-
Ruby China API V3 获取 token 失败 at 2015年06月04日
使用 curl 获取:
curl -X POST -d "grant_type=password" -d "username=[name]" -d "password=[pass]" 'https://ruby-china.org/oauth/token'* Adding handle: conn: 0x7fd1b280aa00 * Adding handle: send: 0 * Adding handle: recv: 0 * Curl_addHandleToPipeline: length: 1 * - Conn 0 (0x7fd1b280aa00) send_pipe: 1, recv_pipe: 0 * About to connect() to ruby-china.org port 443 (#0) * Trying 61.174.15.167... * Connected to ruby-china.org (61.174.15.167) port 443 (#0) * TLS 1.2 connection using TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA384 * Server certificate: www.ruby-china.org * Server certificate: StartCom Class 1 Primary Intermediate Server CA * Server certificate: StartCom Certification Authority > POST /oauth/token HTTP/1.1 > User-Agent: curl/7.30.0 > Host: ruby-china.org > Accept: */* > Content-Length: 70 > Content-Type: application/x-www-form-urlencoded > * upload completely sent off: 70 out of 70 bytes < HTTP/1.1 200 OK * Server nginx/1.8.0 is not blacklisted < Server: nginx/1.8.0 < Date: Thu, 04 Jun 2015 05:13:35 GMT < Content-Type: application/json; charset=utf-8 < Transfer-Encoding: chunked < Connection: keep-alive < Strict-Transport-Security: max-age=31536000 < X-Frame-Options: SAMEORIGIN < X-XSS-Protection: 1; mode=block < X-Content-Type-Options: nosniff < Cache-Control: no-store < Pragma: no-cache < ETag: W/"5275890161f17844e4dffefe6e643344" < X-Request-Id: 9d8e536c-3fb6-456e-a3b1-8f88a9799a77 < X-Runtime: 0.296195 < * Connection #0 to host ruby-china.org left intact {"access_token":"xxxxxxxx","token_type":"bearer","expires_in":86400,"refresh_token":"xxxxxxxxxx","created_at":1433394815} -
RubyMine 调试代码速度太慢了,有没有解决方案 at 2015年05月28日
很少进行 Ruby 代码的 Debug, 一般跑测试验证。
-
请教关于 Ember.js 中如何把 Nested Routes 加载到同一个模板的问题 at 2015年05月08日
@aidewoode 如果需要在
/posts/1的页面里面查看 post 和分页的 comments 你的 URL 应该需要/posts/1/comments?page=N这种形式了这样你的 Router 就是你上面写的那样,而同时你需要手动准备
- PostsCommentsRouter : 在这个里面准备你关于某个 post 的 comments 数据
- PostsCommentsController : 在这里准备 template 里面的事件和需要收集的参数。
- template/posts/comments.hbs : 这个与对应的 controller 对应使用。
这样设计 API 可能有点怪怪的,例如:你查看 topic 的 comments 理想的是 /topic/1 查看 topic 和这个 topic 的 comments, 要查看分页的 comments 会是 /topic/1?page=2 这样。
我说区分 front 和 backend 的意思是,其实 Ember 提供 双向绑定 的好处就是,你可以不用理睬 template 改如何展示你的 model 数据,因为 Ember 让你的数据在前端是"活"的,只要 Ember 所绑定的 data/model 发生变化 template 就会自动的变化,而这个思维与 backend 中的数据变化则一定需要重新 get 一个页面不太一样。
另外,我猜测你应该还是使用了 Ember-Data, 而 Ember-Data 中对于分页功能现在还没有尘埃落定 (我们看起来简单,实现起来还是有他们的难度) 参看两个 issue #1517 #2095 所以现在的意思就是,如果我们要做分页,还得自己想想办法,当渲染了 posts 后,在 PostsController 或者 PostsRouter 中自己再重新提交请求向 backend 要分页的 comments 数据,再 push 到 store 中让 Ember 自动处理变化的数据. (你会发现 Discourse 的分页取巧了,给了总个数,但没有给页码,而且是一直拖拽加载不是分页加载。当然这种形式也挺适合他们的需求)
-
请教关于 Ember.js 中如何把 Nested Routes 加载到同一个模板的问题 at 2015年05月07日
你得区分一下 front 和 backend. 前端是不同的页面通过 route 在跳转,而在 ember router 中准备数据. 你可以这样思考:
- PostRouter 中就加载好 posts 的第一页的 comments
- 写好 template 然后利用 {{render}} 传入 model
- 分页的操作在按照道理应该在 PostRouter 中的 actions 处理,远程加载数据。
{{render}} helper 的特点在文档中有写:
{{render}} does several things: * When no model is provided it gets the singleton instance of the corresponding controller * When a model is provided it gets a unique instance of the corresponding controller * Renders the named template using this controller * Sets the model of the corresponding controller当然你这个特点应该将 {{render}} 换为使用 {{partial}} , 只是部分 comments 的 html 片段不一样,但是上下文中使用的 model 是一样的, 所以第二步中可以
- 在 template 中使用 {{partial 'comments'}} 不用传递当前 template 所对应的 controller 上下文中的 model, 他会自动拥有这个 context 可以直接使用
- 最好将 partial 使用的 template 使用 "_" 开头 (类似 rails 中的 partial html 命名). 例如:_comments.hbs , 里面就直接
{{#each post.comments as |comment|}}使用就好
{{partial}} 寻找的几个特点在文档中也有写:
* The partial helper renders another template without changing the template context * If a "_nav" template isn't found, the partial helper will fall back to a template named "nav". ({{partial "nav"}}) * The parameter supplied to partial can also be a path to a property containing a template name -
Ruby VS Scala at 2015年05月05日
scala 的编译时间让我挺难受的...
-
现在可以关注人了 at 2015年04月22日
-
Self Hosted Gem Server at 2015年04月13日
docker 用起来好方便~
-
Rust 发布 1.0 Beta at 2015年04月07日
了解过后,我头大了两圈....... 还是实用主义好
-
Google 产品全面撤销 CNNIC 根证书 at 2015年04月02日
好,支持,威武,有希望了!
-
[电子商务] 商品属性筛选问题 at 2015年03月12日
这种问题,可以考虑 MySQL 之外的解决方案。因为这种搜索方案会越来越复杂。考虑使用 ElasticSearch 的全文索引方案, {key: value} 的属性匹配搜索会高效很多。
-
新版 MacBook 完全没风扇了 at 2015年03月10日
便携办公型呀~
-
希望懂 Grape 构建 API 的朋友进来聊一下 at 2015年03月03日
@bluesky0318 Grape 的问题完全可以在 Grape Github 上找到答案。
但另外,如果是附件管理的 API 到可以看看 Kod Explorer
-
推荐个 商城的开源项目? at 2015年02月25日
php 的话 prestashop 也可以,结构挺清晰,一条主处理流程,挂接很多 hook 插入功能。但 hook 多了也有点烧脑...
-
选用哪种 url 风格比较好? at 2015年02月12日
浏览器根据编码规则解析的
-
异步多服务器任务操作框架 at 2015年01月16日
@linjunhalida 我倒认为得看具体需要完成的任务情况了,如果在现有的模型下出现的问题,业务出现的问题的复杂程度是在能够接受的范围内,我到觉得是一个可行方案。另外对中间出现了错误查看中间状态的情况,同样可以有好的处理方法,(理想一点哈) 任何环节都可能出现问题,那你可以在任何环节针对出现的问题对任务回滚以及异常信息集中报告处理,让错误及早发现清空任务所有已做任务,让任务做到等幂性质可重复执行~ 这些都是可控的,当然也是有开发代价的。
拥有主进程控制的方法,让我想到类似 "microservices", 主方法不断的调用其他系统所提供的服务接口即可,出现问题各自服务记录 (可汇总到 airbrake 类似产品), 可同时返回错误信息主控制进程报告等等。
另外,主进程方法是否合适,还得考虑业务的忍受程度~ 总不能让这个主进程挂个 1 小时吧?这 1 小时带来的问题风险也不小呀?
-
异步多服务器任务操作框架 at 2015年01月16日
Sidekiq , 不同的服务器上监听不同的任务队列,然后信息通过 redis 队列中的任务参数传过去 (尽量为字符串类型的参数).
这样,不同的 queue1 -> queue2 -> queue3 -> queue4 可以一次传递下去,并且可以在任何一个 queue 的环节控制是否往下一个 queue 中发任务或者向另外一个 queue 发任务。
-
InfluxDB + Grafana 快速搭建自己的 NewRelic,分析应用运行情况 at 2014年12月30日
这个方案好!小巧玲珑~
-
单机数据抓取性能提升总结篇 at 2014年12月12日
#22 楼 @michael_roshen 得科学上网...
-
单机数据抓取性能提升总结篇 at 2014年12月12日
#13 楼 @michael_roshen "sidekiq 多线程怎么搞,没查到相关资料" => 看下介绍哈 应该可以解决你的问题。
-
单机数据抓取性能提升总结篇 at 2014年12月12日
-
单机数据抓取性能提升总结篇 at 2014年12月12日
-
单机数据抓取性能提升总结篇 at 2014年12月10日
我就觉得你不用太压榨一台服务器的性能。这 Sidekiq + Redis + Docker 的存在,让你横向扩展太方便了. 我们类似的业务,横向 Docker 上去 14 台抓取,一天更新 200w ~300w 的数据 (有效更新数据,抓取的数据不止这么多哈).
就是被对方当机器人有点麻烦...
-
nokogir 规则匹配的一个小问题 at 2014年12月10日
-
jekyll 相关的问题 at 2014年12月02日
"_site 这个目录是干嘛用的?" => Directory structure
"URL 的问题" => Permalinks
"如何去除 ajax google api 的 http request" 参看 Directory structure 中的 "_layout" 与 "_includes"
应该能解决你的问题。
-
公司目前部署在 Heroku 上,接下来想要更照顾内地 traffic,考虑换服务器,求教建议 at 2014年11月20日
- Linode.com 服务器最便宜的 10 美金一个月。服务很稳定。
- DC 的新加坡机房没有使用过哈~ 考虑 DC 新加坡,也可再增加一个候选,可以考虑 vultr.com (带尾巴) 3,4 Softlayer, Rackspace 都算很稳定的服务提供商,但是相比 Linode , 这两家才是真的贵。
在任何服务器上部署 Rails 都应该差不多吧~ 论坛里面有一个 wiki 可参考
因为在大陆有 weird things , Heroku 被照顾到了~
如果要优化大陆速度,将服务部署在大陆肯定是最好的,不过需要域名备案
-
Udemy 上的课程促销全部是 $10 截止到 11.28 at 2014年11月20日
我在想是不是被我们的 11.11 给震撼到了,然后也开始尝试这样的超低打折促销~
-
JAXB 比起 Nokogiri 真是太难用了。。。 at 2014年10月14日
jaxb 不是单独拿来解析 xml 的,他是用来处理 Java 的 Object 对象与 XML 文件映射对应绑定的。
Nokogiri 是用于解析 xml 文件的,但他无法处理 对象与 xml 之间的绑定问题。
-
ruby 里面如何输出系统变量 at 2014年08月27日
-
[投票] ruby.taobao.org 是否要 proxy rubygems 的 API 请求 at 2014年08月06日
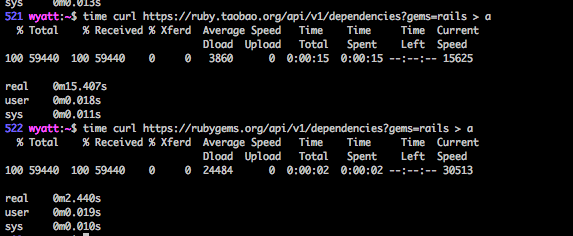
额,这个没来得及注意啊.... 刚刚对比了下 API Proxy 的速度,给一个数据。(湖南长沙,8M 电信)
-
Grape 有没有 Pretty-print 的选项? at 2014年08月01日
@yukihiro_matz 在 Grape 中处理请求的过程中,找个合适的地方使用类似下面的代码试一试