-
FQ 赚外快获得的收益属于"非法所得"吗 at 2023年09月27日
个税肯定是要补的,但是和公安局应该没关系,是税务局的事。
给远程办公者的一个税务筹划小建议:
大街上的包子铺,洗脚店,五金店,文具店,都是个体户。二三线小城市的独立开发者,非常容易注册个体户,可以注册“龙漕路王大虎电脑维修软件工作室”,然后按照核定征收的方式给税务局交税。
- 不需要在银行开立对公账户。
- 不需要账本,也不需要记账,省时省力。
- 按照核定征收交税,每个月几万的流水,只有几百块钱的税,非常划算。
参考资料:
-
FQ 赚外快获得的收益属于"非法所得"吗 at 2023年09月27日
有个人坐地铁去上班,天天逃票。某一天地铁乘务员逮住他了,把他上班的工资全部没收了。
-
RubyConf China 2023 主题介绍 at 2023年06月30日
好期待!
-
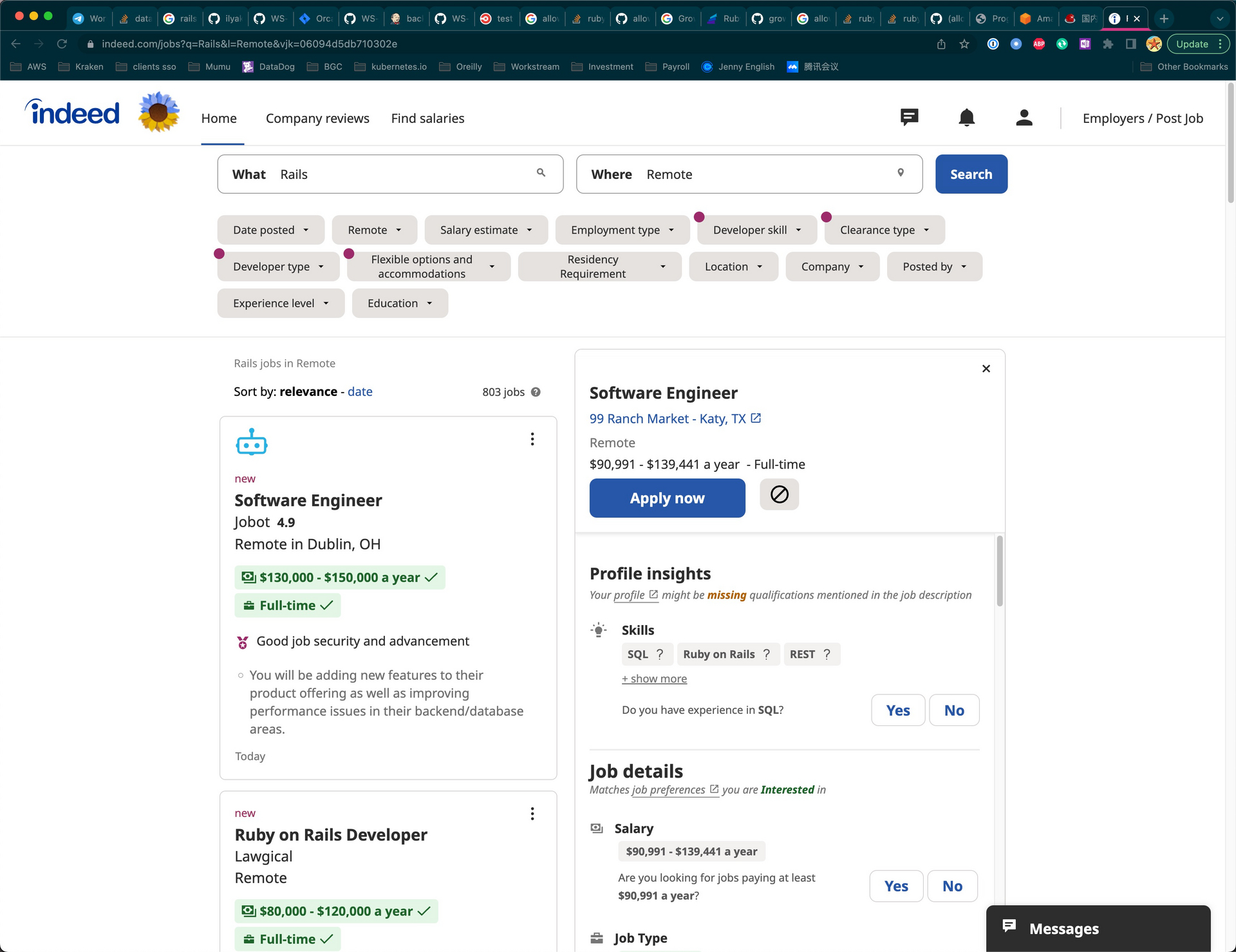
国内 Rails 的工作机会还有多少? at 2023年05月11日
别在一棵树上吊死,你可以看一下海外的岗位。去 indeed us 上去找国外的 rails remote 工作,一搜一大把。
https://www.indeed.com/jobs?q=Rails&l=Remote&vjk=06094d5db710302e
-
为什么感觉国内很多 app 界面做得很生硬? at 2023年04月28日
你的标题包含的逻辑关系:
- 国内很多 app 界面做得很生硬,国外不生硬,中国的设计差。
- 为什么?
第一点你预设了是事实,但有可能并不是事实。
糟糕的设计每个国家都有,和国籍没关系。
此外目标用户不同,设计风格也不同,符合目标用户的设计才是好的设计。
有些设计的丑陋,是为了照顾更广泛的用户群。facebook 用蓝色风格,死板,但是照顾了色盲的用户。
第二点是对第一点的延伸,如果第一点都不是事实,第二点都没有必要讨论。
-
求职一份上海的坐班工作 at 2023年04月24日
[管理员通知] 社区里不允许张贴小广告的求职贴。
建议楼主简单的介绍一下
自己的基本情况
自己做过的项目
自己掌握的技术
求职意向,哪个方向
自己的 github 或 stackoverflow,或 blog
这样既展现了自己的实力,也节省招聘方的时间。
如果怕泄露隐私,可以抹掉个人信息,比如姓名,手机号。
-
写代码的时候不能专注怎么办? at 2023年04月23日
上班时间,我用这个软件把分心的网站和 app 都屏蔽了。https://heyfocus.com/
手机设置了 screen time,每天就玩微信一个小时,避免社交工具上瘾。
程序员平均每天高效的时间段也就 2-4 个小时代码,好好保护好它,每天预定出一个固定时间写代码,不允许别人打扰。深度工作时,戴上主动降噪耳机(不用放音乐),这样别人打扰你的概率会降低。
开会,写邮件,写文档,处理 customer issue,等需要和别人沟通的事情,也放到一个固定时间段。积极主动的管理打扰。
-
Rei on Rails #8:Ruby & Rails 入门书籍推荐 at 2023年04月12日
Rei 最近真是高产啊 👍
-
[广州] Symbio 公司招聘 Ruby 后端工程师 2 名 at 2023年04月12日
[管理员通知] 请按照 Markdown 排版,格式可以参考别人的招聘帖。
Markdown 格式:
https://markdown.com.cn/basic-syntax/headings.html
招聘帖范例:
如果两天后,格式还是乱七八糟,该帖子会移动到 NoPoint 节点。
-
[上海][2022 年 11 月 8 日] Ruby / Rails 线下聚会召集 at 2022年11月05日
报名 +1
-
容器化对 Encrypted Credentials 的安全构建及部署配置的最佳实践 at 2022年10月24日
我倾向于把 secret 放到 kubernetes secret
然后运行 pod 时,把各种 secret 通过环境变量(envFrom)注入到 pod 中。
apiVersion: v1 kind: Pod metadata: name: secret-test-pod spec: containers: - name: test-container image: registry.k8s.io/busybox command: [ "/bin/sh", "-c", "env" ] envFrom: - secretRef: name: mysecret restartPolicy: Neverhttps://kubernetes.io/docs/concepts/configuration/secret/#use-cases
-
推荐三个教小孩学编程的 App at 2022年09月15日
欢迎订阅我的半死不活的博客:https://mednoter.com/teach-kids-to-code.html
-
提高中国程序员幸福感的网络调试工具 at 2022年07月30日
为了防止给论坛惹一堆麻烦,我把评论关了,免得触发一些敏感词。
-
runc hang 导致 Kubernetes 节点 NotReady at 2022年07月06日
作者基本功真是扎实。我几年前也是遇到 runc init 卡住的问题,只会使用重启大法。
https://stackoverflow.com/questions/56269285/docker-what-does-runc2init-mean
-
欢迎加入 workstream 工程师团队。
-
Atlantis: 可确定的执行计划 at 2022年04月02日
谢谢纠正,已改。
-
[2022 年 3 月 22 日] Ruby Tuesday 线上聚会:如何找国外的远程工作? at 2022年03月23日
-
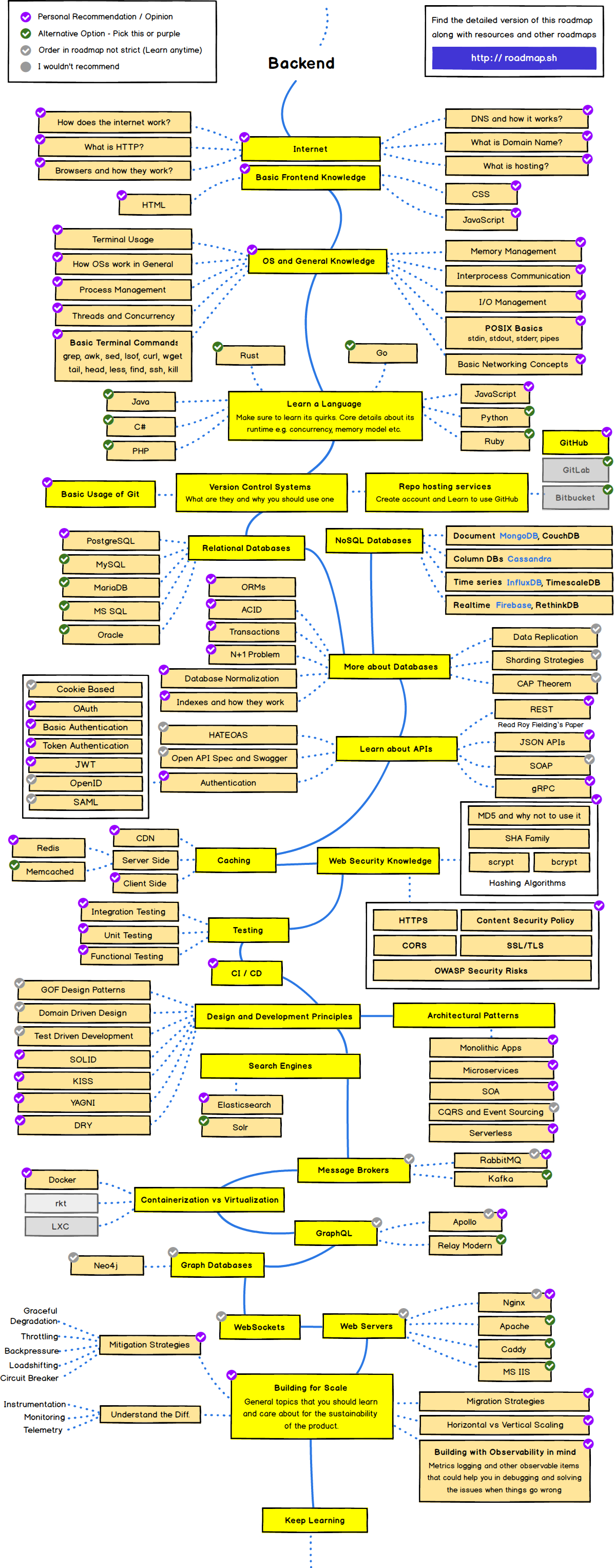
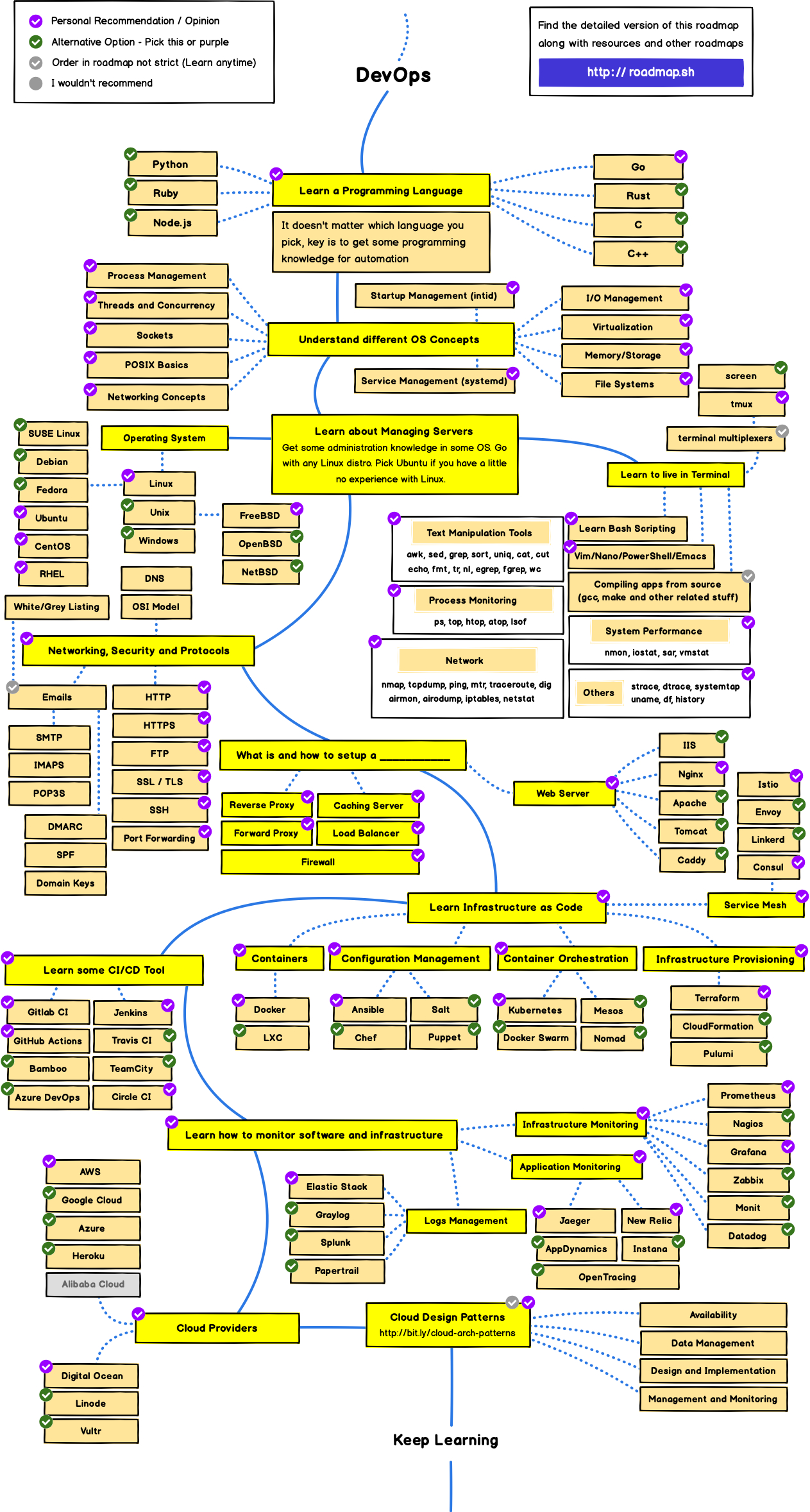
怎样才算两年经验的 Ruby 程序员 at 2022年03月22日
source: https://github.com/kamranahmedse/developer-roadmap
Back-end Roadmap
DevOps Roadmap
Frontend Roadmap
-
[2022 年 3 月 22 日] Ruby Tuesday 线上聚会:如何找国外的远程工作? at 2022年03月20日
单纯拼技术的话,中印程序员确实是竞争关系。
但很多企业在中国设立研发中心,除了成本,会考虑多方面因素,比如:
- 有些公司将来可能会拓展中国市场,在中国开展业务。
- 中国产业链完整。
- 创始人是华裔,所以和中国程序员沟通无障碍。
- 中国程序员综合素质高,出活。
所以针对这种情况,中国和印度不一定是零和游戏。
-
[2022 年 3 月 22 日] Ruby Tuesday 线上聚会:如何找国外的远程工作? at 2022年03月20日
时间是下周二晚上,欢迎参加。
-
请问怎么让 CircleCI 跑子目录的测试代码? at 2022年03月11日
花了 1 天的时间,折腾了各种各样的参数,CircleCI 都跑不起来,实在是太沮丧了。幸运的是,github actions 对这种情况支持的特别好,我只需要加一个参数就搞定了。
这个子服务代码量很小,3 分钟就可以跑完测试,我就先不用 CircleCI 了,转投 Github Actions。
这是我用的范例文件,如果将来有人也有类似的需求“在一个子文件夹中跑测试”,可以试试 Github Actions。
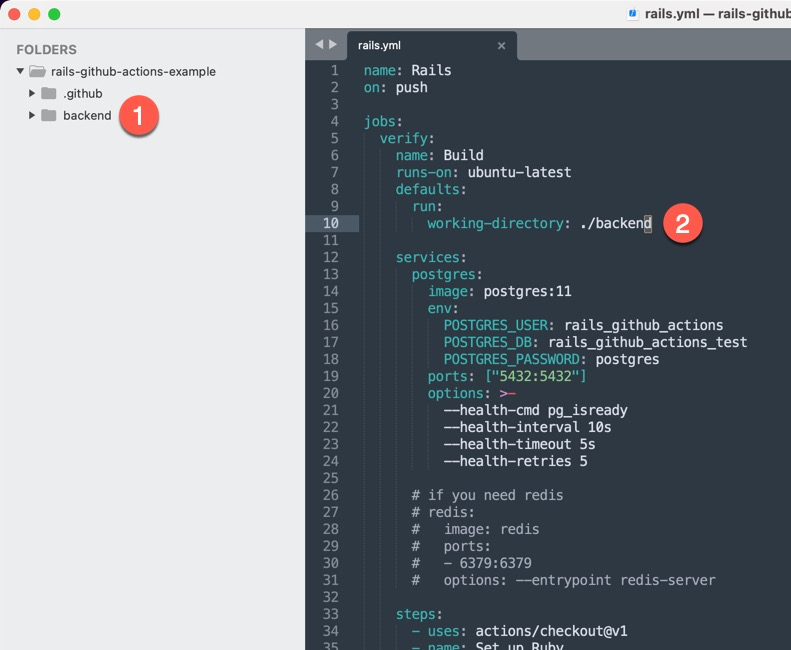
这是 Github Actions 的配置文件
name: "Backend Test" on: push: branches: [ main ] pull_request: branches: [ main ] jobs: test: runs-on: ubuntu-latest defaults: run: working-directory: ./backend env: RAILS_ENV: test DATABASE_NAME: connector_test DATABASE_USER: postgres DATABASE_PASSWORD: password services: postgres: image: postgres:11 env: POSTGRES_USER: postgres POSTGRES_DB: connector_test POSTGRES_PASSWORD: password ports: ["5432:5432"] options: >- --health-cmd pg_isready --health-interval 10s --health-timeout 5s --health-retries 5 steps: - name: Checkout code uses: actions/checkout@v2 - name: Install dependencies run: | sudo apt-get -yqq install libpq-dev build-essential libcurl4-openssl-dev - name: Install Ruby and gems uses: ruby/setup-ruby@v1 with: rubygems: latest working-directory: ./backend ruby-version: 2.7.3 cache-version: 3 bundler-cache: true - name: Set up database schema run: bundle exec rake db:schema:load - name: Run tests run: bundle exec rspec -
请问怎么让 CircleCI 跑子目录的测试代码? at 2022年03月10日
@lanzhiheng 大佬,我看你还给官方 demo 提供过代码,你折腾过前后端分离的项目的 CircleCI 的配置文件吗?

-
I Was Wrong, We Need Crypto | DHH at 2022年03月07日
说好的中立国不再中立,N 多富豪瞬间倾家倾家荡产,钱一下都没了。
DHH 的这篇文章真应景。