Go 用 500 行 Golang 代码实现高性能的消息回调中间件
用 500 行 Golang 代码实现高性能的消息回调中间件
本文描述了如何实现一个消息回调中间件,得益于 golang 管道和协程的编程思想,通过巧妙的设计,只需要约 500 行代码就可以实现高性能、优雅关闭、自动重连等特性,全部代码也已经开源在 github/fishtrip/watchman。
问题
随着业务复杂度的增加,服务拆分后服务数量不断增加,异步消息队列的引入是必不可少的。当服务较少的时候,比如业务早期,很多时候就是一个比较大的单体应用或者少量几个服务,消息队列(之后写做 MQ,Message Queue)的使用方法如下:
- 发送端,直接连接 MQ,根据业务需求发送消息;
- 消费端,通过一个后台进程,通过长连接连接至 MQ,然后实时消费消息,然后进行相应的处理;
相对来说,发送端比较简单,消费端比较复杂,需要处理的逻辑比较多。比如目前我们公司使用的 sneakers 需要处理如下的逻辑:
- 消费端需要长连接,需要独立的进程实时消费消息(某些语言可能是一个独立的线程);
- 消费消息之后,需要加载业务框架(比如 Sneakers 需要加入 Rails 环境执行业务代码)调用相关代码来消费消息;
- MQ 无法连接时,需要自动重连,同时应用也需要能够优雅重启,不至于丢消息。
- 消费消息很可能处理失败,这个时候需要比较安全可靠的机制保证不能丢失消息,同时也要求能够过一段时间对消息进行重试,重试多次之后也需要能够对消息进一步做处理;
这个时候的系统架构一般如下:
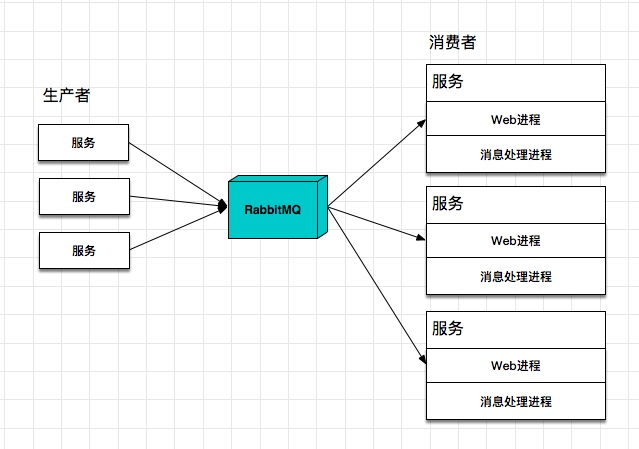
而随着服务增多,如果每个需要消费消息的服务都部署一个这样的后台进程显然不够环保:
- 每个服务增加一个进程,增加了部署运维的成本;
- 对于队列的管理(创建、销毁、binding)以及消息重试机制,每个服务来自己负责的话,很容易造成标准不统一;
- 如果不同的服务是不同的语言、不同的框架,每个语言又都要实现一遍,会浪费不少开发资源;
那有没有更好的办法呢?
其中一般办法是打造一个全局的、高性能的消息回调中间件,中间件来负责队列的管理、消息的收发、重试以及出错处理,这样就不再需要每个服务去考虑诸如消息丢失、消息重试等问题了,基本解决了上面的缺点。具体这个消息回调中心应该具备哪些功能呢?
- 统一管理所有 MQ 队列的创建和消息监听;
- 当有消息接收到时,中间件调用相关服务的回调地址,因为回调中心负责所有的服务,该中间件必须是高性能、高并发的;
- 中间件应当具备消息重试的功能,同时重试消息的时候不应该丢失消息;
- 中间件应当具备「重连」和「优雅关闭」等基础功能,这样才能保证不丢消息;
这时候架构如下:
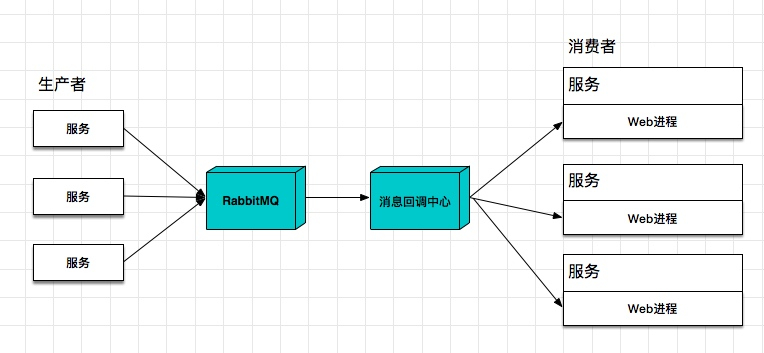
这样的话,每个服务的工作就变得轻量了很多。本文的目的就是来实现一版生产环境可用的消息回调中间件。当然,我们第一版的回调中心也不需要太多功能,有如下的限制:
- 整个重试流程需要 RabbitMQ 内置功能支持,所以暂时只支持 RabbitMQ;
- 目前只支持 HTTP 回调方式;
基本的需求有了,如何实现一个这样的消息回调中间件呢?
解决思路
开发语言选择
Golang 作为「系统级开发语言」,非常适合开发这类中间件。内建的 goroutine/channel 机制非常容易实现高并发。而作为 Golang 新手,这个项目也不复杂,很适合练手和进一步学习。
消息可靠性
关于重试和出错处理呢?我们从 Sneakers 的实现中借鉴了它的方法,通过利用 RabbitMQ 内置的机制,也就是通过 x-dead-letter 机制来保证消息在重试时可以做到高可靠性,具体可以参考前段时间我写的这篇文章。简单总结一下文中的思路:
- 消息正常被处理时,直接 ack 消息就好;
- 当消息处理出错,需要重试时,reject 消息,此时消息会进入到单独的 retry 队列;
- retry 队列配置好了 ttl 超时时间,等到超时时,消息会进入到 requeue Exchange(RabbitMQ 的概念,用来做消息的路由);
- 消息会再次进入工作队列,等待被下次重试;
- 如果消息的重试次数超过了一定的值,那么消息会进入到错误队列等待进一步处理;
这里面有两个地方利用了 RabbitMQ 的 Dead-Letter 机制:
- 当消息被 reject 之后,消息进入到该队列的 dead-letter Exchange,也就是重试队列;
- 当重试队列的消息,在超时时(队列设置了 ttl-expires 时长),消息进入该队列的 dead-letter Exchange,也就是重新进入了工作队列。
通过这种机制,可以保证在进行消息处理的时候,不管是正常、还是出错时,消息都不会丢失。关于这里进一步的细节可以参考上面的文章。
实现高并发
对于中间件,性能的要求比较高,性能也包含两个方面:低延迟和高并发。低延迟在这个场景中我们无法解决,因为一个消息回调之后的延迟是其他业务服务决定的。所以我们更多的是追求高并发。
如何获得高并发?首先是开发语言的选择,这类底层的中间件很适合用 Golang 来实现,为什么呢?因为回调中心的主逻辑就是不断回调各个服务,而各个服务的延迟时间中间件无法控制,所以如果想获得高并发,最好是使用异步事件这种机制。而借助于 Golang 内置的 Channel,既可以获得接近于异步事件的性能,又可以让整个开发变得简单高效,是一个比较合适的选择。
具体实现呢?其实对于一个回调中心来说,大概分成这么几个步骤:
- 获取消息:连接消息队列(目前我们只需要支持 RabbitMQ 即可),消费消息;
- 回调业务接口:消费消息之后,根据配置信息,不同的队列可能需要调用不同的回调地址,开始调用业务接口(目前我们只需要支持 HTTP 协议即可);
- 根据回调结果处理消息:如果调用业务接口如果成功,则直接 ack 消息即可;如果调用失败,则 reject 此消息;如果超过最大重试次数,则进入出错处理逻辑;
- 出错处理逻辑:把原有消息 ack,同时转发此消息进入 error 队列,等待进一步处理(可能是报警,然后人工处理);
通过消息这么一个「实体」可以把所有上面的流程串联起来,是不是很像 pipeline?而 pipeline 的设计模式是 Golang 非常推荐的实现高并发的方式。上面的每一个步骤可以看做一组协程(goroutine),他们之间通过管道通信,因此不存在资源竞争的情况,大大降低了开发成本。
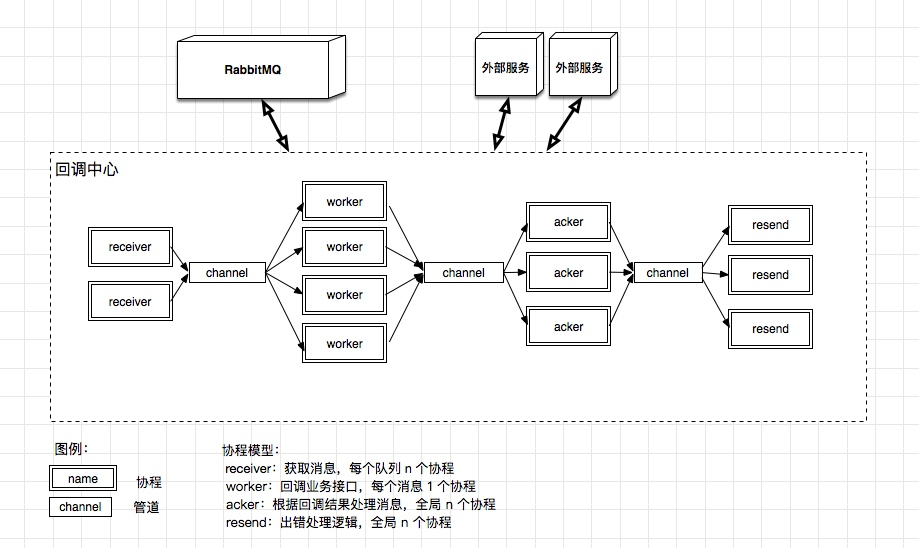
而上面每个步骤可以通过设计不同的 Goroutine 模型来实现高并发:
- 获取消息:需要长连接 RabbitMQ,较好的实现方式是每个队列有独立的一组协程,这样队列之间的消息接受互相不会干扰,如果出现了繁忙队列和较闲的队列时,也不会出现消息处理不及时的情况;
- 回调业务接口:每个消息都会调用业务接口,但是业务接口的处理时长对于中间件来说是透明的。因此,这里最好的模型是每个消息一个协程。如果出现了较慢的接口,那么通过 goroutine 的内部调度机制,并不会影响系统的吞吐,同时 goroutine 可以支持上百万的并发,因此用这种模式最合适。
- 根据回调结果处理消息:这个步骤主要是要连接 RabbitMQ,发送 ack/reject 消息。默认我们认为 RabbitMQ 是可靠的,这里统一用同一组协程来处理即可。
- 出错处理逻辑:这里的消息量应该大大降低,因为多次失败(超过重试次数)的消息才会进入到这里。我们也采用同一组协程处理即可。
上面四个步骤,我们用了三种协程的设计模型,细化一下上面的图就是这个样子的。
实现
有了上面的设计过程,代码并不复杂,大概分为几部分:配置管理、主流程、消息对象、重试逻辑以及优雅关闭等的实现。详细的代码放在 github:fishtrip/watchman
配置管理
配置管理这部分,这个版本我们实现的比较简单,就是读取 yml 配置文件。配置文件主要包含的主要是三部分信息:
- 消息队列定义。要根据消息队列的配置调用 RabbitMQ 接口生成相关的队列(重试队列、错误队列等);
- 回调地址配置。不同的消息队列需要不同的回调地址;
- 其他配置。如重试次数、超时等。
# config/queues.example.yml
projects:
- name: test
queues_default:
notify_base: "http://localhost:8080"
notify_timeout: 5
retry_times: 40
retry_duration: 300
binding_exchange: fishtrip
queues:
- queue_name: "order_processor"
notify_path: "/orders/notify"
routing_key:
- "order.state.created"
- "house.state.#"
我们使用 yaml.v2 包可以很方便的解析 yaml 配置文件到 struct 之中,比如对于 queue 的定义,struct 实现如下:
// config.go 28-38
type QueueConfig struct {
QueueName string `yaml:"queue_name"`
RoutingKey []string `yaml:"routing_key"`
NotifyPath string `yaml:"notify_path"`
NotifyTimeout int `yaml:"notify_timeout"`
RetryTimes int `yaml:"retry_times"`
RetryDuration int `yaml:"retry_duration"`
BindingExchange string `yaml:"binding_exchange"`
project *ProjectConfig
}
上面之所以需要一个 ProjectConfig 的指针,主要是为了方便读取 project 的配置,因此加载的时候需要把队列指向 project。
// config.go
func loadQueuesConfig(configFileName string, allQueues []*QueueConfig) []*QueueConfig {
// ......
projects := projectsConfig.Projects
for i, project := range projects {
log.Printf("find project: %s", project.Name)
// 这里不能写作 queue := project.Queues
queues := projects[i].Queues
for j, queue := range queues {
log.Printf("find queue: %v", queue)
// 这里不能写作 queues[j].project = &queue
queues[j].project = &projects[i]
allQueues = append(allQueues, &queues[j])
}
}
// .......
}
上面代码中有个地方容易出错,就是在 for 循环内部设置指针的时候不能直接使用 queue 变量,因为此时获取的 queue 变量是一份复制出来的数据,并不是原始数据。
另外,config.go 中大部分逻辑是按照面向对象的思考方式来书写的,比如:
// config.go
func (qc QueueConfig) ErrorQueueName() string {
return fmt.Sprintf("%s-error", qc.QueueName)
}
func (qc QueueConfig) WorkerExchangeName() string {
if qc.BindingExchange == "" {
return qc.project.QueuesDefaultConfig.BindingExchange
}
return qc.BindingExchange
}
通过这种方式,可以写出更清晰可维护的代码。
消息对象封装
整个程序中,在 channel 中传递的数据都是 Message 对象,通过这种对象封装,可以非常方便的在各种类型的 Goroutine 之间传递数据。
Message 类的定义如下:
type Message struct {
queueConfig QueueConfig // 消息来自于哪个队列
amqpDelivery *amqp.Delivery // RabbitMQ 的消息封装
notifyResponse NotifyResponse // 消息回调结果
}
我们把 RabbitMQ 中的原生消息以及队列信息、回调结果封装在一起,通过这种方式把 Message 对象在管道之间传递。同时 Message 封装了众多的方法来供其他协程方便的调用。
// Message 相关方法
func (m Message) CurrentMessageRetries() int {}
func (m *Message) Notify(client *http.Client) *Message {}
func (m Message) IsMaxRetry() bool {}
func (m Message) IsNotifySuccess() bool {}
func (m Message) Ack() error {}
func (m Message) Reject() error {}
func (m Message) Republish(out chan<- Message) error {}
func (m Message) CloneAndPublish(channel *amqp.Channel) error {}
注意上面方法的接收对象,带指针的接收对象表示会修改对象的值。
主流程
主流程就是我们上面说的,通过 pipeline 的模式、把消息的整条流程串联起来。最核心的代码在这里:
// main.go
<-resendMessage(ackMessage(workMessage(receiveMessage(allQueues, done))))
上面每个函数都接收相同的管道定义,因此可以串联使用。其实每个函数的实现区别不大,不同的协程模型可能需要不同的写法。
下面是 receiveMessage 的写法,并进行了详细的注释。revceiveMessage 对每个消息队列都生成了 N 个协程,然后把读取的消息全部写入管道。
// main.go
func receiveMessage(queues []*QueueConfig, done <-chan struct{}) <-chan Message {
// 创建一个管道,这个管道会作为函数的返回值
out := make(chan Message, ChannelBufferLength)
// WaitGroup 用于同步,这里来控制协程是否结束
var wg sync.WaitGroup
// 入参是队列配置,这个见下文传入的值
receiver := func(qc QueueConfig) {
defer wg.Done()
// RECONNECT 标记用于跳出循环来重新连接 RabbitMQ
RECONNECT:
for {
_, channel, err := setupChannel()
if err != nil {
PanicOnError(err)
}
// 消费消息
msgs, err := channel.Consume(
qc.WorkerQueueName(), // queue
"", // consumer
false, // auto-ack
false, // exclusive
false, // no-local
false, // no-wait
nil, // args
)
PanicOnError(err)
for {
select {
case msg, ok := <-msgs:
if !ok {
log.Printf("receiver: channel is closed, maybe lost connection")
time.Sleep(5 * time.Second)
continue RECONNECT
}
// 这里生成消息的 UUID,用来跟踪整个消息流,稍后会解释
msg.MessageId = fmt.Sprintf("%s", uuid.NewV4())
message := Message{qc, &msg, 0}
// 这里把消息写到出管道
out <- message
message.Printf("receiver: received msg")
case <-done:
// 当主协程收到 done 信号的时候,自己也退出
log.Printf("receiver: received a done signal")
return
}
}
}
}
for _, queue := range queues {
wg.Add(ReceiverNum)
for i := 0; i < ReceiverNum; i++ {
// 每个队列生成 N 个协程共同消费
go receiver(*queue)
}
}
// 控制协程,当所有的消费协程退出时,出口管道也需要关闭,通知下游协程
go func() {
wg.Wait()
log.Printf("all receiver is done, closing channel")
close(out)
}()
return out
}
里面有几个关键点需要注意。
- 每个函数都是类似的结构,一组工作协程和协作协程,当全部工作协程退出时,关闭出口管道,通知下游协程。注意 golang 中,对于管道的使用,需要从写入端关闭,否则很容易出现崩溃。
- 我们在每个消息中,记录了一个唯一的 uuid,这个 uuid 用来打日志,来跟踪一整条信息流。
- 因为可能出现的网络状况,我们要进行判断,如果出现了连接失败的情况,直接 sleep 一段时间,然后重连。
- done 这个管道是在主协程进行控制的,主要用作优雅关闭。优雅关闭的作用是在升级配置、升级主程序的时候可以保证不丢消息(等待消息真的完成之后才会结束协程,整个程序才会退出)。
总结
得益于 Golang 的高效的表达能力,通过大约 500 行代码实现了一个稳定的消息回调中间件,同时具备下面的特性:
- 高性能。在 macbook pro 15 上简单测试,每个队列的处理能力可以轻松达到 3000 message/second 以上,多个队列也可以做到线性的增加性能,整体应用达到几万每秒很轻松。同时,得益于 golang 的协程设计,如果下游出现了慢调用,那么也不会影响并发。
- 优雅关闭。通过对信号的监听,整个程序可以在不丢消息的情况下优雅关闭,利于配置更改和程序重启。这个在生产环境非常重要。
- 自动重连。当 RabbitMQ 服务无法连接的时候,应用可以自动重连。
当然,我们团队目前还都是 golang 新手,也没有做太多的单元测试和性能测试,下一步可能会继续优化,完善测试工作,并且优化配置的管理,欢迎各位去 github 围观源码。
 提供两个 tips:
提供两个 tips: 