-
如何提高 Github 的 pull/push 速度 at 2020年09月16日
对于开发需要系统层面的代理,http 或者 socks 都不够,例如 ssh 的时候,git 的时候等等,这个使用 mellow 在本机提供虚拟网卡 + 默认路由 来调整网络出口就好。上层任何应用直接正常使用就是,无需控制代理。
-
用 Terraform 自动化构建基础设施 at 2018年12月14日
@heroyct 那现在核心是 "让一人负责基础设施" 的部署,小团队没有问题,再大一点的团队可能会有基础设施的构建权限或者基础设施的变化的问题。
terraform destroy的存在心里还是很怕的,基础设施越大这个担心越可怕,所以如果有Terraform Collaboration for Everyone将 terraform 的最后执行在类似 github 那样允许的 merge 操作会放心很多。有时候不是故意,而是运维会"手抖 + tab 补全", 然后整个基础设施就全部通过 API destroy 掉了 - -||我在测试部署 DO 的时候,terraform plan/apply 很便捷,terraform destroy 很恐怖....
虽然
destroy 指令让我很恐怖,但现在使用terraform我觉得时机非常不错,terraform 开源到现在Infrastructure as Code的概念在现在的不同公用云已经很多都落地并且成熟。 大多数云厂商都为 hashicorp/terraform 提供了自己 API 的兼容 resource, 这使得Infrastructure as Code的范围扩张可以扩张得很广:- 基础使用的服务器 (AWS, Alicloud, TencentCloud, HuaweiCloud, 青云,DO, vultr, Linode ....)
- VPC, 防火墙,ssh key ... (只要对应公有云有 API, 并提供 terraform 的 resource 支持)
- 网络上的 DNS (cloudflare, dnsimple ...)
- 对象存储 (AWS S3, S3 compatible ...) ...
可以想象一下,所有程序运营的基础设施无论是服务器还是中间件,都可以通过 terraform 的 code 来定义,再利用 ansible (或者其官方的 Packer) 来解决服务器本身的初始化构建问题。项目越大,这套管理方法带来的收益越高。
所以推荐 terraform 还是很赞的!
- 基础使用的服务器 (AWS, Alicloud, TencentCloud, HuaweiCloud, 青云,DO, vultr, Linode ....)
-
用 Terraform 自动化构建基础设施 at 2018年12月14日
terraform applyvsterraform destroy都得考虑,团队上的话需要考虑好terraform destroy的问题,所以有了 Terraform Collaboration for Everyone -
Deploy Rails app with JRuby and Dokku at 2018年06月03日
利用 dokku 或者 flynn 部署 rails +pg 是一件非常愉悦的事情

-
Hello, Faktory at 2017年11月24日
-
用 500 行 Golang 代码实现高性能的消息回调中间件 at 2017年09月24日
@pathbox 我的理解是这个设计将下面几项单独出来:
- 与 RabbitMQ 之间的沟通独立出来负责与 MQ 之间的连接/重连的问题
- 将所有的任务看做 MQ 中的 Message, 负责 Message 的 成功/失败重试/死亡队列 的问题.(这个详细可参考 Sidekiq 的机制)
这个设计优势会体现在使用不同的语言,都需要使用与 MQ 之间交互,并且大家都需要 "合理的重试机制", 保证只要消息没有成功处理,就停留在 MQ 中。但劣势也很明显,每一个任务都需要具体的服务执行方提供一个结果 成功否 返回。现在的方案中是 HTTP 的同步方案. 虽然 Golang 的 goroutine 能支撑起连接数,但是这样的同步回调机制对服务执行方的接入会有场景限制,那些执行时间特别长的应该不太愿意接入 (想象一个 http 请求连着 5 分钟等返回). 如果考虑将这个中间件设计成为一个与外部系统异步交互的方式,使用端应该更乐意接入。
从另外一个角度来考虑,RabbitMQ 本身是作为多个服务之间使用消息传递解耦而存在的中间件,如果可以将这些 "重用" 的机制以扩展或者插件的方式实现到现有语言 (java, ruby, golang) 与 RabbitMQ 交互的代码中,也不失为一种方案。这样少一层抽象少一层理解。
@zamia ruby 和 golang 配合很是强大
提供两个 tips: - golang 中与 RabbitMQ 的重连问题可以考虑 cony, issue 这是个常见问题,但 golang 的 amqp 不支持,就类似 ruby 的 amqp 不支持,但上层的 bunny 支持。我们一个后端每天跑着 100w 级别任务,服务于 MQ 连接大概 100ms, 持续稳定的运行。
- golang 的 Package Manager 可以考虑 golang dep, glide 也官方宣布等着 dep 发布. dep 将现有代码和 gopkg.yml 计算双方的依赖进入 vendor 的方案更适合 golang 这个语言的特性一些。
-
RabbitMQ / Sneakers 消息重试机制及源码简析 at 2017年09月05日
@zamia 啊,看到了。可以自定义 exchange 的类型。如果是这样,那两者的区别就非常小了。sneakers 和 hutch 两者都很稳定。就是 sneakers 的队列是真的有点多...
使用 hutch 的时候,就是每次 Hutch 启动的时候都会去申请 Queue, Exchange, Consumer. 如果有变化,就立马报错了。
-
RabbitMQ / Sneakers 消息重试机制及源码简析 at 2017年09月05日
Sneakers 和 Hutch 底层都是使用 bunny, 翻一下代码就可以看到其做了重连处理。session.rb, reader_loop.rb
Bunny 的底层使用的是 amq-protocol, 这一层只负责协议交互部分不负责重连的问题。
另外应用层的 Hutch, 工具层的 Bunny, 协议层的 amq-protocol 都是 michaelklishin 核心开发者。同一个作者对这一系列的抽象很漂亮。
-
RabbitMQ / Sneakers 消息重试机制及源码简析 at 2017年09月05日
@zamia 在研究多系统交互的时候发现了 RabbitMQ 和 Sneakers, 但 Sneakers 采取的是 direct 方式的 exchange 设计,因为他走的是高并发设计所以利用 RabbitMQ 链接的多路复用机制,创建很多的 Channel. 为高性能采用了 direct 方式,对 rabbitmq 的使用而言舍弃了其灵活性很高的 topic 方式的 exchange. 另外一个 Ruby 领域的 RabbitMQ 队列 Gem Hutch 则是从 topic 的 exchange 出发设计。
- 如果是大量时间不长的小 event 事件的处理,Sneakers 比较合适。
- 如果是多系统之间的信息沟通,Hutch 比较合适。因为 RabbitMQ 的 topic 类型的 exchange 可以很好的广播消息,不同系统可以根据需要将自己的 Queue 绑定一个这个 Exchange 缓存消息。
我最后选择了使用 Hutch, 但因为 Hutch 本身不支持与 ActiveJob 的集成,我就封装了一下 hutch-schedule, 为 Hutch 提供了:
- 参考 Sneakers 实现了 Hutch 级别的类似 AJ 的重试递增 Error Retry 机制
- 提供了 Hutch 与 AJ 的 Adapter 集成
- 延续 Hutch 本身的设计,增加了延迟任务
异常重试
异常重试可以分为两类:
- 作为 ActiveJob 的后端:AJ 本身有异常处理的机制,只要后端支持延迟推送消息处理即可。
- gem 自己的异常处理:这个就类似上文中的 queue 身上的 ttl 机制了。或者类似 Sidekiq 的异常处理。
如果使用 ActiveJob 作为后端任务队列,那么这两层机制都是可以被应用到的。首先是 AJ 的以后捕获处理,如果 AJ 的超出异常了,Gem 自己的还可以再捕获一次进行重试。
RabbitMQ 的支持
对 RabbitMQ 也有两种消息重试机制:
- 一种是在 Queue 身上申明
x-message-ttl以及x-dead-letter-exchange的死信机制。 - 一种是在 Message 身上的参数
expiration(per-message) 的 TTL 机制。
单一的死信机制无法达到阶梯式重试,但和 TTL 结合起来就可以了。
`ttl message` -> 'topic exchange' -> 'dead queue' ...wait... -> 'topic exchange' -> 'queue' | ttl 触发死信机制, 重新投递 |其他经验
现在的 Sidekiq, Sneakers, Hutch 三种都采用了最基本的线程池的方式处理,他们相似的原理表示不会有数量级上的差距。唯独 Sneakers 在线程池的实现上还有一层类似 puma 的多进程 + 多线程 (supervisor), 这个会有优势。
对于 RabbitMQ 与 Redis 的区别,如果纯粹是 background job, 其实 sidekiq + redis 这种 pull 方式更合适,因为简单直接也高效。但对于需要外部系统交互,特别是与其他语言的异步解耦交互,RabbitMQ 所提供的消息中间件是很优势。(我现在是 Ruby 前端与 Golang 重后端之间通过 RabbitMQ 交互数据), 另外 RabbitMQ 是主动推送消息 (可通过 prefetch 控制量), 在节点变多之后还承担了一个消息负载均衡投递的职责,这个很省心。
-
使用 RSpec 在 Rails 5 下测试邮件的发送 at 2017年05月23日
-
Bundler 到底是怎么工作的 (暨 Ruby 依赖管理历史回顾) at 2015年12月18日
-
Bundler 到底是怎么工作的 (暨 Ruby 依赖管理历史回顾) at 2015年12月18日
什么都不说,直接 "赞" 👍
-
本人自行删除 at 2015年11月29日
bundler 针对 production 环境的处理,也就是现在 npm 那样,当前项目的依赖,就在项目自己的目录里面不要去寻找系统级的。
详细可阅读:http://bundler.io/v1.10/deploying.html#deploying-your-application
同时,调用时使用
bundle exec rails -
[长沙][2015.12.05-12.06] P8 主办的第一场社区黑客马拉松 at 2015年11月25日
@exherb 是的是的,大家都忙去了~
我来凑热闹达
-
[长沙][2015.12.05-12.06] P8 主办的第一场社区黑客马拉松 at 2015年11月25日
帮长沙顶起来~
@exherb 可以来观战吗
-
详细描述 \xE7" from ASCII-8BIT to UTF-8 这个问题,望给点意见 at 2015年11月09日
-
关于如何搭建一个核心管理服务器的问题 at 2015年11月03日
大家都到服务器上去干啥子了啊? 产品环境天天要人工上去操作吗?
-
React vs Ember by Alex Matchneer at EmberNYC meetup at 2015年11月01日
我可以补充一份打鸡血的讨论吗?虽然时间比较早 (2014.2), 但里面的讨论着实很精彩呀!
[Discussion] The future of Ghost's admin UI
然后是一段时间的实现 [Ember.js] admin UI rewrite
成功的案例,挖一挖总是有的。
-
国内有哪些像 Fastly 一样可以通过 API 主动清除掉旧缓存的 CDN? at 2015年10月22日
@veetase 稍微了解一下 Fastly, 与我想象的 API 的设定更加细节一点。其实如果提供的 API 通过 URL 来清理缓存,无论是 css 还是 js 还是其他资源清理都还是可控的。对于 Surrogate Key 这个也是自行可控的 (在 CDN 方实现这个功能更加方便,因为他可以非常方便获取我所有含有 URL 元素的 key). 对我使用 CDN 来说,我控制不到的是从请求一次 purge 开始,到所有服务器上的资源全部 clear 要花多少时间,这个时间 instantly 是最棒的。
- 能够提供静态/动态资源的缓存
- 能够提供 API 细化到 URL 甚至获取我自己所有的 key (像 redis 那样的 key xx*)
- 能够做到 5s 内,全网所有资源缓存清空。(时间越短当然是更好) 对我来说,需求就满足的差不多了,再往下挖出来的需求当然是锦上添花,以及提供相对其他 CDN 提供商的差异化功能。
-
国内有哪些像 Fastly 一样可以通过 API 主动清除掉旧缓存的 CDN? at 2015年10月21日
提供通过 API 支持清理老旧缓存 CDN 提供商很多,甚至没有 API 都可以麻烦点模拟登陆处理. 麻烦的在你提交了申请,CDN 的集群能在多长的时间内响应将老的缓存清理掉。
不过你也可以使用 rails 的思路,新的 css/javascript 文件加 MD5 来区别,这样 CDN 就会一直使用最新的 css/javascript 文件了。
-
2015 最新调查:现在的前端工程师都用什么? at 2015年09月14日
@nightire 可以推动一个 Filling all gaps in ember 啊,其实也无需每一个场景 fork 一个 repo, 可以使用 ember 专门的 Ember Twiddle 来展示代码。
其实我的目的是记录下大概的思路,因为如果细节写下每一个场景问题,可是可以扩展得很开的。但那样就会有可能收不回来而太细节。只要能够为相同场景下的问题有一个指导的方向,就可以很快找到思路避免走弯或者再在场景下优化思路。不写太细的原因是考虑到,能够碰到一些比较细节的问题的同学已经度过新手的阶段,只要"抛砖"就能够接上。
对于 trello 的形式,这个问题就 Github Issue 这个级别 + tag 就可以了,毕竟没有啥复杂的内容,只要在 Issue 中讨论也足够清晰。
@feitian124
我估计,后端作为 API Server 那 Session 的概念估计会被另外一个思路给替换了。拿购物车为例子,前端后端 (html 作为前端也是,js 作为前端也是), 都需会需要一个衔接的 "key", html 前端可以是 cookie 作为 Http 的补充,那 JS 前端估计就会需要调整为 token 作为凭证。在后端的购物车状态信息,应该是需要被持久化的了,可以是 db (数据库) 也可以是 redis (缓存), 这都是为了能够横向部署多个进程扩展嘛。换到前端要获取信息,html 前端会 jQuery 异步处理再返回结果 (js/html 片段), JS 前端也会 Ajax 回去再获取返回结果。购物车的操作一定是会沉淀到后端去的。
最后,大家都别那么激动嘛,无论 HTML 的前端还是纯 JS 的前端都是很好的方案,而且都有各自的演进线向前演进着。开源的多样性不正是好事嘛,一个个新的项目冒出来一个个新的想法迸发,看到新思路赞善一句也无妨哈,默默关注也 OK 嘛。
-
2015 最新调查:现在的前端工程师都用什么? at 2015年09月12日
我默默的出来贴一个我的 Github 问题收集 (由于发现内容太多,放在 Github 上不好找了,整到自己的 OneNote 里面去了)
https://github.com/wppurking/ember-cli-todos 这个里面是我在 demo 一个 ember 项目过程中碰到的一些问题以及一些比较简单的思考。一个 demo 寻坑的过程。
- 错误验证
- 还可以补充下 Parsley.js 纯前端方案。
- 后端 ember-data 的 DS.Errors + JSON API
- SEO => prerender.io
- 权限
- 朝向独立处理方案 (类似 https://www.okta.com/)
- JWT
然后我说个具体在 "用 rails 与 用 rails 当 api 后端 + ember 前端的感觉":
- 在纯写 rails 的时候,是拿着 rspec 写后端测后端 (复杂点的). 然后就是一大票时间在前端改 css 写 js.
- 分开后。至少我写后端就盯着 rspec 写后端测后端。然后 controller 里面就 render json 出去了,然后再控制下。接下来又是一大票时间改 css 写 js...
感觉上写起来真不是很慢,前提:"用的东西找自己熟悉感差不多的,你拿着 angualr, ember 新手的状态 + rails 与熟练的 rails 全栈的状态对比,那..... 我没话说"
不说开发速度与复杂性,但在我身上使用这两种方法的时候,我实现功能的思路都同样是区域功能放在这个区域里面实现。jQuery 操作 dom 也会特定将一些东西绑定到一起处理,然后数据放 data-xxx 再拿。在写 ember 的时候就直接封到 Component 里面写,要拿数据直接从在前面穿参数就好。
这都是工具,当然不会"拿着锤子到处都是钉子", 你还是要根据项目来估计你的工具组合的。页面越复杂,你越能感觉操作 JS 对象控件的方便。类似 CMS 给用户看的,爱用啥用啥~ 伴随着云分发 (CDN) 服务 300K 都是小事,800K, 1M 才开始有事~ (你觉得用 2G 手机的用户对移动互联网有多依赖呢?)
- 错误验证
-
[Tips on Ember 2] Ember CLI 和 Sass (及其周边) 的协同工作 at 2015年09月11日
-
[Tips on Ember 2] Ember CLI 和 Sass (及其周边) 的协同工作 at 2015年09月11日
@nightire 我就是想找一个简化的 Compass 的 sass 工具集,我孤陋寡闻了,在这发现 bourbon 实在是我想的~~
另外请问一下,bourbon 中的那些
transition(xxx)的 function 处理了多浏览器的 prefix 问题,那 Autoprefixer 的优势还会有哪一些呢? -
[Tips on Ember 2] Ember CLI 和 Sass (及其周边) 的协同工作 at 2015年09月11日
通过 ember-cli 来使用 sass 以及 sass 相关的工具真的是非常方便。ember-cli 中的将这些固定流程性的东西都整理到一起了. 引入 bootstrap 的场景问题,看来大家都会碰到哈。
外部资源的默认规则
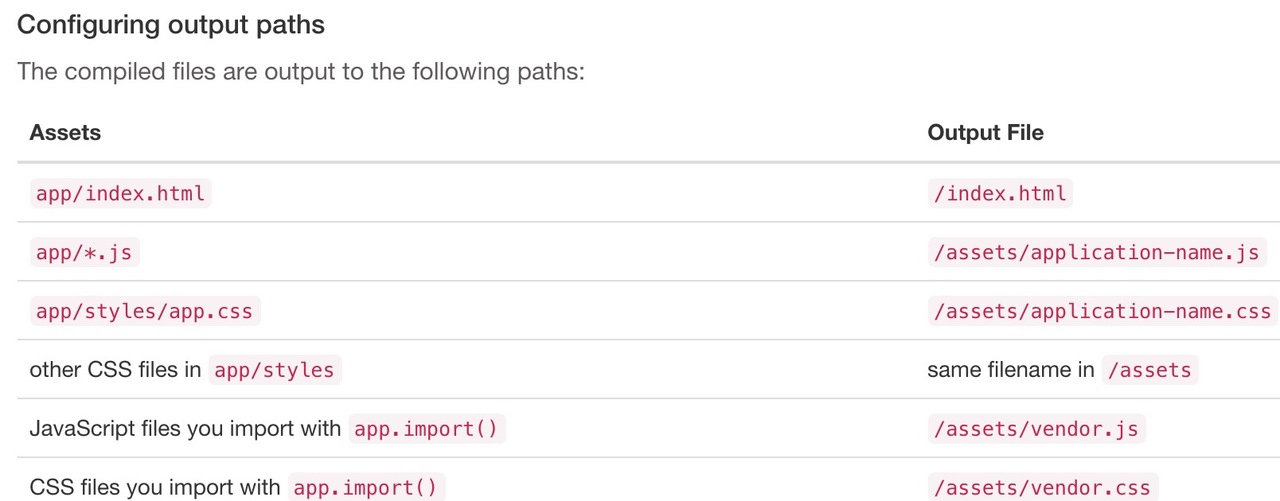
在这个规则下我们可以通过 bower 将那些打包的前端用到的库管理到本地,然后使用 ember-cli-build.js 中或者代码中有选择引入构建的 dist/ 的目录中。
- 静态引入的 app.import(xxx)
- 动态引入的 sass @import 指令
区分 bower 与 npm 的使用
这个还是需要的,不过这两个同时存在 ember-cli 里面总会冒出一些模棱两可的地方 (功能重叠), 例如 bootstrap-sass 即可在
bower.js中存在也可以在package.json中存在。但总体上来区分的话,既有 js 又有 css 的用 bower, 纯 js 以及要用到 node 的用 npm.综合使用
在这两者的使用上,就可以整体上这么用。
- 通过 bower 和 npm 管理你的依赖 (外加自己的 vendor 文件夹)
- 默认规则 + 使用 app.import + sass @import 引入。
-
JetBrains 家的桌面产品要全部改成订阅式了,就是说按月或按年付费。 at 2015年09月07日
-
我使用 RubyMine 来开发 ember.js + rails =.=
我压根就会将自动补全给关掉,然后需要的时候再手动巧一下快捷键。很多框架的支持在 jetbrains 的产品基础平台上基本都是通过插件集成的,插件的质量我用过的官方自己支持的是真的高质量。比如 scala, Angularjs, Nodejs, ideavim, Handlebars 的插件~
用 RubyMine 的最大原因是,被 jetbrains 的产品养成了快捷键,集成的工具的使用习惯以后,换到任何其他的工具都觉得不顺手,写东西不够快...
-
JetBrains 家的桌面产品要全部改成订阅式了,就是说按月或按年付费。 at 2015年09月04日
- 开发模式都已经从瀑布变成敏捷了~
- 测试已经从版本通测变成持续集成了~
- 收费也要开始从 License 变成 Subscription~
趋势,趋势,趋势。
产品该更新一定会更新,不更新的产品就是等着被更新的产品代替掉 用户看上的产品以解决问题为主,如果他已经不存在那个问题了,是 License 还是 Subscription 对他也没区别了。
-
[长沙] 招聘创业小伙伴, 微信开发, 10k, 期权 at 2015年09月02日
欢迎回到家乡创业~ 交流交流~~~
-
[Tips on Ember 2] 如何尝试 angle-bracket component at 2015年09月01日
赞赞赞
补充一个的
Ember.Component与Ember.GlimmerComponent对比的视频连接,这两个人好欢乐Angle Bracket Components Sneak Peak by Yehuda Katz and Godfrey Chan @ EmberSF