Rails Mongoid Paging and Iterating Over Large Collections
Mongoid Paging and Iterating Over Large Collections
遍历数据库中的所有记录时,我们首先想到的是Model.all.each。但是,当数据量很大的时候(数万?),这就不怎么合适了,因为Model.all.each会一次性加载所有记录,并将其实例化成 Model 对象,这显然会增加内存负担,甚至耗尽内存。
对于ActiveRecord 而言,有个find_each专门解决此类问题。find_each底层依赖于find_in_batches,会分批加载记录,默认每批为 1000。
对Mongoid而言,话说可以直接用Person.all.each,它会自动利用游标(cursor)帮你分批加载的。不过有个问题得留意一下:cursor有个 10 分钟超时限制。这就意味着遍历时长超过 10 分钟就危险了,很可能在中途遭遇no cursor错误。
# gems/mongo-2.2.4/lib/mongo/collection.rb:218
# @option options [ true, false ] :no_cursor_timeout The server normally times out idle cursors
# after an inactivity period (10 minutes) to prevent excess memory use. Set this option to prevent that.
虽然可以这样来绕过它 Model.all.no_timeout.each,不过不建议这样做。另外默认的batch_size不一定合适你,可以这样指定Model.all.no_timeout.batch_size(500).each。不过 mongodb 的默认batch_size看起来比较复杂,得谨慎。(The MongoDB server returns the query results in batches. Batch size will not exceed the maximum BSON document size. For most queries, the first batch returns 101 documents or just enough documents to exceed 1 megabyte. Subsequent batch size is 4 megabytes. To override the default size of the batch, see batchSize() and limit().
For queries that include a sort operation without an index, the server must load all the documents in memory to perform the sort before returning any results.
As you iterate through the cursor and reach the end of the returned batch, if there are more results, cursor.next() will perform a getmore operation to retrieve the next batch. )
Model.all.each { print '.' } 将得到类似的查询:
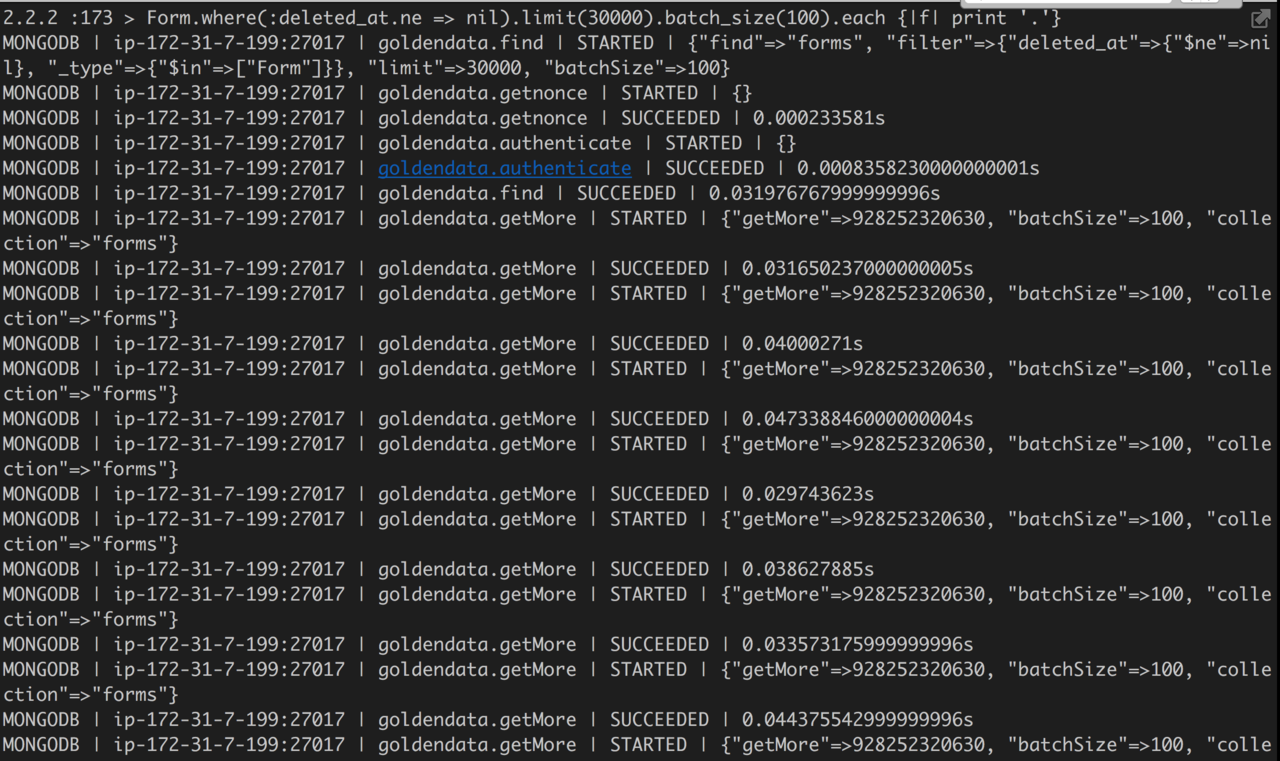
类似的方案应是利用skip和limit,类似于这样Model.all.skip(m).limit(n)。很不幸的是,数据量过大时,这并不好使,因为随着 skip 值变大,会越来越慢(The cursor.skip() method is often expensive because it requires the server to walk from the beginning of the collection or index to get the offset or skip position before beginning to return results. As the offset (e.g. pageNumber above) increases, cursor.skip() will become slower and more CPU intensive. With larger collections, cursor.skip() may become IO bound.)。这让我想起了曾经看过的帖子will_paginate 分页过多 (大概 10000 页),点击最后几页的时候,速度明显变慢,大致原因就是分页底层用到了offset,也是因为 offset 越大查询就会越慢。
让我们再次回到ActiveRecord的find_each上来。Rails 考虑得很周全,它底层没利用offset,而是将每批查询的最后一条记录的id作为下批查询的primary_key_offset:
# gems/activerecord-4.2.5.1/lib/active_record/relation/batches.rb:98
def find_in_batches(options = {})
options.assert_valid_keys(:start, :batch_size)
relation = self
start = options[:start]
batch_size = options[:batch_size] || 1000
unless block_given?
return to_enum(:find_in_batches, options) do
total = start ? where(table[primary_key].gteq(start)).size : size
(total - 1).div(batch_size) + 1
end
end
if logger && (arel.orders.present? || arel.taken.present?)
logger.warn("Scoped order and limit are ignored, it's forced to be batch order and batch size")
end
relation = relation.reorder(batch_order).limit(batch_size)
records = start ? relation.where(table[primary_key].gteq(start)).to_a : relation.to_a
while records.any?
records_size = records.size
primary_key_offset = records.last.id
raise "Primary key not included in the custom select clause" unless primary_key_offset
yield records
break if records_size < batch_size
records = relation.where(table[primary_key].gt(primary_key_offset)).to_a
end
end
前面的Model.all.no_timeout.batch_size(1000).each是 server 端的批量查询,我们也可模仿出 client 端的批量查询,即Mongoid版的find_each:
# /config/initializers/mongoid_batches.rb
module Mongoid
module Batches
def find_each(batch_size = 1000)
return to_enum(:find_each, batch_size) unless block_given?
find_in_batches(batch_size) do |documents|
documents.each { |document| yield document }
end
end
def find_in_batches(batch_size = 1000)
return to_enum(:find_in_batches, batch_size) unless block_given?
documents = self.limit(batch_size).asc(:id).to_a
while documents.any?
documents_size = documents.size
primary_key_offset = documents.last.id
yield documents
break if documents_size < batch_size
documents = self.gt(id: primary_key_offset).limit(batch_size).asc(:id).to_a
end
end
end
end
Mongoid::Criteria.include Mongoid::Batches
最后对于耗时操作,还可考虑引入并行计算,类似于这样:
Model.find_each { ... }
Model.find_in_batches do |items|
Parallel.each items, in_processes: 4 do |item|
# ...
end
end