activewarehouse-etl
ActiveWarehouse ETL 应该是最早的 Ruby ETL 工具,并且十分强大,支持各种应用场景,但缺点是年久失修,没有再维护。ActiveWarehosue ETl 目标是解决全部 ETL 相关的需求,是一个重量型工具,一般新的 ETL 工具的功能很少是他没有的,但其内部结构十分复杂,并且依赖 ActiveRecord。另外一个缺点是,其支持的 Source 和 Destination 太过老旧,比如,对 Postgresql 不友好。
kiba
Kiba 是 ActiveWarehouse ETL 的维护者新开发的一个 Gem,与 ActiveWarehouse ETL 恰恰相反,Kiba 是一个轻量级的 ETL 工具。目前非常活跃,文档丰富,并且确实很轻,几百行代码勾勒出 ETL 的基本结构。但缺点呢,也很明显,它空无一物,什么都没提供,就是说,如果你的项目想用 Kiba 来解决实际 ELT 问题还差很远,需要自己去实现很多功能,如果不是很熟悉,要踩的坑还很多。另外,Kiba 和 Sidekiq 一样,提供 Kiba Pro,收费版,据说功能很多,支持以下特性:
- multi-threading (and later, multi-machines) - commonly requested
- built-in sources/transforms/destinations for common tasks lookups
- upserts / bulk load modules
- connectors optimized for parallelism (HTTP pagination extraction)
- connectors for the cloud (RedShift, ...)
- built-in helpers for common operations (debugging, limiting, caching...)
- premium support
ETL
ETL 是 Square 公司开源的一个轻量级的 ETL gem,与 ActiveWarehouse ETL 不同的是,Square ETL 直接操作 SQL,不依赖 ActiveRecord。但可能只是解决 Square 公司的特定问题,目前只支持的是 MySQL Source 和 Destination,并且 Source 和 Destination 必须在同一个 Server 上。另一个致命的缺点是不支持增量更新:
embulk
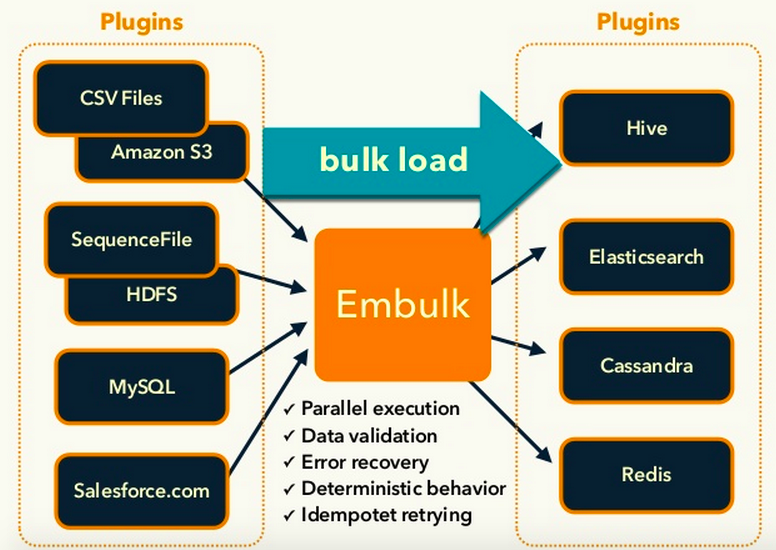
Embulk 的特点是其丰富的插件和并行处理能力。但其依赖 JRuby 和 Java 让 Ruby 开发者上手很难,并且其体系相当复杂,如果不是数据量巨大就不用考虑了。
kiba-plus
Kiba Plus 是一个基于 Kiba 的增强,包含常用的 Source 和 Destination 实现,例如 MySQL、Postgresql、CSV 等。它具有以下优点:
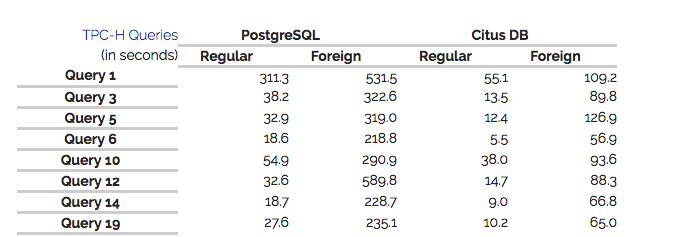
- 支持 Postgresql:其实支持 Postgresql 也就意味着很容易支持基于 Pg 的其他数据库,比如 Greenplum、CitusData、Redshift 等。题外话,MySQL 和 Pg 在 OLTP 领域可以说不相上下,但在 OLAP 领域 MySQL 已经被 Pg 甩出一条街了,支持 Pg 意义重大。
- Fast Load && Insert:由于不依赖 ActiveRecord 和 Sequel 之类 ORM 工具,直接使用 mysql2 和 pg gem 操作 SQL,能够利用更多数据库自身特性,比如 streaming 和 mysql load infile or pg copy 来更快的读取和插入。
- Incremental Insert:增量更新是 ETL 中不可缺少的部分,如果没有增量更新,即使再快的插入速度和再强的并行处理能力,随着数据量增长,也不可能每次把所以数据都重新插入一遍。
一个从 MySQL 导入到 Pg 的例子:
require 'kiba/plus'
SOURCE_URL = 'mysql://root@localhost/shopperplus'
DEST_URL = 'postgresql://hooopo@localhost:5432/crm2_dev'
source Kiba::Plus::Source::Mysql, { :connect_url => SOURCE_URL,
:query => %Q{SELECT id, email, 'hooopo' AS first_name, 'Wang' AS last_name FROM customers}
}
destination Kiba::Plus::Destination::PgBulk2, { :connect_url => DEST_URL,
:table_name => "customers",
:truncate => true,
:columns => [:id, :email, :first_name, :last_name],
:incremental => false
}
post_process do
result = PG.connect(DEST_URL).query("SELECT COUNT(*) AS num FROM customers")
puts "Insert total: #{result.first['num']}"
end
执行:
bundle exec kiba customer_mysql_to_pg.etl
输出:
# I, [2016-05-16T01:53:36.832565 #87909] INFO -- : TRUNCATE TABLE customers;
# I, [2016-05-16T01:53:36.841770 #87909] INFO -- : COPY customers (id, email, first_name, last_name) FROM STDIN WITH DELIMITER ',' NULL '\N' CSV
# Insert total: 428972

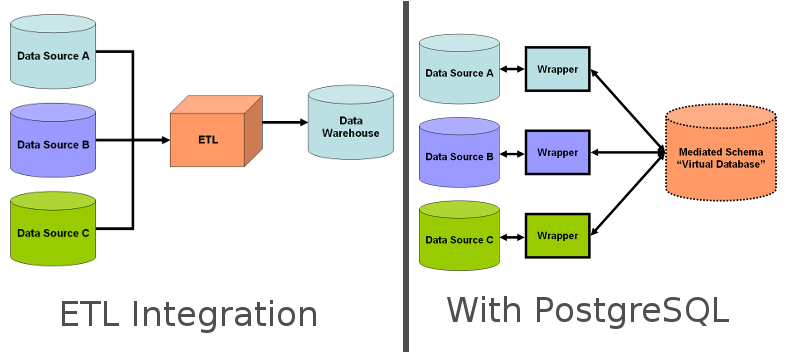 但我觉得像上面图中想用 FDW 替代 ETL 的想法在目前根本行不通,原因是:
但我觉得像上面图中想用 FDW 替代 ETL 的想法在目前根本行不通,原因是: