以下是 Bundler 作者 André Arko 今年在 RailsConf 上的演讲,译自 [1]。
引子
Hi 大家好,本演讲的标题叫做“Bundler 到底是怎么工作的”。这个话题基本上是来自于我意识到,当我跟别人聊这个问题的时候,很多人说:“哦,我知道 Bundler 怎么工作,不就是你把 bundle install 这句话从一些 gem 的 Read Me 中拷贝出来执行吗,那就是 Bundler 怎么工作的!“
然并卵。如果你真正关心的是当执行这些命令“底下到底发生了什么”的时候,你就需要理解 Bundler 解决了什么问题。而如果你要理解 Bundler 解决了什么问题,你就需要理解“Bundler 解决的这些问题”是怎么产生的。而为了理解产生这些问题的问题,你就得了解产生产生这些问题的问题的问题。
所以,这个演讲其实是一个对 Ruby 依赖管理历史的简短介绍。我希望我能把它介绍得足够简短。
自我介绍
开始之前,我想快速得向大家介绍我自己。我的名字叫 André Arko,但是在网上我不直接使用这个名字。这是我的现在的头像,在网站或其他网络社区上你可以看见我的这个图片。我供职于 Cloud City Development,大多数情况下外援那些需要决策咨询服务的团队,我知道决策如何变成一个错误,并且能提前为他们给出警告;我还会与一些初中级程序员结对编程,告诉他们 Ruby 是怎么工作的。如果你的团队需要这样的人,可以在演讲之后找我。

我另外参与了《The Ruby Way》第三版的撰写工作,这本书的第一版绝对是我 2001 年最喜欢的 Ruby 书,我基本上就是从那本书学会的 Ruby。第三版是针对 Ruby 2.2 和 2.3 进行的更新。我确定最少 6-9 月之后你们的屏幕上出现的就是这个版本的 ruby。
另外我做的事情叫做 Ruby Together,是个公益组织,有点像 npm,但是我们的组织里没有风险资本家。基本上我们从那些使用 Ruby 的公司和个人那里拿钱,然后我们把钱分给开发者,支持他们开发维护那些 Ruby 社区里人人都需要的公共项目。有数个公司赞同我们这个方法,包括 Stripe、New Relic、Basecamp。Ruby together 支持的项目包括 RubyGems——大家获取 gem 的一个公共的服务器;另一个就是 Bundler。
我作为 Bundler 的项目领头人已经大约 4 年了,这就是为啥今天由我要来讲 Bundler。
历史课
我们来分发一些 ruby 代码,看看使用别人写的代码有多难。其实如今这很容易,你只需要把 gem "foo" 这句话放在你的 Gemfile 里面,然后运行 bundle install,然后 bundle exec foo,搞定!
如此容易,但是当你运行的时候到底什么发生了?其实很复杂。一些东西被安装了、一些东西被下载了。什么被下载了?下载的东西去哪儿了?后期如何找到它?我不知道!
所以现在是历史课时间!我想带领你开始依赖管理历史的观光之旅,当我们完成的时候,你将不仅知道它“如何”工作,并且知道它“为什么”如今这样工作。就像你对任何关于计算机的事情做出的预测一样,答案其实就是——历史遗留问题。(笑)
这是一个我要讨论的课题的提纲,先讲 require —— Ruby 中从文件加载代码的手段;再讲 setup.rb,当时第一个能将代码安装到 ruby 里的机制,有了它你就不用再明确指定要 require 的文件的路径了;然后我们来看看 RubyGems,当时首个能允许你轻松下载别人的代码的工具;最后我们来看 Bundler,它让你可以有一堆 gem 同时正常工作。

1997 年:require
我翻代码查过,require 方法至少 1997 年就有了,是最早进入版本控制的 ruby 代码之一。可以预测的是,require 在一个历史时期也存在过,但是当时 ruby 还没有被加入版本控制,所以我查不到。虽然 require 很古老,但是它依然可以被分解为一些小概念——使用从其他 ruby 文件加载进来的外部代码基本上等同于,从那个文件复制粘贴一些代码出来替代 reqiure 那一行。这挺直观的,你其实可以如下自己实现一个幼稚版的 require。
def require(filename)
eval File.read(filename)
end
正如我所说,这是幼稚版,你可能已经发现了其中幼稚的点。例如如果你调用 require 两次,代码就会被执行两次,一般这不是个好事儿,尤其是当被加载的代码的职责是定义一些常量、定义一些类等等。加了这个功能的 require 也不难写,我一张幻灯片就展示的开。
$LOADED_FEATURES = []
def require(filename)
if $LOADED_FEATURES.include?(filename)
return true
end
eval File.read(filename)
$LOADED_FEATURES << filename
end
事实上,Ruby 确实有 $LOADED_FEATURES 这个全局变量,里面的内容就是你 require 过的所有文件,干得好!(笑)接下来你会发现的另外一个问题,你只能传递绝对路径进来。例如如果你写 require 'rails' 它就会抱怨根本没有 rails 这个文件。如果你知道你机器上的每个文件都在哪儿,这当然是没问题的,但我假设你不喜欢让这个情况——一个人不得不知道所有路径。最简单的办法就是假设传进来的路径都是相对于当前路径下的相对路径,这虽然简单,但是如果你想从别的路径加载内容,那就没门儿了。所以让我们实现一个可以从多个目录加载内容的版本。我想,理论上,我们可以有一个全局数组,里面包含了一个路径的列表,然后 require 的时候循环这个列表,看要 require 的文件是不是在这个目录中。我一张幻灯片甚至也展示得开这些代码。
$LOAD_PATH = []
def require(filename)
full_path = $LOAD_PATH.first do |path|
File.exists?(File.join(path, filename))
end
eval File.read(full_path)
end
事实上,Ruby 确实有 $LOAD_PATH 这个环境变量,它就是这么干的。但是在真正的 ruby 中,代码不像我的幻灯片这么简单,因为 $LOADED_FEATURES 和 $LOAD_PATH 的逻辑都在同一个函数里,我一张幻灯片展示不开。
2000 年:setup.rb
$LOAD_PATH 这个功能挺酷的,我们可以建立一个目录放 ruby 的标准库,现在加载 http 库就容易多了,你就写 require 'http',然后 ruby 就找到了 http 的标准库的路径,用起来好爽!但这个时候,有 ruby 程序员跳出来说,嘿!我也写了一些代码,我想让别人用我的代码。这就是为什么我们会有 setup.rb。
在 1997 年 ~ 2000 年期间,require 已经足够好用了。大约 2000 年左右大家是怎么安装别人的 ruby 代码的呢?我们会说:“有个伙计用 email 发给我了一段他写的 ruby 代码,然后我把它拷贝到 $LOAD_PATH 中的一个目录里,然后我 require 了它,一切工作正常”。但这个过程你想象一下,别人发给你文件然后你复制粘贴,真是令人生厌!
所以接下来的解决方案——setup.rb——是一个自动化拷贝 ruby 文件到一个特定的目录位置的脚本。这个位置的诸如 /usr/local/lib/ruby/site_ruby/,你可以把任何你想要的东西放入那个目录。setup.rb 就是实现往那个 site_ruby 目录中拷贝东西的脚本。site_ruby 这个名字用来描述一个关于 ruby 的包的安装位置虽然有点古怪,但是它确实可以工作。
令人惊奇的是,setup.rb 现在在网上依然能看得见,在我很喜欢的网站上 http://i.loveruby.net/ ,你可以直接下载你想要的东西。但自从 2005 年以来没人再维护过那个网站了,所以我其实不太推荐你用。
本质上,setup.rb 就是经典的 Unix 的 configure、make、make install 三位一体流程的 Ruby 版。
ruby setup.rb setup
ruby setup.rb config
ruby setup.rb install
使用一个 ruby 库的整体流程就变成了,
- 找到一个酷毙了的 ruby 库
- 下载这个库
- 解压缩
- 执行
ruby setup.rb all
然后 site_ruby 目录里就多了这个库,然后你就可以 require 它来使用了。
在没有 RubyGems.org 的岁月里,有一个 Ruby Application Archive 网站,我当时刚学 ruby,觉得它好棒啊!竟然有一个我可以随时登录的网站,上面列出了各种人们已经写好的、你不用再写一遍的、可以完成某项任务的 ruby 代码。因为以前没有 Ruby Application Archive,你如过想用一个库你就必须找到那个库的作者,再找到他的主页,然后下载那个库的压缩包。
Ruby Application Archive 是不错,但是也有问题,你可能已经想到了。一个大问题就是没有版本控制。你用的是哪个版本的库?谁知道?或许他们写在注释里了呢。如果注释里没有,你可以下载所有的版本然后开始猜。如果有了新版本,你怎么升级?你最好当时把那个你下载库的网页加入了收藏夹,或者作者把那个 URL 放在他们的注释里了。祝你好运吧!当你找到那个新版本后,你又要重新下载,解压缩,再运行一遍 ruby setup.rb。但是老版本没卸载啊!你最后得到的是老版本里覆盖了新版本的一个混合体。你最好祈祷他们没在新版本里删了什么老文件,否则坑可大了去了。
最后,也是这个方案的我最喜欢拿出来说的一个缺点,就是所有的文件都去了同一个目录。如果你有两个目录都定义了 cool_thing.rb,抱歉!最后一个装的库是赢者。我不知道你作为听者,是不是觉得这个方案很单调沉闷,但是我确实觉得它很冗长乏味。当有人改了新版本中的代码,然后你想要这个新版本,当你安装了之后,有东西不一样了,然后你机器上所有依赖于旧版本的代码就全都不能工作了,而且你根本不知道他们能不能工作!这令人沮丧。
2003 年:RubyGems
所以,在 2003 年,RubyGems 出现了,就是特定要解决 setup.rb 的问题的。它提供了一个单一的命令行工具 gem,这非常给力!它允许你用一个单一命令完成下载以及安装,这非常给力!它允许你一键卸载,这非常非常给力!它允许你中心化地管理所有安装了的库,这超级超级给力!对于 Ruby 代码分发这件事来说这是革命性的,人们会说,这个东西好酷,我要让大家都来用。我认为这就是在我开始用 Ruby 后,为啥我觉得 Ruby 很酷的主要原因,因为 RubyGems 在那个时代是全新的。我当时惊呼:“哇!我可以写一些别人会觉得很有用的工具。“我跟我的朋友们坐下来写写代码,然后发布成 Gem,真是酷毙了!
gem install
gem uninstall
gem list rails
关于给力,我想提的最后一个点就是——多版本。setup.rb 把所有东西都放入同一个目录,就没法识别你的版本是多少,也没法让多版本共存。RubyGems 事实上把 require 方法给加了个 hack,使得你的机器上可以装多个版本的 gem 包。
gem install rails -v 4.1
gem install rails -v 4.2
gem install rails -v 5.0
如果某个 gem 的任何版本还没有被加入 $LOAD_PATH,RubyGems 会帮你加入最新的版本;如果你想要特定的版本,你可以告诉 RubyGems,她就会把那个特定的版本加入 $LOAD_PATHS。你可以调用 gem 方法,并带有一个版本号,哪个版本的路径就会被加入 $LOAD_PATH,后期当你调用 require 的时候,那个版本就是你得到的版本。超棒!
gem "rack", "1.0"
require "rack"
当时有个鲜为人知的 gem,可以让你通过下划线制定特定的 gem 版本。我不知道这个事儿跟你们的人生是不是有特别的关系,但调试 gem 版本和依赖有的时候确实很重要。(笑)我很关心这个事儿!
backup _1.2.2_ -p 3000
RubyGems 让 gem 的世界发生了大爆炸。如今,网上已经有将近 10 万个 gem 包、100 万个 gem 版本了!这实在是很酷!你可能已经注意到,当我们开始使用这些 gem 包的时候,还是有问题。新问题就是,如果你有多个 ruby 项目,而它们都需要 gem,怎么办?其实在多年后,这才真正变成了一个大麻烦。gem 世界的大爆炸意味着,如果我运行 gem install foo 并使用它,一周后我想把我的代码跟朋友分享,我就得跟他说你需要先装 gem install foo 代码才能工作;但我的朋友可能会得到一个完全不同的 gem 包,跟我的不一样,因为我装的时候已经是一周以前了。这不太好。(笑)
然后当你想部署的时候,你也要去服务器上运行 gem install foo,并且祈祷你能得到同样版本的代码。2008 年,我开了一家 Ruby 公司,配新机器确实是发生在我身上的问题。他们会说:“嘿,这是你的新工作电脑!我们真的很希望你能在一周内把我们的项目跑起来。”我当时野心勃勃,工作也很卖力,我晚上没啥事儿干,我花了大约 3 天的时间,全部用来调试各种错误日志,各种安装 gem,才能把项目跑起来。
2009 年:Bundler
一旦 Ruby 社区意识到这是一个痛点,人们就开始提出各种解决方案。最流行的方案就是,Rails 当时加入了 config.gem,你把下面的代码加入你的 Rails 应用,然后有另外的一个叫做 gem installer 的 gem 去负责安装它们。但问题就是,它总是安装最新的,旧版本用不了。我的一个真实故事就是,一个所有人的开发机上都工作正常的应用,在生产环境就不工作,我调了 3 天,发现一个 gem 原来开发机上是 1.1.4,但是生产机上是 1.1.3。
# config/application.rb
[...]
config.gem "rack"
config.gem "rails"
config.gem "what?"
[...]
另外一个问题是版本冲突,设想你有两个 Rails 应用而不是一个,假设你是做外包的,然后有两家客户,他们用的 Rails 版本都不一样。这个时候你就会特别关注上面我说的那个通过下划线明确指定版本的事情了。你升级 rails 也不行,因为另外一个开发者就会抱怨——“嘿!你怎么把代码弄的不工作了”。然后你再去辩护——”不!那是因为我升级了,不是我弄坏了,是你得升级你的 gem!“ ”哪个 gem?” “看 Read Me” ”Read Me 是最新的吗?“ ”可能吧!”然后那个家伙升级了,结果他机器上其他的项目又不工作了,那它再去升级那些项目,就开始重复上述过程。
所以作为 Ruby 开发者,大部分时间都用在搞清楚“为什么当 gem 版本对不上,你的那堆屎不工作”的问题上了。太糟糕了。
修复上述问题已经是 bundler 存在的一个很大的必要性了,但是我们还有别的原因,更令人沮丧。当一个 gem 包说我依赖于某版本的某库,那么这个库的路径就被放在 $LOAD_PATH 中了,但这时来了另外一个 gem 包,它同样依赖于某库,然而依赖的是另外一个版本,这时这个版本就不能被放进来了,因为另外一个版本已经存在了,这个时候就会抛出 activation error。曾经有一次,我们的生产服务器工作的特别好,直到有人执行一个动作触发了这个错误,我们的服务就挂了。但我们的服务死后被自动重启了,所以我们当时还没注意到,直到有人提出说为什么执行那个动作不能工作,而我们开始调试的时候,才发现了这个 activation error。你可能认为这个错误不好重现,其实不是的。在 2007~2008 年期间,基本上每一个 gem 依赖稍微多一点的 rails 应用都会碰到下面的微妙的报错。
$ rails s
Gem::LoadError: Can't activate rack (~> 1.0.0., runtime) for ["actionpack-2.3.5"], already activated rack-1.1.0 for ["thin-1.2.7"]
上述故事就告诉我们,版本冲突的解析不应该发生在运行时,而应该发生在安装时。但这个过程如何实现?这才是 Bundler 要解决的主要问题。如何计算需要哪些版本的哪些 Gem 才能使得他们能共存,每个 Gem 都可能依赖于其他 Gem,其他 Gem 又依赖于其他 Gem。在 Bundler 存在之前,这个过程完全是手工完成的。如果你的 Gem 集合不能协同工作就会抛出异常,然后你再手工尝试其他版本。如果又不工作,再换再尝试,直到没有异常。在这种重复性的单调工作面前,计算机比人更擅长。因此,Bundler 帮你完成这个任务。
多谢了 Bundler,Ruby 开发者只需要列出他需要的 Gem,然后 Bundler 就会找出合适的版本让它们在一起正常工作。这个过程叫做“Dependency Graph Resolution”,这是一个众所周知的难题,而且不一定有解。下图是 Bundler 生成的一个依赖图,我们仅仅是放入了 Rails 这个依赖包就如此复杂。Bundler 使用了很多技巧性和启发式算法来解这个依赖图,并且把一个可行解(但不一定是最优解)放入 Gemfile.lock。我们在多年间构建了很多这些解依赖图的技巧,使得大多数 Gemfile 如今可以做到在几秒钟的时间内就可以被解析好。我们自己构建的最坏的病态的例子需要一分钟来解析,最近的版本我们优化到几秒钟了,所以我们基本有信心说我们已知的复杂的 Gemfile 都可以在几秒钟的时间内搞定了,挺酷的。
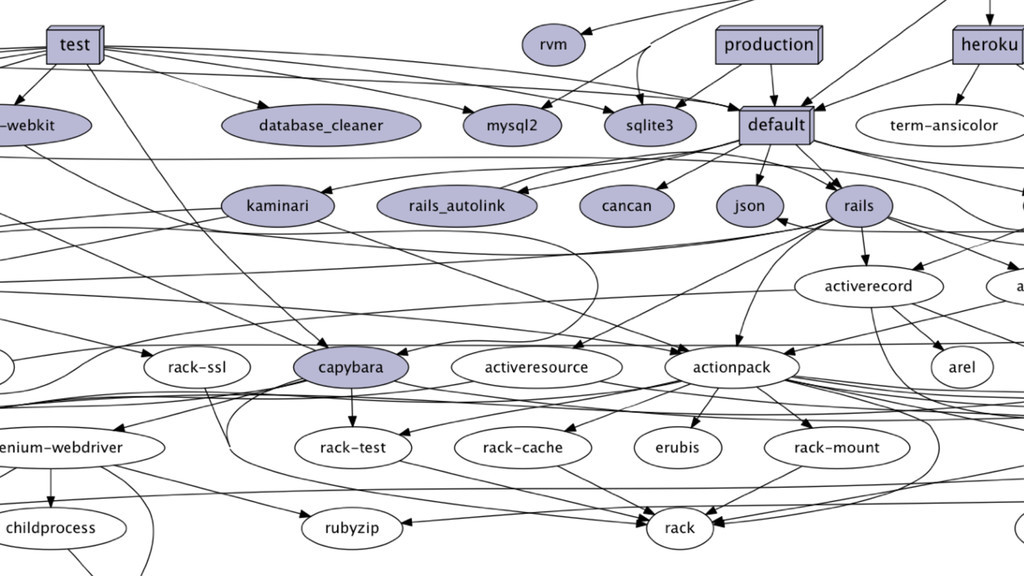
一旦 Bundler 找到了一组可以工作的版本组合,Bundler 就把每个 gem 的特定的版本号记录在一个列表里,这个列表就叫做 Gemfile.lock。这个文件保证了当我把一份代码分发给你的时候,你总是能安装到正确的依赖版本,分发给生产服务器、CI 服务器同理。
到底是怎么工作的
回到我们的演讲的标题——“Bundler 到底是怎么工作的”,归结为两件事。第一件事就是 bundle install,搞清楚哪些 gem 可以协同工作,下载这些特定的版本,写 lock 文件,并安装这些特定的版本。第二件事就是 bundle exec,确保在这个命令下运行的 Ruby 代码 require 到的库都是 lock 文件中指定的那些特定的版本,而且会事先把 $LOAD_PATH 中多余的东西清理掉让你不会误引用到其他的版本。但是许多人不喜欢 bundle exec,我也不喜欢,因为我不想打字,一个解决方案就是 alias,可以把你的终端里 b 别名成 bundle exec;另外一个方案是 bundle binstubs,创建特定的 gem 版本的特定命令,就可以彻底抛弃 bundle exec 了。
bundle binstubs spec-core
bin/rspec
# 其他 gem 也要重复这个过程
这样 bin/rspec 就只会使用 lock 中指定的版本了。Rails 其实公开支持这个使用模式,并且从 Rails 4 起每个 Rails app 都会带有 bin/rails 和 bin/rake,当你运行这些命令的时候就会得到特定版本的 rails 和 rake 了,同样的方法也适用于其他的所有代码和 gem 包,挺酷的。
展望
讲到这儿总算回到我们生活的时代了。但我们的进步会就此终结吗?非也。当时 Bundle 1.0 解决了 activation errror,但是带来了新的问题——bundle install 要花好几分钟才能执行完;为了解决那个问题,我们发布了新版 Bundle 1.1,来优化这个问题。如今,在新版本中我们还会持续改进,我强烈建议大家看看 http://bundler.io ,上面有很多新东西,也可以关注我们的 Twitter。如果你能贡献代码就更酷了,因为每个人都在用 bundler,我们期待你的帮助。
如果您是一家公司(笑),哦不,如果您在一家公司工作并且在想,这虽然不错但是我们公司没有给我多余的时间让我做 bundler 的开源工作,也没关系!让您的公司给 Ruby Together 赞助资金,我们将帮您做这些工作,您就不必担心了。(笑)当 Ruby Together 变得更强大时,我们有计划不光资助 Bundler,并且也将涉足其他社区领域,例如我们在研究 gem stash —— 一个可以在你的办公室或私有云上本地运行的 gem server,它可以成为 ruby gem 的一个本地缓存层,你只要把生产机的 gem 源指向到这里,就可以实现安装加速。我们第一个 gem stash 的 RC 版将会发布于——今晚(笑),耶!超给力!

