昨天,在翻看自己 Inoreader 订阅的文章时,看到一个标题《GITFLOW 有害论》,研读之下,发觉作者的观点和论据都太过牵强,甚至发觉作者对 Git 的应用和精髓都不熟悉,何来 GITFLOW 有害论?这是对先进思想的诋毁,遂发文以反驳之,以正观点,避免给更多人带来错误的指引。
《GITFLOW 有害论》这篇文章出自TW 洞见,版权也归 Thoughtworks 公司所有。本文作为一篇评论,仅是引用,本身也无意去侵权。
小插曲:昨日晚 6 点多钟,正值下班的时间,看到这篇文章后,在下面做了评论,阐述了自己的观点,反驳了作者的一些论据,谁知今早居然被删除,表示无语。
下面进入正题,开始一句一句的解读,评论和反驳,仅仅是各抒己见,绝无诋毁作者之意,另,本人也仅仅是一名普通的软件开发者,对 Git 极其喜爱和推崇,发现有错误的观点,遂忍不住站出来要为 Git 说一句公道话。
为什么发到 RubyChina, 个人认为 RubyChina 是言论自由的地方,可容纳各种观点的碰撞与摩擦。另外,我也是一个 Ruby 爱好者,正在学习 Ruby, 菜鸟一个。这应该是我在 RubyChina 的第一个帖了。当然,也发布到了我的博客, 我的博客就是自言自语,记录个人的一些想法罢了,也没什么人看。
文章通过一段一段的引用作者的原文章,然后跟上自己的评论,最后得出自己的观点。
开始解读,反驳
章节之 - 什么是 Gitflow
引用原文:
什么是 Gitflow
Gitflow 是基于 Git 的强大分支能力所构建的一套软件开发工作流,最早由 Vincent Driessen 在 2010 年提出。最有名的大概是下面这张图。
在 Gitflow 的模型里,软件开发活动基于不同的分支:
The main branches
- master 该分支上的代码随时可以部署到生产环境 develop 作为每日构建的集成分支,到达稳定状态时可以发布并 merge 回 master Supporting branches
- Feature branches 每个新特性都在独立的 feature branch 上进行开发,并在开发结束后 merge 回 develop Release branches 为每次发布准备的 release candidate,在这个分支上只进行 bug fix,并在完成后 merge 回 master 和 develop Hotfix branches 用于快速修复,在修复完成后 merge 回 master 和 develop

上面这些介绍,没什么可说的,仅有一点:
上面引用的那个图,出自:A successful Git branching model,我觉得应该像原作者标题,这仅仅是 A successful Git branching model,Gitflow 这个词先前好像没有听过,是个自造词?
A successful Git branching model 一文中,给出了大家如何更加规范的使用分支,我们可以用树的成长来比作软件开发:
- master 是树干,是基本
- develop 是大一点的枝干
- feature, bugfixes 是一些小的子叶,长的好,可能会变成另外一个枝干,长的不好可能会终结,腐烂掉。
原作者主要体现的是,区分哪些是稳定的,主干的,哪些是异变的,是可能会出问题的。一切不稳定的东西,都不能影响大局。这是全盘考虑,大局的结果。
如果整个都是一个枝干,那么如果出现严重问题,后果是比较严重的。
关于分支的理解,待下面再做详细解释。
有另外一个概念,叫:Workflow, 参见:Distributed Git - Distributed Workflows, 中文版:5.1 分布式 Git - 分布式工作流程,概念还是别搞混淆了好,上述的工作流程中:给出了三种:
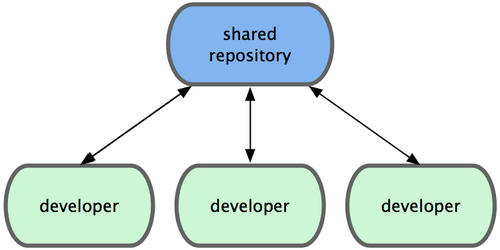
集中式工作流
集中式工作流程使用的都是单点协作模型。一个存放代码仓库的中心服务器,可以接受所有开发者提交的代码,这是类似 svn 的工作方式。
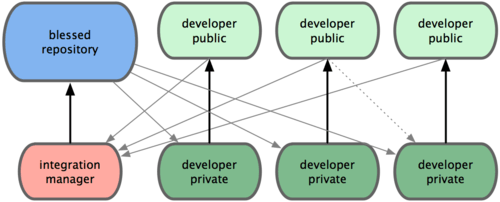
集成管理员工作流
这个类似 GitHub 上开源项目的 Fork 和 Pull Request,开源贡献者无中心仓库的 push 权限,但是可以把代码发到自己的仓库里,然后发 Pull Request 请求到开源项目管理者,Review 代码,若合适,则考虑合并到中心仓库。
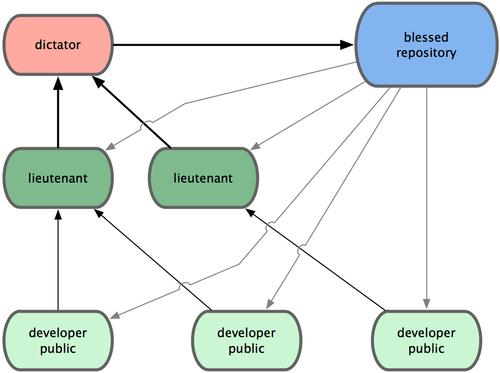
司令官与副官工作流
这种模式,我认为是上述两种模式的综合。
Note: 这其实是《Pro Git》这本书的章节,现已经合并到 git 官网,因 V2 中的图片有一个无法显示,中文版,我引用第一版。
引用原文:
Gitflow 通过不同分支间的交互规划了一套软件开发、集成、部署的工作流。听起来很棒,迫不及待想试试了?等等,让我们先看看 Gitflow 不是什么。
Gitflow 不是 Git 社区的官方推荐工作流。是的,不要被名字骗到,这不是 Linux 内核开发的工作流也不是 Git 开发的工作流。这是最早由 Web developer Vincent Driessen 和他所在的组织采用并总结出的一套工作流程。
这里是个小批注:根据上文,Gitflow 是自造词,Linux 内核开发的工作流,作者又一次把工作流和分支模型概念搞混淆。我们权当说树枝式的分支模型吧。
我们说下 Linux 社区吧,我觉得关于 Linux,我还是有些发言权的。我司是做工控领域的嵌入式 Linux, 虽不在那个团队,但也是有所见闻,并且咨询过的。 就说最近比较火的树莓派,不错,树莓派每年出货量的一半,大概 100W 套,是我司生产的。大家看看它的分支:
Github - raspberrypi/linux , 看看有多少个活跃分支,看看 rpi-3.18.y 这些分支是不是最终被合并到主干上。
引用原文:
Gitflow 也不是 Github 所推荐的工作流。Github 对 Gitflow 里的某些部分有不同看法,他们利用简化的分支模型和 Pull Request 构建了适合自己的工作流 Github Flow。 现在我要告诉你,Gitflow 在企业软件开发中甚至不是一个最佳实践。ThoughtWorks Technology Radar 在 2011 年 7 月刊,2015 年 1 月刊里多次表明了 Gitflow 背后的 feature branch 模型在生产实践中的危害,又在最近一期 2015 年 11 月刊里专门将 Gitflow 列为不被推荐的技术。 为什么 Gitflow 有问题
作者一会说分支模型,一会又说 Pull Request 工作流。关于 GitHub Pull Request,是对集中式工作流的简化,本质还是集中式工作流,只是系统帮着简化了一些操作,比如:
- Fork, 相当于首先 clone 到本地,然后在我的个人 github 空间创建一个同名的仓库,再 push 过去,而 Github Fork 点击下按钮就完成了
- Pull Request, 相当于个人开发者修复了一个 bug 或完成了一个功能,然后 push 到自己的远端仓库,然后告诉 Leader,我做完了这个功能,放到了哪里,那个分支,您 Review 下看看有没有问题,没问题请合并下。
引用原文:
Gitflow 对待分支的态度就像:Let’s create branches just because… we can!
很多人吐槽吐槽,为什么开发一个新 feature 非得新开一个 branch,而不是直接在 develop 上进行,难道就是为了……废弃掉未完成的 feature 时删除一个 branch 比较方便?
很多人诟病 Gitflow 太复杂。将这么一套复杂的流程应用到团队中,不仅需要每个人都能正确地理解和选择正确的分支进行工作,还对整个团队的纪律性提出了很高的要求。毕竟规则越复杂,应用起来就越难。很多团队可能不得不借助额外的帮助脚本去应用这一套复杂的规则。
然而最根本问题在于 Gitflow 背后的这一套 feature branch 模型。
VCS 里的 branch 本质上是一种代码隔离的技术。使用 feature branch 通常的做法是:当 developer 开始一个新 feature,基于 develop branch 的最新代码建立一个独立 branch,然后在该 branch 上完成 feature 的开发。开发不同 feature 上的 developers 因为工作在彼此隔离的 branch 上,相互之间的工作不会有影响,直到 feature 开发完成,将 feature branch 上的代码 merge 回 develop branch。
我们能看到 feature branch 最明显的两个好处是:
各个 feature 之间的代码是隔离的,可以独立地开发、构建、测试; 当 feature 的开发周期长于 release 周期时,可以避免未完成的 feature 进入生产环境。 后面我们会看到,第一点所带来的伤害要大于其好处,第二点也可以通过其他的技术来实现。
作者的这一大段都在说分支,那么我说下我对分支的理解。
我们大家都知道,Git 是分布式的,往大的方面说,其实分布式也可以理解为一个个中心仓库的分支,概念和 branch 极其的相似。就比如 master 分支,我们本身没有创建额外的分支,但是事实上存在了很多分支,比如:
- blessed_repo_remote/master
- blessed_repo_director_local/master
- develop1_remote/master
- develop1_local/master
- develop2...
再谈 git branch 的概念:
《Pro Git》中提到,git branch 仅仅是一个指针,创建和销毁一个 branch 的开销极其的少,也极其的容易。
$ git checkout -b new_branch
一句话,就可以在 checkout 的时候新出来一个 branch.
而认为分支的精髓在于:
- branch 是一个个枝叶,他的生长变化不会影响到祖先枝干。
- 而且祖先枝干可以有选择的最终向哪个方向(branch)发展,主动权在祖先枝干。
如果扩散到中心仓库和分布式的开发者本地,远端仓库,也是这个道理。主动权在中心仓库,Fork 的分支可以提供路线,但是不能左右中心仓库的发展。
作者说 为什么开发一个新feature非得新开一个branch,而不是直接在develop上进行,难道就是为了……废弃掉未完成的feature时删除一个branch比较方便?, 对分支枝干,枝叶的模型完全没有理解,就是不希望这个新的 feature 去影响主干,难道团队里面都是精英,一点差错都不会出?如果 feature 开发的过程中,发现一个原来的 bug 怎么办?新功能还没开发完,bug 又急需解决?告诉我怎么处理?
即便还是使用 develop 分支,因为 git 是分布式的,如果有多个人开发,那么就说明有多少个 develop 分支的副本分支,只要不把完成一半的东西 push 到总仓库,也还好。背后其实您已经再用分支了。
章节之 - merge is merge
引用原文:
merge is merge
说到 branch 就不得不提起 merge。merge 代码总是痛苦和易错的。在软件开发的世界里,如果一件事很痛苦,那就频繁地去做它。比如集成很痛苦,那我们就 nightly build 或 continuous integration,比如部署很痛苦,那我们就频繁发布或 continuous deployment。merge 也是一样。所有的 git 教程和 git 工作流都会建议你频繁地从 master pull 代码,早做 merge。
然而 feature branch 这个实践本身阻碍了频繁的 merge: 因为不同 feature branch 只能从 master 或 develop 分支 pull 代码,而在较长周期的开发完成后才被 merge 回 master。也就是说相对不同的 feature branch,develop 上的代码永远是过时的。如果 feature 开发的平均时间是一个月,feature A 所基于的代码可能在一个月前已经被 feature B 所修改掉了,这一个月来一直是基于错误的代码进行开发,而直到 feature branch B 被 merge 回 develop 才能获得反馈,到最后 merge 的成本是非常高的。
现代的分布式版本控制系统在处理 merge 的能力上有很大的提升。大多数基于文本的冲突都能被 git 检测出来并自动处理,然而面对哪怕最基本的语义冲突上,git 仍是束手无策。在同一个 codebase 里使用 IDE 进行 rename 是一件非常简单安全的事情。如果 branch A 对某函数进行了 rename,于此同时另一个独立的 branch 仍然使用旧的函数名称进行大量调用,在两个 branch 进行合并时就会产生无法自动处理的冲突。
如果连 rename 这么简单的重构都可能面临大量冲突,团队就会倾向于少做重构甚至不做重构。最后代码的质量只能是每况愈差逐渐腐烂。
关于分支的应用,正如上文所说,创建一个分支没什么开销,不管是命令,还是图形界面都很容易。同样,删除也是。
我们新开一个分支,把功能做好,测试确认没问题,马上就合并到枝干上,把这个分支给删除了。这个分支,甚至都不会出现在中心仓库的分支里,升值自己的 remote 仓库里,仅仅在个人本地仓库出现,可能一天,或者半天我们就完成了一个 merge 迭代,把这个分支给删除了。
作者的举例,也是有很多问题,请看:
- 关于 feature 开发的平均时间是一个月,合并到 develop 的例子,有几个地方有问题:
- 为什么在开发 feature 的时候去修复 bug? 到底是 feature 引发的 bug 还是原来的 bug? 如果解决,会不会因为 feature 带来更多的问题? ==》根据树木成长的模型,bug 我们要追本溯源,找到到底是哪里的问题,然后再哪里,新起一个分支解决,解决完,测试无问题,即可合并到主干。Feature 的分支,可以随时获取 develop 分支,已获得更稳定的基础代码。
- 同样,体现软件开发工程中耦合的问题。软件开发中,我们清楚减少耦合,git 应用中,我们同样需要。
- 关于说 merge 冲突的例子:
- 作者拿代码重构来举例,显然不是很合适。代码重构小的说是 rename 方法,大方面说是改接口,再往大的说是升级版本。简单说 1.0, 1.1 都在不断迭代,然后作者说把 1.0, 1.1 合并吧,这不搞笑吧。
- 对冲突的理解,也有偏差。git merge 什么时候会出现冲突:当出现两种截然不同的路子时候。比如原版本是 A(向南走), 你提交的是 B(向东走),合并别人的是 C(向北走),向东,向北,是两种截然不同的方向,git 当然不知道选择谁?解决冲突更多的是仲裁,相当于裁判员,这个是机器帮不了的,尽管是用 svn,svn 同样也会出现冲突,同样需要仲裁。
章节之 - 持续集成
引用原文:
持续集成
如果 feature branch 要在 feature 开发完成才被 merge 回 develop 分支,那我们如何做持续集成呢?毕竟持续集成不是自己在本地把所有测试跑一遍,持续集成是把来自不同 developer 不同 team 的代码集成在一起,确保能构建成功通过所有的测试。按照持续集成的纪律,本地代码必须每日进行集成,我想大概有这几种方案:
每个 feature 在一天内完成,然后集成回 develop 分支。这恐怕是不太可能的。况且如何每个 feature 如果能在一天内完成,我们为啥还专门开一个分支? 每个分支有自己独立的持续集成环境,在分支内进行持续集成。然而为每个环境准备单独的持续集成环境是需要额外的硬件资源和虚拟化能力的,假设这点没有问题,不同分支间如果不进行集成,仍然不算真正意义上的持续集成,到最后的 big bang conflict 总是无法避免。 每个分支有自己独立的持续集成环境,在分支内进行持续集成,同时每日将不同分支 merge 回 develop 分支进行集成。听起来很完美,不同分支间的代码也可以持续集成了。可发生了冲突、CI 挂掉谁来修呢,也就是说我们还是得关心其他 developer 和其他团队的开发情况。不是说好了用 feature branch 就可以不管他们自己玩吗,那我们要 feature branch 还有什么用呢? 所以你会发现,在坚持持续集成实践的情况下,feature branch 是一件非常矛盾的事情。持续集成在鼓励更加频繁的代码集成和交互,让冲突越早解决越好。feature branch 的代码隔离策略却在尽可能推迟代码的集成。延迟集成所带来的恶果在软件开发的历史上已经出现过很多次了,每个团队自己写自己的代码是挺 high,到最后不同团队进行联调集成的时候就傻眼了,经常出现写两个月代码,花一个月时间集成的情况,质量还无法保证。
关于持续集成,因为我是嵌入式行业的,对互联网中真正的开发,了解的不多,但是还可以类比一下,互联网一天一发布,我们一个月已发布,周期不同而已。
这里的问题核心在于计划和执行。今天要发布的,有哪些:
- 做哪些新功能,feature A, feature B
- 修复多少 bug, bug1, bug2
然后开发者去做,当然,结果可能有的 feature 开发完了,有的没有,bug 同样。如果基于上述树形的分支来去做一个个 feature 和 bug, 最后集成的时候,反而更从容些,比如某些功能没做完,那咱就不合并了,如果仅仅基于一个分支做,我怀疑下班前应该发布不了的,为什么,功能没做完,最新的代码是有问题的代码。
章节之 - 如果不用 gitflow
引用原文:
如果不用 Gitflow…
如果不用 Gitflow,我们应该使用什么样的开发工作流?如果你还没听过 Trunk Based Development,那你应该用起来了。
是的,所有的开发工作都在同一个 master 分支上进行,同时利用 Continuous Integration 确保 master 上的代码随时都是 production ready 的。从 master 上拉出 release 分支进行 release 的追踪。
可是 feature branch 可以确保没完成的 feature 不会进入到 production 呀。没关系,Feature Toggle 技术也可以帮你做到这一点。如果系统有一项很大的修改,比如替换掉目前的 ORM,如何采用这种策略呢?你可以试试 Branch by Abstraction。我们这些策略来避免 feature branch 是因为本质上来说,feature branch 是穷人版的模块化架构。当你的系统无法在部署时或运行时切换 feature 时,就只能依赖版本控制系统和手工 merge 了。
Branch is not evil
虽然 long lived branch 是一种不好的实践,但 branch 作为一种轻量级的代码隔离技术还是非常有价值的。比如在分布式版本控制系统里,我们不用再依赖某个中心服务器,可以进行独立的开发和 commit。比如在一些探索性任务上,我们可以开启 branch 进行大胆的尝试。
作者又退回到了 svn 的流程,是好是坏咱不做评价。
引用原文:
技术用的对不对,还是要看上下文。
这句话说的好。
引用原文:
[参考文献]
Long-lived-branches-with-gitflow in radar: https://www.thoughtworks.com/radar/techniques/long-lived-branches-with-gitflow Gitflow in radar: https://www.thoughtworks.com/radar/techniques/gitflow Feature Branching in radar: https://www.thoughtworks.com/radar/techniques/feature-branching Fowler on feature branch: http://martinfowler.com/bliki/FeatureBranch.html Fowler on continuous integration: http://www.martinfowler.com/articles/continuousIntegration.html Paul Hammant on TBD: http://paulhammant.com/2015/12/13/trunk-based-development-when-to-branch-for-release/ Google’s Scaled Trunk Based Development: http://paulhammant.com/2013/05/06/googles-scaled-trunk-based-development/ Trunk Based Development at Facebook: http://paulhammant.com/2013/03/04/facebook-tbd/ Fowler on feature toggle: http://martinfowler.com/bliki/FeatureToggle.html Jez Humble on branch by abstraction:http://continuousdelivery.com/2011/05/make-large-scale-changes-incrementally-with-branch-by-abstraction/ Fowler on branch by abstraction: http://martinfowler.com/bliki/BranchByAbstraction.html
没怎么看。
小结
A successful Git branching model 提到的分支模型,从大局,从软件开发的生命周期出发的一种低耦合,可持续健康成长(类树木成长)的的模型,应该很科学才对。
另外,把分支模型,和 Git 的工作流混为一谈,也是不合理的,不管是分支,还是 Fork, Pull Request 的工作流,都很科学。
本文只是自己的看法,和这些年来应用 git 的一些心得,希望能给新的 Git 用户一个不错误的指引。可能也有不对的地方,欢迎探讨。
另外,再次声明:绝无诋毁作者之意,也绝无侵权作者文章的意图,看到后,有不同观点,各抒己见。