Sneakers 重试机制及源码简析
Sneakers 是基于 RabbitMQ 的高性能后台任务处理系统,可以方便的对接 RabbitMQ 来解决各种异步消息通信的问题。而异步消息的处理中,为了做到系统的稳定性,任务的重试机制就非常重要,本文简单介绍一下 Sneakers 如何基于 RabbitMQ 内部的机制来实现任务的重试机制的。
为什么使用 Sneakers
当系统变的越来越大的时候,一般的处理方式是按照产品线、或者按照层次进行服务化的拆分。随着公司的服务越来越多,服务之间的通信也会越来越多。除了各种同步(http、rpc 等)的通信之外,还有很多异步通信的场景,比如以订单举例:
- 订单创建成功之后,通知消息系统,需要发送邮件/短信给用户;
- 订单支付成功之后,通知工单系统,创建工单用于跟进用户;
- 订单完成之后,通知财务系统,需要给供应商转账了;
这种系统之间的通信,同时又不需要同步进行的操作,使用消息队列就比较合适,目前大鱼使用的是 RabbitMQ。
同时,使用消息队列之后,也需要一个靠谱的任务处理机制来实时监听消息,保持和消息队列的长连接,一旦有消息到达,就可以开始执行某个任务,本文中 Sneakers 就是这样的一个 Gem。
同时,消费消息的时候难免需要重试,比如上面的例子中,如果收到消息时,邮件服务器无法连接、工单系统创建工单失败、财务系统可能挂掉,那么这时应该怎么处理呢?一般来说,处理方式是这样的:
- 遇到错误时,等待一定的时长,然后重试;
- 下次重试时,如果仍然失败,继续等待下次重试;
- 重试 N 次之后,如果仍然失败,那么直接进入垃圾消息队列,等待人工处理(比如发送报警给工程师);
背景介绍的差不多了,本文主要要讲的是 Sneakers 如何利用 RabbitMQ 内部提供的 x-dead-letter(死信机制)的机制聪明的进行任务的重试机制的。
Sneakers 的重试机制简析
如果不深入思考,可能觉得一个消息处理系统的重试机制应该很简单,比如读取一条消息,然后处理,如果有异常,则把消息重新发送一遍即可。但是这样有几个问题:
- 读取消息之后,如果 worker 崩溃了,那是不是这条消息就丢了呢?
- 处理消息时,如果有异常,worker 怎么知道这是第一次异常还是 N 次异常之后呢?如何记录这个重试次数?因为业务上一般重试 N 次之后仍旧失败,就没必要再次重试了,直接报警人工处理即可。
- 如果把消息重新发送一遍,这时如果消息发送失败,那么是不是这条消息也就永远丢失了呢?
那么 Sneakers 是怎么处理这个问题的呢?它很聪明的利用 x-dead-letter 来处理重试问题。
X-Dead-Letter 机制指的是:
队列中的消息可以被『Dead-Lettered』,也就是说,当下面的情况发生的时候消息会被重新投递到另外一个队列:
- 消息被 reject,同时 requeue = false;
- 消息的 ttl 超时时;
- 队列中的消息数超出队列的最大长度限制;
Sneakers 内部借助这个机制实现了消息的重试,同时保证了消息不会丢失以及高性能,它是如何实现的呢?
概览图
直接上我画的这个 RabbitMQ + Sneakers 内部处理机制的消息流转图:
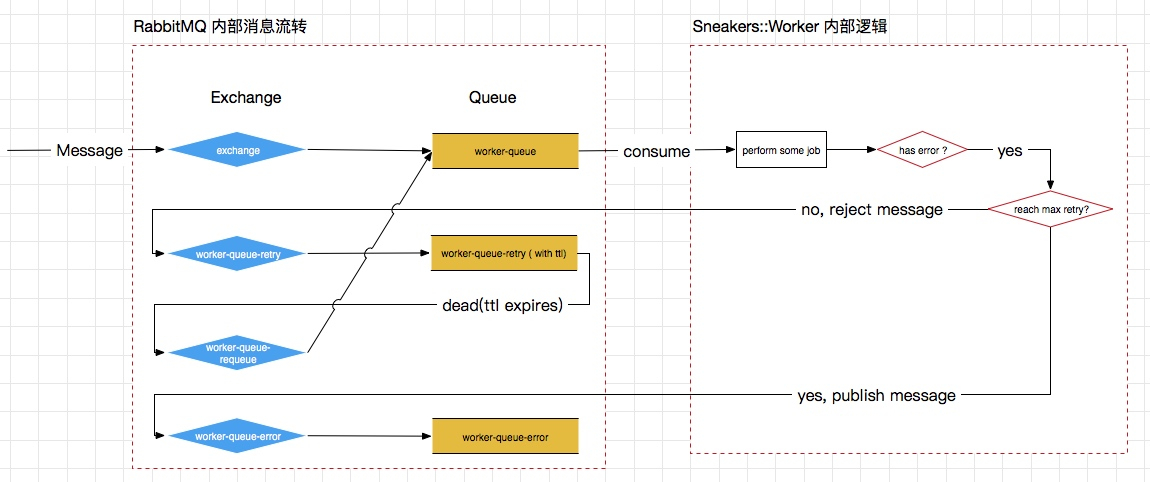
上面这个图中:
- exchange - 业务 Ex,业务消息投递到这个 Ex;
- work-queue - 业务队列,任务都在这个队列处理;
初始化
在初始化阶段,Sneakers 会直接在工作队列之外自动创建一系列的 Exchange(用 X 标记)和队列(用 Q 标记):
- worker_queue-retry(X) - 工作队列的死信目的地;
- worker_queue-retry(Q) - 绑定了上面这个 Exchange 的队列;同时,它的死信会投递到 worker_queue-retry-requeue;
- worker_queue-error(X) - 如果达到最大重试次数,会把消息投递到这个 Ex;
- worker_queue-error(Q) - 绑定了上面这个 Ex;
- worker_queue-retry-requeue(X) - 工作队列会绑定到这个 Ex,也就是说这个 Ex 的所有消息会投递到工作队列。
消息处理阶段
在消息处理阶段,用文字来描述一下上图中的流程就是这样子的:
- 正常消息进入 exchange 这个交换器(Ex);
- worker-queue 会接收到这个消息,然后 Sneakers 的 worker 会来消费消息;
- worker 一切正常的时候,直接 ack 消息即可(这是正常流程,图中没有体现);
- 如果 worker 执行出错,首先判断是否到最大重试次数;
- 到达最大重试次数,直接把消息投递到 worker_queue-error 这里即可;
- 如果没有到达最大重试次数(也就是需要消息重试),那么直接 reject 消息即可。
其实到这里,Sneakers 内部的代码逻辑就结束了,是不是还挺简单的。而事实上 reject 消息之后,RabbitMQ 内部会做下面的逻辑:
- 消息被投递到 worker_queue-retry(X),然后 worker_queue-retry(Q) 会接受到这个消息;
- worker_queue-retry(Q) 的消息并没有谁会去主动消费,直到消息的 TTL 到期,然后消息被投递到死信 Ex;
- 消息被投递到 worker_queue-requeue(X),然后这个 Ex 的消息直接投递到工作队列;
- 工作队列的消息然后就可以等待被消费,也就是一次重试的完成。
这样实现的好处
这样通过 RabbitMQ 和 Sneakers 的配合,就完成了整个消息的重试机制。这么实现的好处至少有下面几点:
- 在整个重试过程中,消息不会丢失。不管是 reject 也好,还是 RabbitMQ 内部的 ttl 超时也好,都是可靠的消息投递过程。
- Sneakers 的代码实现逻辑非常简单,基本上只需要在出错时判断是否到最大重试次数,然后 reject 或者投递到 error 队列即可。
- 很好的利用了 ttl 的机制,可以配置消息的重试时间。
是不是也挺简单的?看看代码中如何实现的吧。
Sneakers 源码简析
其实经过上面的分析就能看出来,代码实现其实是非常简单的。我们分两个阶段看,一个是初始化阶段创建各种 Exchange 和队列,一个是消息处理阶段,调用 perform 函数通过捕获异常来做对应的处理。
(下面的代码来自于 sneakers 2.5.0 版本)
初始化
初始化过程就是上面说的建各种队列:
# lib/sneakers/handlers/maxretry.rb
# class Maxretry#initialize
retry_name = @opts[:retry_exchange] || "#{@worker_queue_name}-retry"
error_name = @opts[:retry_error_exchange] || "#{@worker_queue_name}-error"
requeue_name = @opts[:retry_requeue_exchange] || "#{@worker_queue_name}-retry-requeue"
retry_routing_key = @opts[:retry_routing_key] || "#"
# 这里是创建各种 Exchange
@retry_exchange, @error_exchange, @requeue_exchange = [retry_name, error_name, requeue_name].map do |name|
@channel.exchange(name, :type => 'topic', :durable => exchange_durable?)
end
# 绑定重试队列,注意 x-dead-letter-exchange 和 x-message-ttl 参数
@retry_queue = @channel.queue(retry_name, :durable => queue_durable?,
:arguments => {
:'x-dead-letter-exchange' => requeue_name,
:'x-message-ttl' => @opts[:retry_timeout] || 60000
})
@retry_queue.bind(@retry_exchange, :routing_key => '#')
# 绑定 error 队列 和 error Ex
@error_queue = @channel.queue(error_name, :durable => queue_durable?)
@error_queue.bind(@error_exchange, :routing_key => '#')
# 注意这里,直接把 worker-queue 和 requeue-exchange 绑定
queue.bind(@requeue_exchange, :routing_key => retry_routing_key)
消息处理阶段
消息处理阶段的逻辑基本都在 handler_retry 函数中,直接贴代码,删了一些日志语句,也加了一点注释。
def handle_retry(hdr, props, msg, reason)
num_attempts = failure_count(props[:headers]) + 1
if num_attempts <= @max_retries
# 还不到最大重试次数时,reject 消息,消息会进入到队列的 x-dead-letter-exchange,也就是 worker_queue-retry(X)
@channel.reject(hdr.delivery_tag, false)
else
# 到达了最大重试次数,就直接把消息发送到 error Exchange 即可
data = {...).to_json # 这里省略了一些代码
@error_exchange.publish(data, :routing_key => hdr.routing_key)
# 然后正常 ack 消息,消息会从 work-queue 消失。
@channel.acknowledge(hdr.delivery_tag, false)
end
end
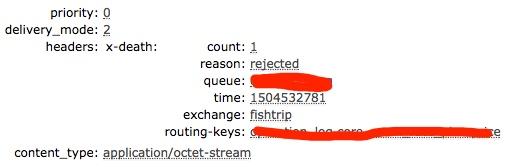
上面这个 failture_count 怎么实现的呢?其实是利用了 RabbitMQ 的特性。RabbitMQ 中,每当消息被「dead-lettered」,在消息的头 x-death 中会详细记录消息死亡的计数信息,大概长这个样子:
我们看看 Sneakers 中的实现:
def failure_count(headers)
if headers.nil? || headers['x-death'].nil?
# 看看有没有相关信息
0
else
# 把 x-death 中的相关信息找到,这里要比对 queue 的值
x_death_array = headers['x-death'].select do |x_death|
x_death['queue'] == @worker_queue_name
end
# 不同 RabbitMQ 版本做了兼容,直接读 count 或者读数组的条目数
if x_death_array.count > 0 && x_death_array.first['count']
x_death_array.inject(0) {|sum, x_death| sum + x_death['count']}
else
x_death_array.count
end
end
end
总结
Sneakers 的重试机制代码虽然非常简单,但是通过利用 RabbitMQ 本身的机制,很完美的解决了 RabbitMQ 消息重试的问题。但是也有下面的一些问题:
- 对 RabbitMQ 有一定的侵入性,无端增加了非常多的 Exchange 和 Queue,看着有点乱;
- 通过 ttl 的方式,无法实现阶梯式的重试时间递增,如期望重试间隔是 10s/100s/1h/2h/10h 这样子;
总体来说,Sneakers 这种解决重试的机制仍然是不错的机制,利用中间件本身的特性、加上少量的代码即可实现可靠的消息重试。
欢迎讨论~

