-
Ruby ETL 工具漫谈 at May 16, 2016
-
Mongoid Paging and Iterating Over Large Collections at May 09, 2016
#1 楼 @adamshen find each 只适合按主键序的查询,如果加一个 order 就不灵了。 http://use-the-index-luke.com/no-offset 这篇文章提供的 keyset pagination 方案其实很不错了。 ruby gem:https://github.com/glebm/order_query
-
TIOBE 2016 年 5 月 Ruby 又爬上去了 at May 09, 2016
一直不明白 TIOBE 的数据来源根据是什么...
-
[转载] 元编程之重写 will_paginate at May 09, 2016
-
Not All Migrations are Equal: Schema vs. Data at May 07, 2016
#1 楼 @ibachue 虽然没用过,但看了一下文档,应该和这个帖子讨论的不是同一个问题...
reversible 解决的问题是 reversible schema migration 的写法问题,如果没有 reversible,你的这段代码应该等价于:
class SplitNameMigration < ActiveRecord::Migration def up add_column :users, :first_name, :string add_column :users, :last_name, :string User.reset_column_information User.all.each do |u| u.first_name, u.last_name = u.full_name.split(' ') u.save end revert { add_column :users, :full_name, :string } end def down revert {add_column :users, :first_name, :string} revert {add_column :users, :last_name, :string} User.all.each do |u| u.full_name = "#{u.first_name} #{u.last_name}" u.save end add_column :users, :full_name, :string end end其实这是一个很好的反例...本质上还是开头提到的
Bad Schema Migration。因为你用了 change 这个 api,data migration 和 schema migration 混合的时候就必须引入 reversible 机制。但如果深究这种混合写法的问题呢,还可以发现,如果 User 表大一些呢,这时候 schema migration 就会卡住,后面的 schema migration 一直在等待。这时候 schema 迁移了一半,然后在中间在跑一个耗时的 task,你的 App 是继续运行呢还是要停下呢。data migration 分出来的话就不会出现这种问题。 -
zeromq 作者的遗言 at May 05, 2016
还以为 zeromq 的作者是 zed shaw 呢
-
大量网站易受 ImageMagick 漏洞影响 at May 05, 2016
/etc/ImageMagick/policy.xml 加上这个就可以了吧?还有,这文章标题翻译的...
<policymap> <policy domain="coder" rights="none" pattern="EPHEMERAL" /> <policy domain="coder" rights="none" pattern="URL" /> <policy domain="coder" rights="none" pattern="HTTPS" /> <policy domain="coder" rights="none" pattern="MVG" /> <policy domain="coder" rights="none" pattern="MSL" /> </policymap>updated,最新 9 条 policy:
<policymap> <policy domain="coder" rights="none" pattern="EPHEMERAL" /> <policy domain="coder" rights="none" pattern="URL" /> <policy domain="coder" rights="none" pattern="HTTPS" /> <policy domain="coder" rights="none" pattern="MVG" /> <policy domain="coder" rights="none" pattern="MSL" /> <policy domain="coder" rights="none" pattern="TEXT" /> <policy domain="coder" rights="none" pattern="SHOW" /> <policy domain="coder" rights="none" pattern="WIN" /> <policy domain="coder" rights="none" pattern="PLT" /> </policymap> -
通过 Nginx 启用 HTTP/2 at April 29, 2016
注意:HTTP/2 得在 HTTPS 下面工作,虽然 HTTP/2 本身可以在非 HTTPS 下面工作,但目前还没有浏览器支持!
是说目前用 HTTP2 的前提是必须全站 HTTPS 吗?
-
统计平台思路分析 at April 18, 2016
可能对 Real Time 的理解不一样吧,比如 GA 就不算是 Real Time 类型的应用,因为虽然查询结果是实时出来的,但结果和插入的 event 之间有延迟,并不能马上看到真实的数据结果。而 GA 的 real-time report 那部分算是真的 Real Time,因为你访问就可以在 real time report 里看到在线人数的增减。
Hive,没有行级的插入删除更新操作,只能 batch insert。理论上,基于 hadoop 的都不适合做 real-time 分析,hadoop 其实是做 offline, batch processing 的……
Elasticsearch 查询速度确实很快,但插入速度是硬伤。
这有一篇 Metabase 写的 Data Warehouse 选型的文章,优缺点分析的非常详细:「Which data warehouse should you use?」
-
统计平台思路分析 at April 18, 2016
其实统计分析相关的工具非常多:
- Druid
- Elasticsearch
- HBase
- Cassandra
- Redshift
- Spark
- SQL-on-Hadoop (Hive/Impala/Drill/Spark SQL/Presto)
- InfluxDB
- PipelineDB
- Statsd
- Citus
- Greenplum
- Infobright
但最重要的是把业务边界搞清楚:
1.是否 Append Only 类型,就是说数据插入之后是否会变化,比如订单表创建之后状态会变、total 会变(有退款和取消业务),而日志分析和运维数据统计之类业务只是简单的 Append,相对来说简单,选择性就大一些,InfluxDB、Pipelinedb、statsd 什么的一堆
2.如果是有 Real Time 需求的话,选择性就又小了一些,Hive、Elasticsearch 什么的就要排除了,当然也看数据量。
3.如果有缓慢变化维度需求,就是一个数据仓库业务了。可能下面链接你会需要:
- https://ruby-china.org/topics/25115
- https://ruby-china.org/topics/25116
- https://ruby-china.org/topics/25145
4.是否需要 ad hoc 查询,如果需要,像使用 Redis 预聚合这种方案就得排除了 5.是否使用 SQL,基于 SQL 语言有天生的优势,像 Elasticsearch 这种自己造一个难用的 DSL 真是害人啊 6.这点应该和 4 是一起的。是否需要 JOIN,不基于 SQL 的工具其实大部分也不支持 JOIN,但对业务复杂的情况没有 JOIN 并且需要 Ad Hoc Query 就会死的很惨。
-
使用 Upstart + Inspeqtor 管理你的 Sidekiq (监控、崩溃自动重启、邮件通知) at April 18, 2016
很好!
-
Sequel 在做纯 API 项目时是不是比 ActiveRecord 更有优势? at April 11, 2016
#10 楼 @huacnlee 不能这么比吧,其实核心维护者只有一个人更能说明 Sequel 的设计好:
- Sequel 一直是 0 issue 的:https://github.com/jeremyevans/sequel/issues
- AR3 之后,大部分特性其实是从 Sequel 借鉴来的:http://twin.github.io/activerecord-is-reinventing-sequel/
PS. 其实没有实际项目中用过 sequel......
-
ActiveRecord 用 bulk_insert 来批量插入数据,提高效率 at April 07, 2016
-
ActiveRecord 用 bulk_insert 来批量插入数据,提高效率 at April 07, 2016
-
REST 架构风格的优势是什么呢? at April 03, 2016
REST 其实无非两点:
- 傻 x 的开发者们,你们不要瞎弄了,大部分场景我在协议层已经设计好了!我给你讲讲我是怎么设计的:这里省略一百万字。
- 你要是按照我协议设计来,和 Proxy(正向、反向)沟通的会更友好!
-
[北京][持续招聘呀.....] (玎少说,只要你敢来,我们就敢留) 来自新一代数据分析产品 GrowingIO 对 Ruby 工程师的邀请 (20K - 40K) at March 31, 2016
路过,跪一下 (ง •̀_•́)ง
-
[杭州] 天车诚聘 (服务端、客户端) 靠谱青年——技术大咖请关注 at March 24, 2016
-
[北京] 白帽汇招工匠 at March 24, 2016
用 Ruby 做什么
-
Sunspot 查询的时候说配置选项错误 请教各位大神了 at March 24, 2016
-
[北京] AKESO 艾索健康科技诚聘 1 名 Ruby 工程师 at March 22, 2016
#2 楼 @cassiuschen 确实像臭豆腐😨
-
[北京] AKESO 艾索健康科技诚聘 1 名 Ruby 工程师 at March 22, 2016
食物不错 (ง •̀_•́)ง
-
异步定时任务 Sidekiq Whenever 问题 at March 21, 2016
-
经验:如何正确的使用开源项目 at March 18, 2016
-
经验:如何正确的使用开源项目 at March 18, 2016
-
如何劝说别人使用英文资料? at March 14, 2016
招聘的时候就考察一下英文啊!
-
GIT 之我见 - 反驳 TW 洞见《GITFLOW 有害论》 at March 11, 2016
果然没有头像的人发的东西不能看
-
Ruby 2.0.0, 2.1 将不再支持了哦 at February 27, 2016
-
Ruby 2.0.0, 2.1 将不再支持了哦 at February 27, 2016
#9 楼 @imwildcat newrelic 啊
-
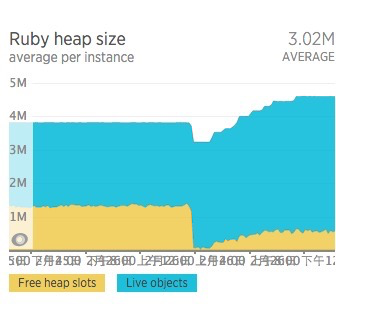
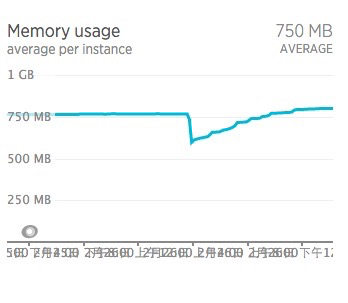
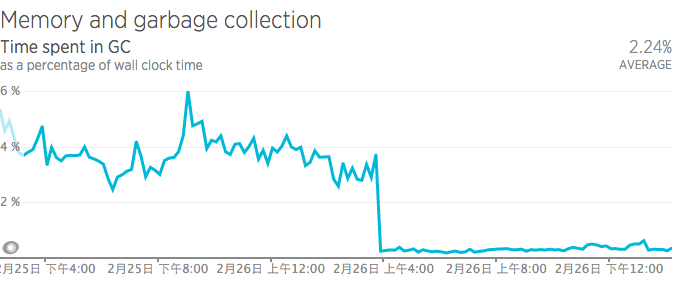
Ruby 2.0.0, 2.1 将不再支持了哦 at February 27, 2016
从 Ruby 2.1 升级到 2.2 发现 GC 时间降下来了,但内存使用升高了。。。