据可由多个节点吐出的场景。看着和一般业务场景有差异。当然这不重要,核心在于它能否给我们理论启发,并作出补充。
后来诞生的 BASE,也就是基本可用、软状态 (中间状态)、最终一致性,就是这样的存在,做了一个衍生和补充。AP 虽然牺牲了 C,但只要快速实现最终一致性,恢复正常后,系统其实同时提供了 C 和 A。
回到热点处理,当有热点洪峰时,系统核心关注点在于保证可用性,更关注 AP,牺牲一些一致性。而对于基础信息等非余额、库存等业务来讲,天然对一致性要求更宽松。所以可以得到理论上的指向:
- 对于非热点数据,可以通过扩容解决压力,正常情况下系统能同时保证 A 和 C。
- 对于热点数据,牺牲一定的一致性,以提升可用性,通过及时保证最终一致性,使得系统完全正常。
如何处理热点
通过上面的分析,我们可以知道,提升可用性可以通过牺牲部分一致性来实现。一致性问题的本质,就是数据有多个副本,且副本之间的数据没有做到及时同步。传统的 CDN 缓存和 Nginx 缓存,其实就是一致性换可用性,直接拷贝了一份数据。
有些暴力解决热点的办法,就是将数据拷贝多份,在读数据时随机获取其中一份,达到分散压力的作用。这种方法其实缺乏适应性,到底要设多少份拷贝才合理?如何降低设置多份拷贝的复杂性?如何保证最终一致性?对于这些问题稍微有些复杂。
更常规的做法是将热点数据探测到,只对热点数据做拷贝,再针对性处理,这样可以抵挡相当程度的流量,成本也可控。其分为两部分:
- 自动探测热点
- 将热点复制于内存中,并及时实现最终一致性
以房间信息逻辑与数据分离结构为例:
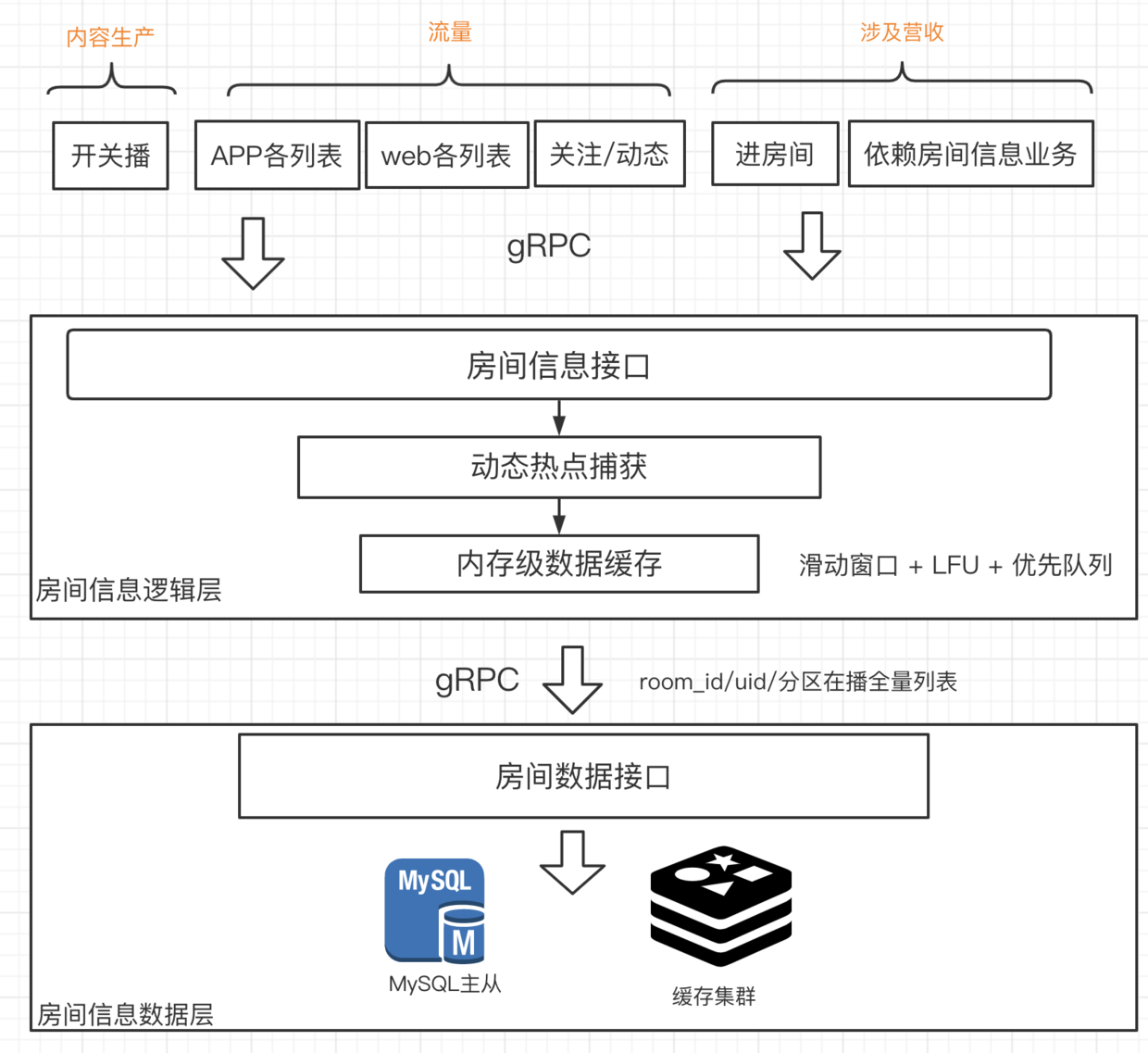
对于热点的探测及处理,可以在逻辑层、数据层两个地方做:
- 逻辑层。热点探测以房间 ID、主播 ID 为维度,同时处理数据。
- 数据层。热点探测以房间 ID、主播 ID、缓存 key 都可以,同时处理数据。
以 ID 为探测对象,需要在业务代码中埋点并进行缓存,对业务有一定的侵入。 以缓存 key 为对象则可以在缓存基础库中集成,可以做到对业务无感知。
如上图所示,我们选择了以 ID 为探测对象,并在逻辑层处理缓存。基本的考量点是保持逻辑和数据分离,在当下的团队成员和基础设施条件下,做到足够简单轻量。
自动探测热点
热点处理业界一般常见的有几种算法:
一、LRU。这是一个简单的栈结构,简单轻量。但本身无热点识别能力,在“SKU”较大的场景下很难起到作用。同时基于我们 ID 探测的策略,LRU 的使用需要下游数据层每次返回房间全量信息,这有极大成本。
二、LIRS[2]。这在内存缓冲淘汰场景被广泛使用,例如数据库中的 BufferPool,在缓冲空间有限的情况下,踢掉冷数据为热数据提供空间。可以认为 LIRS 是 LRU 的进进阶版本,能够提供适应性更好的热点识别和数据淘汰。其本身有一定的实现复杂度,同时和 LRU 一样,基于 ID 探测时,需要下游返回一份完整的数据。(有时接口只想读取房间标题)
三、LFU。简单版的 LFU 就是对被访问对象进行访问频次的计数,其本身可以基于访问次数来识别热点,但这种识别无法根据时间区间进行,并对“老热点”没有剔除的能力。当“SKU”非常大时,容易出现其他问题。
基于业务实际场景,我们选择了简易版的 LFU,并根据其缺陷,辅助以滑动窗口提供根据时间区间识别热点的能力,窗口的保持时间,也就是热点的探测周期,一次滑动对应一次热点结算和上报,结算时通过优先队列获取 Top-K。
总结下三个点:
一、LFU。用以简单统计访问 ID 的访问频次,在实现上核心是一个 HashMap 并辅以统计。针对 LFU 难以处理大规模”SKU“的情况,设计实现时会设置一个统计对象数上限,超过一定比例时会强制采样。(防止有 bug 把 hashMap 写爆了) (还未实现数据淘汰,目前只是一个简单的频率统计)
二、滑动窗口。滑动窗口的作用是辅以 LFU 实现基于时间区间的热点统计,并将结算、回调、数据上报等操作封装在窗口滑动流程之中。基于对房间场景时间区间内“SKU”的统计 + 分析判断 (脑拍),单次窗口保持时间是 3s,也就是说热点探测的反应时间最快是 3s。
三、优先队列。目的是以最快的速度在数万~数十万 SKU 中,计算出 Top-K。常规的全排序时间复杂度为 O(N*LogN)。优先队列的时间消耗:
- 1.构建大小为 K 的小顶堆,O(K) ;
- 2.遍历所有 SKU,尝试写入小顶堆,O(N)
- 3.如果小于小顶堆头部则丢弃,否则置换头部并重新堆话。O(log(K))
整体时间复杂度:O(K) + O(N*log(K)),当 K 最够小时,时间复杂度近似为 O(N)。
缓存与及时最终一致性
- 当探测到热点后,会基于热点 ID 在内存中构建数据副本,对于房间信息来讲就是全量字段 (数十个)
- 异步基于热点 ID,不断请求下游,刷新缓存数据,实现及时最终一致性。(周期、有效期均可实时由配置跳针)
- 业务接口根据 ID 优先从缓存副本中读取,miss 后才真正访问下游数据层。
- 热点的处理规则、刷新周期、有效期等通过配置实时干预
整体结构示意图:
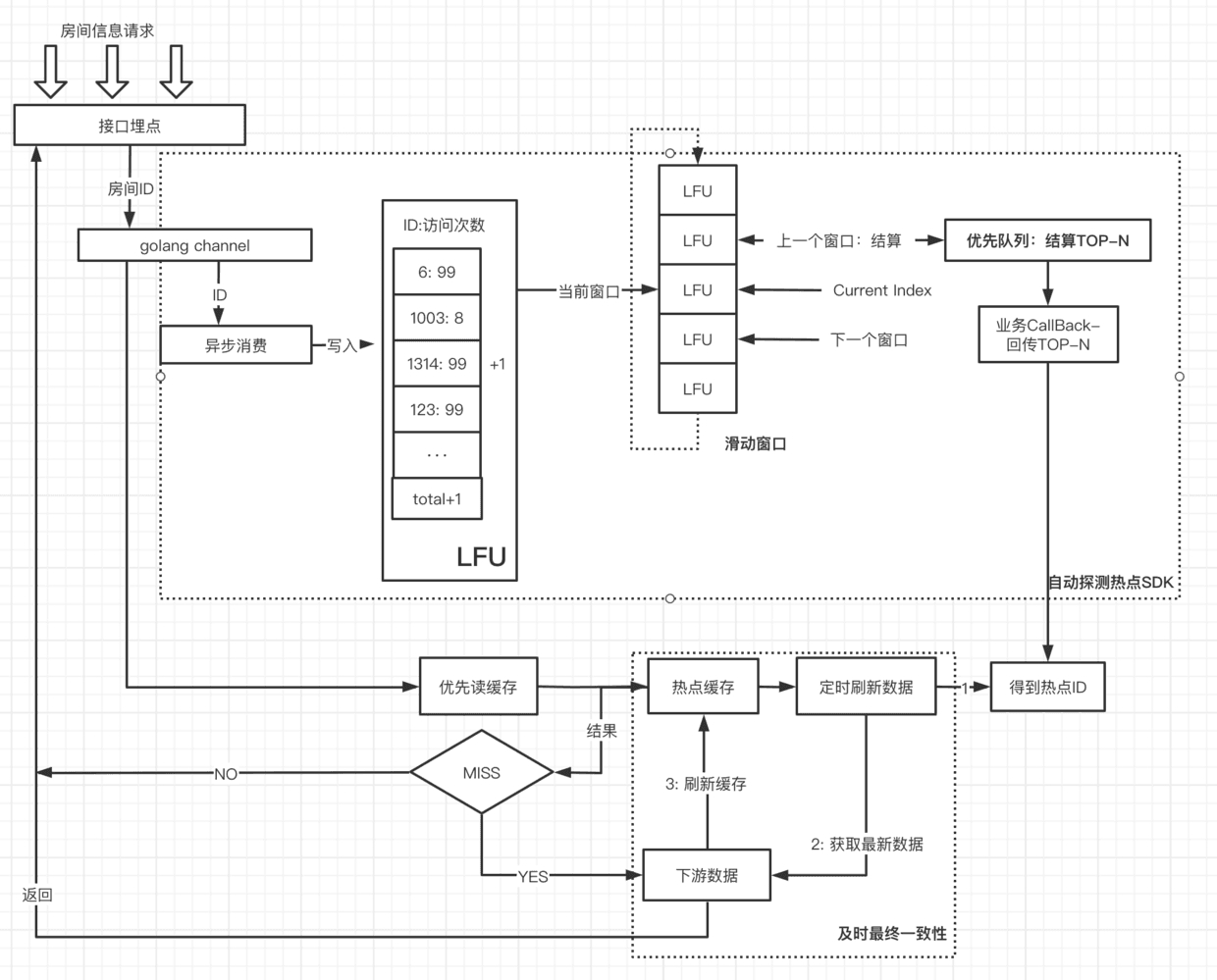
- 通过 SDK 集成热点探测能力,并通过业务回调,定时回传 Top-K 热点
- 业务根据 Top-K 热点对复制热点数据,并保证及时最终一致性
- 探测、热点处理均基于本地实例 (可以很便捷演进为分布式模式)
- 无任何外部依赖,轻量、简单、灵活性高、开发周期短、易于问题排查分析
实际效果
hits 为命中了缓存,miss 为未命中:

对集群整体压测时,下游数据层在 3s 左右后 (单实例探测周期为 3s),访问压力变成常数:
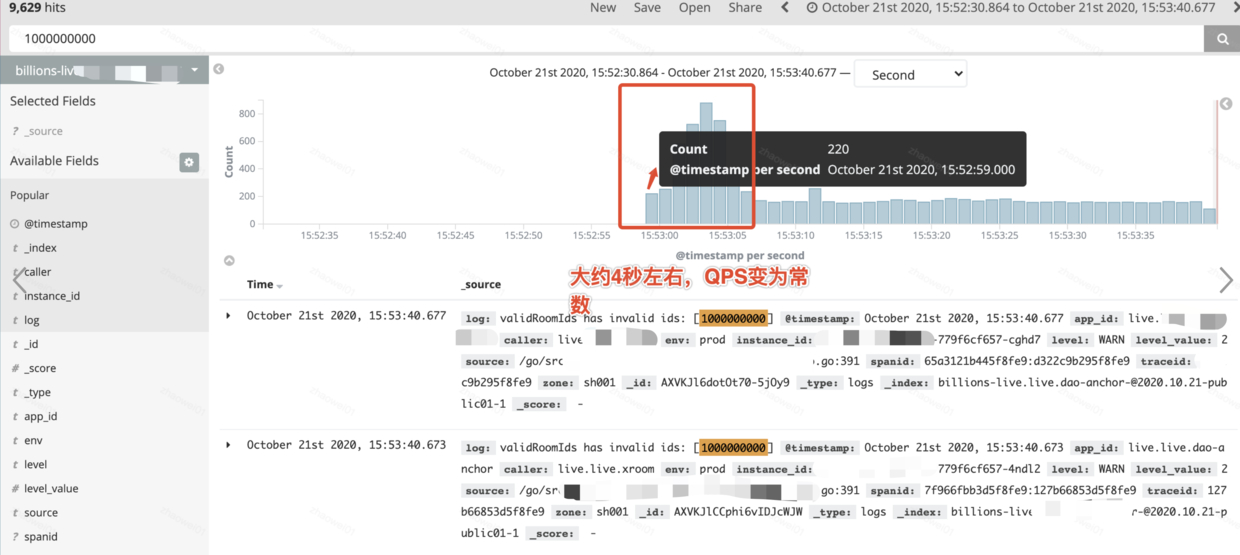
从业务表现和压测检验来看,热点探测让房间信息服务在热点洪峰下能对热点自适应探测,使得整体保持稳定。
场景分析
适用场景:
- 流量洪峰相对,例如压测场景,表现良好;间隔性脉冲访问效果差。
- 各个本地实例流量需近似均匀
- 中小型节点规模。
以上均暂时符合我们的场景。
不足
1)一致性的报复
当热点处理彻底消灭了热点问题时,另一个被忽略的场景则出现问题,可简单总结为时序性依赖:
- 房间信息变更 -> 消息队列投递消息(例如房间关播)
- 某业务消费消息
- 业务消费消息后立即调用房间信息 (根据开播状态中踢掉房间)
- 房间信息还未及时保证一致性 (房间状态还是开播中)
1~3 时间消耗大约在 10ms 以内,这是小于房间信息及时最终一致性周期的,也就是说在这种消息变更依赖场景下,房间信息的一致性未能满足需求。成也萧何,败也萧何。
为了解决以上问题,我们提出了几个解决途径:
- 消息投递时做一定延迟
- 时序性状态依赖的特殊场景 (量很小无热点问题),避开缓存
- 说服调用方不要时序型依赖 (理解业务)
2)复制成本稍高
以上基于 ID 探测的方案优点很明显,简单轻量无任何外部依赖。但其代价是业务有感知,并有一定份复制成本,无法无缝复制到其他业务场景中。
更理想的状态
技术的一般追求是,通过技术的方式降本提效,改善生产力,实现人肉不能实现的能力,并在此基础上提供近乎零成本的复制。
而具体的技术实现,则是在时间、成本、人力、场景、需求等综合因素作用下的产物,处于随时满足新的需求,并不断向往着理想的状态。
我们在心里默念理想的状态:
- 基于热点探测、及时最终一致性更加极致的实现
- 业务零感知、零耦合
- 近乎零的复制成本:无缝移植到其他场景
- 良好的适应性:灵活且符合大量场景的规则配置
这已经有开源方案作出了示例。[3]
应对攻击
暴露在公网的房间,极易被攻击或被爬虫遍历 (房间 ID/主播 ID)。这背后是热点攻击,热点处理能很好的应对,而暴力遍历攻击则相对令人头疼。
在被刷过数次后,房间信息也做了相应的策略应对。
非法 房间 ID 防御
由于房间 id 需要便于记忆,其生成规则是接近自增的,整体上房间 ID 的分布是接近连续的。此时业务上只要简单判断,请求中的 房间 ID 是否大于当前系统中最大的房间 ID,即可大致判断出该房间 ID 是否合法,将其以极低成本拒绝。
在房间服务中,定时获取当前最大房间 Maxid,并加入一定 buffer,当 requestId > Maxid + buffer 时,则直接丢弃。
非法主播 ID 防御
主播数量比较庞大,且增长区间跳跃、范围极广。对于房间信息来讲是一个无限集,无法像房间 ID 那样通过简单的策略做出判断。在面对大范围暴力遍历时面临挑战。
首先想到的策略是通过 bitmap 做映射,合法的 uid = 主播数 = 房间数,这是个有限集,将全量数据映射到 bitmap 中,如果某个 uid 在 bitmap 中无法找到映射,则可以肯定其不是主播,可以直接丢弃。 否则大概率是主播,因为 bitmap 长度问题,可能有些精度上的丢失,但不成问题。
布隆过滤器同理。
为何放弃 bitmap
在此想法的验证过程中,通过业界成熟且广泛使用的 RoaringBitmap[4] 进行落地,虽然其提供优异的压缩能力,在将所有主播写入时,对象的大小达到了数十 M,这对于要通过缓存系统加载到内存的对象来讲,太大了。如果进行分片,则 uid 的增量更新 (新增主播) 成本会变高,同时由于主播 ID 可能超过 32 位,这也超出了 RoaringBitmap 的范围 (32 位版本)。 (如果 uid 增量更新没处理好,新增主播会找不到自己房间,业务会受损,因为 uid 被当作非法丢弃了)
且在主播数量进一步扩张的未来,无法提供好的适应能力。这大块数据面临维护成本:
- 及时更新内存中的 bitmap,否则新增主播无法拿到自己房间
- 整块数据需要在实例启动时加载到内存,成本高
- 整块数据需要在缓存中及时维护一份全量数据,可靠性不高。一旦数据丢失全量构建一次成本很高
如果基于分布式缓存维护 bitmap,可解决一部分问题,但其性价比则极剧下降。基于以上分析,bitmap 方案带来的工程上的隐患稍显棘手。 (布隆过滤器同理,且多份 bitmap 成本更高。)
惹不起就躲
基于业务场景,我们选择了更加低成本的方案:
- 隐藏部分通过主播 ID 获取房间信息的入口 (通过合法服务端调用)
- 限制部分通过 uid 获取房间信息的能力
这其实更加简单地解决了问题。
总结
从面临问题时的焦躁,到一步步抬起锄头东闯西撞地作出尝试,再到问题的基本解决。从名义上可美化为演进或迭代,但站在终点边缘回看,这都不是最佳的解决方式。往往在日常中,很多场景更喜欢有相关经验的人,因为他们见过做过,能更容易有基于记忆的一顺而下的解决方案。但又有谁能拥有足够多的经验呢?在变化中的行业能瞬间让经验作为过去时,这并不能意味着有解决问题的增量。
更加合理的方式是,关注到问题的本源,通过理论知识的推导,得出大致解决思路及尝试方向。在此基础上通过对技术要素的组合,构建解决问题的方案。这才是更快速解决问题的途径,并具备解决经验之外问题的能力。这背后需要做两个事情:
- 关注问题的本源,寻求理论知识疏导、拆解、归类等
- 积累足够丰富的技术要素。算法、数据结构、以及更朴素的计算机思想 (如时空互换、批处理等)
这是姿势的大改造。
代码实现
精简版可见: https://github.com/EarlyZhao/hotDetect