-
基于 Mongoid/ActiveRecord 的 statlysis 统计分析引擎 at December 31, 2013
@mvj3 哈哈~ 我歪楼了。暴露的服务使用 iptables 做了 ip 与端口的白名单 嘿嘿
-
基于 Mongoid/ActiveRecord 的 statlysis 统计分析引擎 at December 30, 2013
@small_fish__ 其实我比较好奇为什么如果有 Sphinx 经验,是什么理由促使你想使用 ElasticSearch ... 因为在全文搜索上 ElasticSearch 并不占 Sphinx 啥便宜,Sphinx 的搜索速度还是比 ES 快的,同时他们都有对应的分布式解决方案。
@mvj3 如你所说,我是当 ElasticSearch 为一个独立的服务或者应用在使用他,所以在已有的系统与其交互的时候,也是脱离现有的 Model 去设计存入 ES 中的 document 的,要这样思考解决问题,也是因为历史项目问题 - -|| 一个是历史的 Java 项目,一个是新上的 Rails 项目,Rails 项目要用 Java 项目中的数据,为了分析数据的性能也为了独立开两个项目的联系,所以就通过 ES 作为中间数据的转换中心,用 Ruby 脚本处理 Java 项目 DB 中的数据,然后再通过 ES 的 Query DSL 想外提供服务。
十亿级别已经很大了啦~ 然后我们是解决分析问题使用的两种思路,一种是重用现有 Model, 一种是独立设计业务相关 document , 最终都把问题解决了

-
基于 Mongoid/ActiveRecord 的 statlysis 统计分析引擎 at December 30, 2013
@mvj3 的确,业务部门会有各种各样的数据需要统计,计算。我这边主要是通过 Ruby 脚本将数据周期性 (我们对实时性要求不高) 导入 ElasticSearch, 然后根据 ES 提供的 Aggregation 的相关功能去进行分析处理。
对进入 ES 的 document 是需要根据业务进行整理的,也就是你所提到的 "解析引擎" 部分,我这边设计好相关业务所需要的信息组织成为一个 document, 然后挨个压入 ES 中。
看完你的 Blog 后感觉,对不同的统计功能,现在最难的不是存储与数据提取,因为现在有 Mongodb, ElasticSearch 这些针对较大数据量设计的项目,并且都有良好的集群支持,难的是如何设计好用于处理这些数据的 document 以及你的库所提供的 DSL 查询。
我选择 ES 的考虑是,他提供的 Restful 接口好好用,哈哈。
-
sinatra-synchrony is obsolete 了? at December 23, 2013
-
unless 不应该翻译为 “除非” at December 20, 2013
其实我一直当他 if not 来理解... 中文太博大精深了。
-
Bootstrap 2 的一个问题,求助~ at December 09, 2013
这个你得自己写一点 css, 再加一点代码判断 - -|| 因为 bootstrap 2 中
[class*="span"] { float:left; }所以所有 span 元素都左浮动,元素高矮不一样会被挡在那里然后就出现空白了。像上面的情况你需要每三个 span2 就来一个
不过这样,那么一行的高度会变为最高的那个,也不怎么美观。再然后,再然后就可以变为瀑布流的样式了 ... 每个 div 自动填充空隙.PS:
- 顺带提一下,我很怀疑你是在 development 环境运行的这个网站 =.=, 因为我看到
/var/www/doit和app/controllers/encyclopaedia_controller.rb:6:...了 - Ruby 代码建议
ruby def index #@childrenList = Array.new t = Topic.where(:Name=>"Encyclopaedia").first @childrens = Topic.find(t.ChildrenIdList) #t.ChildrenIdList.each do |child| #t.children #@childrenList << Topic.find(child) #end ... end - 添加点测试代码
- 顺带提一下,我很怀疑你是在 development 环境运行的这个网站 =.=, 因为我看到
-
rspec 在 model 层的测试,应该怎么入手比较好? at December 09, 2013
一点简单的认识哈
- 看情况测试需要覆盖业务方法的 "验证" 部分,像满足啥啥啥才可执行。
- model 方法一般情况下需要覆盖成功与失败两个部分
- 针对成功与失败,会特别特别测试方法中调用前后的变化。例如值变化从 x->y, 调用了 xx 方法。这些都会在一个 spec 中,所以基本上一个 model 方法测试,会被一个大 context 包着"成功", 然后一个一个小的 "it xxx do" 包着一个一个期望得到的结果。
-
elasticsearch 能否当数据库用? at December 04, 2013
要是和关系型数据库比,最直接的是 ACID 差别。
正规产品,还是主流点,解决方案成熟点。
-
大家都用 haml 还是 erb 呢 at December 04, 2013
erb 用过 slim, 然后还是用回 erb
-
ruby 时间区间判断 at November 30, 2013
Time.now.zone # 查看时区 Time.now.to_s # 2013-11-30 16:41:27 +0800 Time.now.in_time_zone('Tokyo') # 2013-11-30 17:41:54 +0900 ActiveSupport::TimeZone.zones_map.map { |k, v| k } # Rails 支持的时区 ActiveSupport::TimeZone[-8] # 获取 -8:00 时区.希望可以帮到你。
-
rexml 解析 xml 解析效率 at November 29, 2013
- Rails 中我会: ActiveSupport::XmlMini.backend = 'Nokogiri'
- 如果是非常大的 XML 文件,我会用 Nokogiri::XML::Reader + Nokogiri::XML(node.outer_xml) 来处理,如果独立使用 Reader 流的方式,解析起来很崩溃...
-
mongodb 数据库空间占用问题: 有人来真的了 MongoDB is dead. Long live Postgresql :) at November 28, 2013
这图片太欢乐了 哈哈
-
Bootstrap 2 or 3 at November 28, 2013
@Victor 的确~
看了下,对 Foundation 的介绍还是 Foundation 3 - -||
-
Bootstrap 2 or 3 at November 28, 2013
会不会有人想到 fundation 5 呢?
-
Always Multiply Your Estimates by π at November 27, 2013
我做了次搬运工~ 然后中文版出来了
http://www.oschina.net/translate/always-multiply-estimates-by-pi -
「简单易懂的 OAuth 2.0」演讲 Slides at November 27, 2013
超详细的干货
-
Always Multiply Your Estimates by π at November 24, 2013
有点道理,总能感觉到超出时间,但具体超出多少还从来没这么想过。
-
CSS 解决 field error 的重复代码 at November 23, 2013
对 form 表单中错误字段的提示真是很麻烦。
这个办法好!
-
CPU 只有 1.3Hz 的 Air 11 能带的动 rubymine 这种 IDE 吗? at November 08, 2013
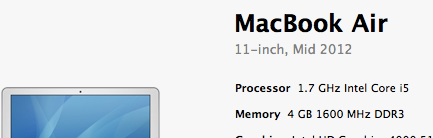 天天开着 RubyMine 5 开发,RubyMine 没你想象的那么慢。你卡顿是不是默认打开了自动的代码补全?虽然 RubyMine 提供了非常智能补全,可我在写 Ruby 脚本语言的时候是把这个关掉的,一般写到记不起的时候手动用快捷方式触发一下。代码书写速度很流畅的。
天天开着 RubyMine 5 开发,RubyMine 没你想象的那么慢。你卡顿是不是默认打开了自动的代码补全?虽然 RubyMine 提供了非常智能补全,可我在写 Ruby 脚本语言的时候是把这个关掉的,一般写到记不起的时候手动用快捷方式触发一下。代码书写速度很流畅的。 -
Mountain Lion 因 Chrome 休眠很慢 at November 07, 2013
#5 楼 @blackanger 这这...
-
《jQuery 实战 (第 2 版)》与《jQuery 基础教程 (第 4 版)》哪本更好? at November 07, 2013
-
发现 Puma 用 JRuby 来跑确实快了好多 at November 07, 2013
#5 楼 @blackanger 这到也是 - -|| 我从众心理了,大家都用 MRI 不出问题,所以我也用 MRI 求稳定不出问题 :P
-
ElasticSearch 初次使用小结,一起学习进步哈~ at November 07, 2013
@jimrokliu 索引的 document 设计 因为 ES 索引的文档 db 存储的东西是没有关系的,所以我们可以随意将不同 model 中的数据组合成合适搜索的 document , 像这个组非常多得情景的话。可以把 document 设置为拥有 "组 field" 和 "内容 field" 这是索引用的的元数据,如果还有其他搜索的需求,可以针对性的为 document 添加 field, 例如查找的 model 的 id
搜索条件的编写 ES 的 Query DSL 真的是太灵活了,所以搜索的时候可以有很多方式。因为组信息在用户身上,这样在生成查询的时候,是实时变化的,比如原本其加入了 101 个组,突然退出一个组,剩下了 100 个组,那么生成 ES 查询语法算法不用便,值变而已
- query string 指定 "组 field" 然后 "组 1 组 2 ... 组 100" 这样搜索
- terms query 指定 "组 field": [组 1, 组 2, 组 3, ... 组 100] 这个貌似比较直观
- bool query 将所有组添加到 should 中。
- 除了正向的 query 还有反向的 filter terms filter
所以,当需要索引的文档确定好后,查询语法相比在数据库中搜索,灵活太多太多。右侧目录所有的 query, 所有的 filter
搜索类型 这个我猜测是 ES 多 shards 存储数据而弄出来的,默认情况搜索时 size=10, 这是返回 10 个 document, 当改变一下搜索类型仍然是 size=10 , ES 可以返回 shards 数量 * size 个结果 (默认 5 个 shards, 返回 50 个结果), 这个特性存在我觉得比较奇葩~ 因为有一次被 ES 坑在这里特别记得 - -||
降低性能 这个我就不好打包票了,复杂搜索语法对于整个搜索所增加的时间是多少得到真实环境下测试下了。这里我想到的比较重要的需要参考的因素有,索引的文件的数量,elasticsearch cluser 中 node 的数量,每个 node 的 shards 的数量。再从细节中挣脱出来看一下,在 ES 中的搜索都是以 ms 计时的,增加的时间应该不会超出太多数量级吧。
-
发现 Puma 用 JRuby 来跑确实快了好多 at November 06, 2013
-
《jQuery 实战 (第 2 版)》与《jQuery 基础教程 (第 4 版)》哪本更好? at November 06, 2013
-
ElasticSearch 初次使用小结,一起学习进步哈~ at November 06, 2013
#27 楼 @raecoo 没有传统 DB 的关联查询啥的,就是一堆文档在一个 type 下,一堆 type 在一个 index 下,然后根据 index/type + query dsl 去查,所以现在我要查询不同的 model 的数据才有了两个 70+w 的 type
#28 楼 @jimrokliu 这个我觉得你给 document 添加个 field 用来标示权限,搜索的时候根据权限过滤出特定的 term 也可以呀。ElasticSearch 本身没有提供数据的权限控制吧。
关于 document 上的 field 和 term , 把 jd.com 搜索产品的时候那么多得条件想象成一个一个的 term 值比较像
 glossary of terms
glossary of terms -
ElasticSearch 初次使用小结,一起学习进步哈~ at November 06, 2013
-
ElasticSearch 初次使用小结,一起学习进步哈~ at November 06, 2013
-
ElasticSearch 初次使用小结,一起学习进步哈~ at November 06, 2013
 天天开着 RubyMine 5 开发,RubyMine 没你想象的那么慢。你卡顿是不是默认打开了自动的代码补全?虽然 RubyMine 提供了非常智能补全,可我在写 Ruby 脚本语言的时候是把这个关掉的,一般写到记不起的时候手动用快捷方式触发一下。代码书写速度很流畅的。
天天开着 RubyMine 5 开发,RubyMine 没你想象的那么慢。你卡顿是不是默认打开了自动的代码补全?虽然 RubyMine 提供了非常智能补全,可我在写 Ruby 脚本语言的时候是把这个关掉的,一般写到记不起的时候手动用快捷方式触发一下。代码书写速度很流畅的。