-
工作也旅行 - 工作日常 at September 03, 2015
照片真漂亮,工作环境如诗如画。
-
想做一个个人博客,域名已经买了,部署在哪里比较好,不想备案 at August 28, 2015
赞这句话:
无数人在这里纠结怎么做一个博客,怎么部署一个博客,其实这些形式都不重要,写才最重要,看看大牛的博客就懂我想说什么了
推荐作者用 Github Pages 搭建 blog,最好不要折腾样式,纯属浪费时间。
-
[上海][2015年9月8日] Ruby 聚会召集 at August 27, 2015
-
[上海][2015年9月8日] Ruby 聚会召集 at August 26, 2015
Hi Johnson,感谢你抽出时间组织上海的 ruby tuesday。
由于最近娃要出生,没空参加活动,无法和你面谈。在以往的聚会中我们会提前准备:
- 投影仪
- 2 米插线板
- 联系讲师,准备一个 30 到 40 分钟的 topic。
此外聚会时的大体流程
- 介绍新朋友和老面孔
- 分享 topic
- 与 speaker 问答
- 聊天、扯淡、招聘 等等。
供参考。
-
[Rubyist 少数派调查] 你喜欢经典神器,还是走在时代尖端? at August 21, 2015
我选了重大决策按钮,哈哈。
顺便请教,oneapm 比 newrelic 有啥优势?
-
咨询一个 Ruby 的 socket 监听的问题 at August 18, 2015
1. Lifecycle of TCP socket client
- create socket
- bind(if you skip this step, system will defaultly bind a ephemeral port to connect server.)
- connect
- close
2. This example is verbose but easy to understand
require 'socket' # step1 create socket = Socket.new(:INET, :STREAM) # step2 bind(skip) # step3 connect remote_addr = Socket.pack_sockaddr_in(80, 'google.com') socket.connect(remote_addr) while data = socket.readpartial(one_hundred_kb) do puts data end # step4 close socket.close3. stackoverflow 上一个很好范例
http://stackoverflow.com/questions/8649860/ruby-tcpsocket-http-request
4. 一本很好的关于 Tcp socket 的通俗易懂的书
[book] Working with TCP Sockets
大便时遇到这个问题,顺便回一下。
-
咨询一个 Ruby 的 socket 监听的问题 at August 18, 2015
socket.read是个 block 的操作,如果 server 没有返回 eof,客户端不会打印出任何东西。所以应该使用 partial read 来替代 read。
-
Rails 到底该选择什么 server at August 16, 2015
-
这是我读过关于 constant lookup 讲的最好的文章,不要问我为什么 at August 12, 2015
感谢楼主的精彩分享,这篇文章确实极其精彩,我刚好这两天也在反复的读,特此补充,哈哈。
补充 1

这个地方翻译欠妥。查找常量时 Module.nesting 并不是当前的代码定义的 class。
Ruby 有三种 context
self 当前对象
definee 当前类
lexical scope
作者在此处指的是第三种 context:lexical scope。lexical scope 只和 class 和 module 这两个 keyword 有关。
所以作者最后的结论是两个:
Module.nesting 取决于 lexical scope
lexical scope 只取决于 class、module 两个关键字。(和 class_eval、instance_eval 无关)
补充 2
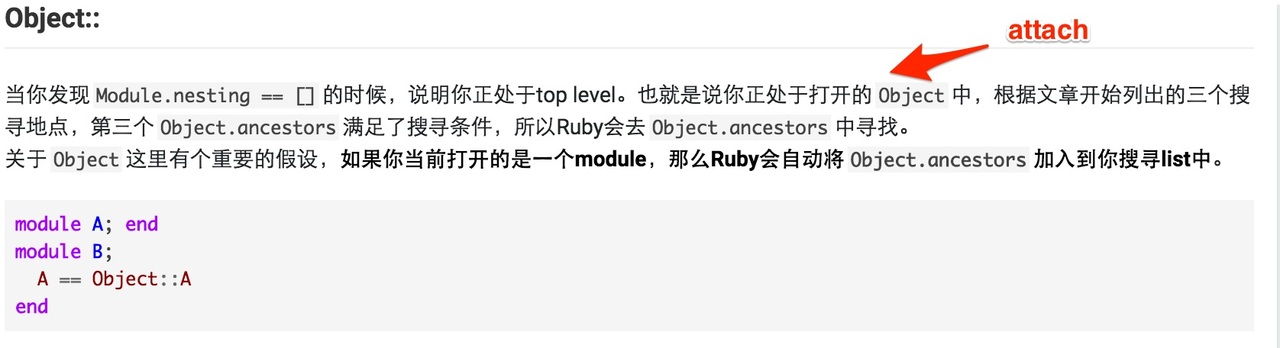
原文用的 attach Object,不是 Open Object,此处确实很难翻译。
class C end在顶级定义一个类 C 时,是把 C 这个常量 attach 到
Object这个 Rclass 的 constant table 中。 -
征集大家意见,关于回帖用树形方式展示,类似 HackerNews at August 10, 2015

花里胡哨的感觉。
-
[上海][2015年8月11日] Ruby 聚会召集 at August 09, 2015
-
Common Network Exception in Ruby (1) at August 06, 2015
-
Common Network Exception in Ruby (1) at August 06, 2015
请教一个问题
require 'socket' local_socket = Socket.new(:INET, :STREAM) local_addr = Socket.pack_sockaddr_in(4481, '0.0.0.0') local_socket.bind(local_addr) server.listen(Socket::SOMAXCONN) # accept a connection connection, remote_addr = server.accept建立连接后,connection 是一个 Socket 对象,instance_variable 是空的,local_address/remote_address 是保存在哪里呢?
> connection.instance_variables > [] > p connection.local_address Local address: #<Addrinfo: 0.0.0.0:4481 TCP> > p connection.remote_address Remote address #<Addrinfo: 59.102.12.1:4481 TCP> -
[12 台减至 3 台] 用 Golang 重写 Sidekiq 的 worker at August 06, 2015
同问,
为啥不考虑 jruby?
如果用 golang 重写的话,所有的业务逻辑是不是都要重新实现一遍?而且要和 Rails 中的业务逻辑始终保持一致,维护的工作量是不是有点大?
-
Common Network Exception in Ruby (1) at August 05, 2015
哈哈,我来抢沙发。
-
提高 Ruby 程序员效率的 rc 文件 at August 05, 2015
-
提高 Ruby 程序员效率的 rc 文件 at August 05, 2015
这和标题不符啊,哈哈。
-
which ruby at July 31, 2015
shell: $PATH
Ruby: $LOAD_PATH他们的用途好像啊
-
做排行榜功能根本没头绪,谁能给点提示 <-- -->...... at July 30, 2015
果断 redis 的 zset 哇。
-
利用 Mina 自动部署 Rails + Sidekiq + Unicorn at July 28, 2015
请问 mina 到底比 cap 快在哪些地方?
一些比较慢的操作是不可避免的呀。
比如每次部署最耗时间的部分 assets compile 是逃不过去的呀?
-
Gemfile 详解 at July 28, 2015
这篇文章又系统,又通俗,真是篇好文章。
-
测试 DB Index 单 column index 和多 column 联合索引的疑问 at July 27, 2015
可以在本机造一亿条假数据,索引之间的差异会拉大。此外
SET SESSION query_cache_type=0;可以在当前连接的 session 关闭缓存。如何在 4 分钟内创建一亿条 mysql 假数据( @vincent 教我的,哈哈)
Without creating a stored procedure, one technique I've applied is to use the table itself to add the columns. First seed it with a value...
insert into table_name ( column1, column2, column3, column4 ) values ( 1, 2, 3, 4 );Then insert again, selecting from this table to double the rows each time...
insert into table_name ( column1, column2, column3, uuid) select round( rand()*10000), 0, 0, UUID() from rand_numbers;You don't need to run the second query that many times to get quite a few random rows. Not as "neat" as using a stored procedure of course, just proposing an alternative.
-
测试 DB Index 单 column index 和多 column 联合索引的疑问 at July 27, 2015
client_type 和 status 的值的种类都很少
client_type
- BlackBerryDevice
- iPhone
- iPad
status
- 1
- 2
某个字段的值特异度很低的情况下,建索引比起全表扫描节省不了多少时间。所以我的看法是,这个字段的索引没啥用。
炮哥,你怎么看?
@ hooopo
-
大家是如何学习 ruby 的 at July 27, 2015
找个 ruby 工作,跟着大牛一步步学
-
今年大会延期至 10月10日-11日 at July 27, 2015
无所谓,都行
-
如果要对 Ruby 程序员的 Ruby 水平分等级,你觉得要怎么评定? at July 23, 2015
- 对公司技术氛围的贡献(带领新人,分担管理压力)
- 对公司业务的贡献(commit 数量)
- 对社区的贡献(招人时一呼百应)
- 元编程(基础扎实,会造轮子)
- web 框架(对 rails 的熟悉度)
- 精通数据库(各种数据库的应用场景)
- 过去做过的业务多(再开发重复产品时速度快)
- 计算机基础好(学习速度快)
我觉可以从这么几个角度来打分。
-
[上海] SAP 招聘 Ruby 高级工程师 at July 21, 2015
-
[上海] SAP 招聘 Ruby 高级工程师 at July 20, 2015
-
MySQL 为什么需要一个主键 at July 18, 2015
if there is no primary key, innodb will create a hidden column as primary key, and cluster rows on it
-
Ruby on Rails 学习资源整理 (欢迎补充) at July 17, 2015
我喜欢打击人,哈哈。
你收集完了这些资源后,花了多少时间去学习这些课程?
