分享 Data Warehouse Concepts and Overview
数据仓库
按照 W. H. Inmon,一位数据仓库系统构造方面的大神的说法,“数据仓库是一个面向主题的、集成的、时变的、非易失的数据集合,支持管理决策制定”。数据仓库的目的是构建面向分析的集成化数据环境,为企业提供决策支持。
除供企业内部使用外,像 Google Analytics 和淘宝数据魔方等提供继承数据和多维分析的应用也属于数据仓库类型。

事实和度量
事实(Fact)是可以被量化的最详细的业务信息。例如:一次网站的点击;购物网站上一个客户的一次购买行为;Github 上一个程序员的一次提交。我们可以量化下面的数据:
- 网站点击:点击次数、停留时间。
- 网上购物:销售额、利润、购买产品数量。
- 提交代码:commit 数量、修改代码行数、删除代码行数。
这些可以量化的属性,如点击数、利润、提交数量,我们称之为度量(measures),是我们关注的业务过程的衡量指标。
在数据仓库中,我们更关心的是汇总后的度量,例如:网站 3 月的点击量是多少;05 年销售额是多少;本周 commit 数量是多少。
维度
维度(Dimension)是指分析的各个角度。例如我们希望按照时间,或者按照地区,或者按照产品进行分析,那么这里的时间、地区、产品就是相应的维度。基于不同的维度,我们可以看到各量度的汇总情况,也可以基于所有的维度进行交叉分析。
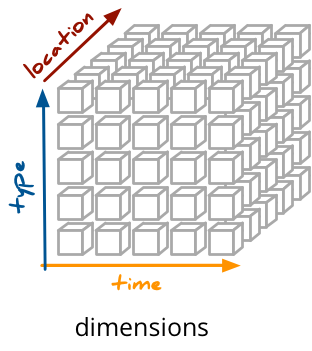
维度为事实提供上下文:
- 订单什么时候创建的?
- 哪里的客户创建的订单?
维度是分析的过滤条件:
- 2014 年有多少订单?
- 3 月份温哥华的销售额是多少?
维度层次
我们可能已经非常熟悉 Web 网站的面包屑导航和层级菜单了。当你在某个类目浏览的时候,接下来更可能要去浏览当前类目的子类目或回退到你来的位置。与此类似,我们在分析的时候按年聚合之后可能更想要分析按月聚合的数据;分析了国家的数据之后想要分析各个省的数据。也就是说,维度是有层次 (Hierarchies) 关系的。
+--------+ +--------+ +----------+
| Canada +---> | Quebec +--> | Montreal |
+--------+ +--------+ +----------+
下钻(Drill-down)
在维的不同层次间的变化,从上层降到下一层,或者说是将汇总数据拆分到更细节的数据,比如通过对 2010 年第二季度的总销售数据进行钻取来查看 2010 年第二季度 4、5、6 每个月的消费数据,如下图;当然也可以钻取 Quebec 省来查看 Montreal、Lachine 等城市的销售数据。
^
|
| +----------------+
| | 190 |
| | |
| | |
+--------+----------------+---------->
Q2
+
|
|
|
v
^ +---+
| | 80|
| | | +---+
| +---+ | | | 70|
| | 40| | | | |
| | | | | | |
+------+---+----+---+----+---+------->
M4 M5 M6
上卷(Roll-up)
下钻的逆操作,即从细粒度数据向高层的聚合,如将 Montreal、Lachine 等的销售数据进行汇总来查看 Quebec 地区的销售数据。
切片(Slice)
选择维中特定的值进行分析,比如只选择电子产品的销售数据,或者 2010 年第二季度的数据。
切块(Dice)
选择维度中特定区间的数据或者某批特定值进行分析,比如选择 2010 年第一季度到 2010 年第二季度的销售数据,或者是电子产品和日用品的销售数据。
via:http://shopperplus.github.io/blog/2015/03/28/data-warehouse-concepts-and-overview.html
 有点小错别字:
当你在某个
有点小错别字:
当你在某个