-
推荐一个简单有效的减肥方法:生酮饮食 at 2019年01月22日
推荐一本书 程序员健康指南
-
50 小时重建了我的博客:Gatsby 让我重新爱上了 JavaScript (更新了经验记录和好多以前的老设计) at 2019年01月21日
感觉 50 个小时完成一个博客时间很长
-
同样是社区,为什么 Ruby China 如此坚挺,而那些融入资本的如掘金或 SF 却不如 Ruby China? at 2019年01月14日
ruby小众,但是国内基本上都集中在ruby china,像go都不知道有多少个社区,而你提到的社区都是一个大杂烩,并没有特色。 -
HTTP 缓存 at 2019年01月10日
应该是你没有设置可缓存性
Cache-Control:public, max-age=31536000参考文档
-
《Rust 编程之道》预售开启 at 2018年12月28日

-
Ant Design 错了吗? at 2018年12月26日
Ant Design 的问题是跳过了开发者,将“彩蛋”直接呈现给最终用户。
彩蛋通常在用户进行了某些特定的操作时出现,而 Ant Design 这个是时间触发,并不是用户去触发的。
-
Ruby 2.6.0 已发布 at 2018年12月25日
-
拼写检查的四种实现 at 2018年12月23日
对 我理解错了 B 树也是多叉树 它更接近 B+ 树 B 树和 B+ 树,本质上都是一样的,只是 B+ 树所有的根节点和枝节点上只保存关键字索引和其子节点指针,所有的数据信息都被保存到了叶子节点,这样每个枝节点可以存储更多的数据,从而降低树的层级高度,并且所有的叶子节像是一个链表一样,指向右边的叶子节点,从而可以有效加快检索效率,如果需要遍历所有的数据,只需要遍历叶子节点链式结构即可,方便且高效。
-
拼写检查的四种实现 at 2018年12月23日
-
拼写检查的四种实现 at 2018年12月23日
叫作 Trie 的多叉树其实就是实现数据库索引用到的 B+ 树(多叉树),查询的时间复杂度是 O(log n),它的优势是范围查询(比如楼上提到的拼写建议)。
为什么不用查找效率最好二叉树?因为在硬盘上顺序读比随机读快,并且 B+ 树深度比二叉树少的多,在查询的时候执行的顺序读比随机读多,所以 B+ 树更适合。
拼写检查的实际需求是 KV 查询,B+ 树并不合适。哈希表 (Hash Table) 的 KV 查询时间复杂度是 O(1) ,它才是最好的选择。
Bloom Filter 是在哈希表的基础上,压缩信息,加速查询。这种压缩是有损数据压缩,丢失了一些信息,所以带来了可能出错的问题。
-
Nginx 进程和信号 at 2018年12月20日
thx 已修改
-
Erlang 源码阅读 -- scheduler at 2018年12月01日
这些机制都是类似的 背后的原理是 CPU 的进程上下文切换 比如进程数和 CPU 逻辑核数 1:1、利用切换上下午的逻辑让空闲进程使用 sheep 主动挂起
-
Docker 模式如何修改首页模板呢 at 2018年11月29日
Docker 的话 你需要重新 build image
-
浅谈 Markdown 编译器 at 2018年11月20日
图的确弄错了
已修正 -
[技能图谱免费下载] 进阶数据库工程师 你需要 Get 这些技能 at 2018年11月19日
图不错 其实干什么的程序员都要了解这些 只是侧重点不同
-
使用
initialize是一种方案4楼说了另外一种方案思路都是一样的,即在使用
B的调用链路上去检查B的某个方法是否是私有 -
你可以在父类加一个限制,不符合条件就抛出异常,比如
class A def initialize must_private_method :text end def must_private_method(method) if self.private_methods.include?(method) # 方法是私有的时候输出一句话 puts "#{self.class.name} #{method} method is private method" else # 方法不是私有的时候抛出异常进行提示 raise "#{self.class.name} #{method} method is not private method" end end private def text 3 end end class B < A def text 5 end end a = A.new # A text method is private method b = B.new # in `must_private_method': B text method is not private method (RuntimeError) -
维护测试环境分支和线上环境两个分支管理不同的 dotenv 的最佳实践? at 2018年11月14日
.env.local应该使用.gitignore忽略如果项目不大,配置可以写在项目里,那么你新建一个文件比如
.env.production作为线上配置和开发/测试区分你可以看下:
-
新人求问, rubyer 所在的公司假如要招实习生, 如何看待之前没有 ruby 基础的申请者? at 2018年11月10日
你可以先自学一些
-
Friends don't let real friends use INT as a primary key? at 2018年11月09日
社区一直在逃避大数据高并发分布式之类的问题。
这些需求出现后,并没有成熟的解决方案,往往要转换技术栈。比如转向
Java或是最近很火的Go。活在
Ruby on Rails舒适区里都不想改变,midori是一个不错的尝试,可惜不够成熟也势单力薄。 -
求指教,关于冷热数据分离,各位大神们是如何在 Rails 中处理的? at 2018年11月06日
你可以看下 全面理解 ActiveRecord 和 Rails 怎么做数据库分库的?
另外一个办法就是你在
model层根据具体情况去选择不同的db,比如按时间切分if time > Time.new(2017) # mysql select else # Tidb select end这个办法比猴子补丁难度小的多,就是改动的地方比较多,同时你可以想办法用元编程其他的手段去扩展 ActiveRecord。
-
 1、3 楼都是逃避问题 把提出问题的干掉
1、3 楼都是逃避问题 把提出问题的干掉 -
求指教,关于冷热数据分离,各位大神们是如何在 Rails 中处理的? at 2018年11月06日
简单点,你可以给
ActiveRecord来个猴子补丁,规则先定好如果规则想自动化,就需要做一个热点系统。系统主要是做热点数据的筛选分类和转移,请求的分发等等。
-
active job 序列化 Marshal.dump 出来的字符串报错 at 2018年11月05日
Marshal一般来说是用来深拷贝的,例如a = ["Monkey", "Brains"] b = Marshal.load(Marshal.dump(a)) #=> ["Monkey", "Brains"] b.each(&:upcase!) #=> ["MONKEY", "BRAINS"] a #=> ["Monkey", "Brains"]你的需求是序列化,用
to_json就行了 -
手动部署依赖 ENV 存储配置的项目,ENV 怎么放? at 2018年11月02日
推荐用
dotenv-rails -
为什么不应该使用 rvm/rbenv,以及替代方案 at 2018年10月29日
国内好像还没有比较靠谱的私有 Docker Registry 服务
-
为什么不应该使用 rvm/rbenv,以及替代方案 at 2018年10月28日
-
Ruby China 7 岁生日快乐 at 2018年10月28日


-
为什么不应该使用 rvm/rbenv,以及替代方案 at 2018年10月27日
k8s 太复杂了 我现在还是晕的
我觉得持有化服务 现在分布式架构都比较成熟了 不一定要上 docker 除非是混部之类的
-
为什么不应该使用 rvm/rbenv,以及替代方案 at 2018年10月27日
本地开发还好 上生产感觉就很繁琐了
我最近写了一个项目练手 https://github.com/tuliang/in-the-eyes
用 Capistrano 部署,Docker Compose 管理,现在跑着 Rails,PostgreSQL 和 Nginx,准备加 Memcached 和 Redis
流程大概是下图
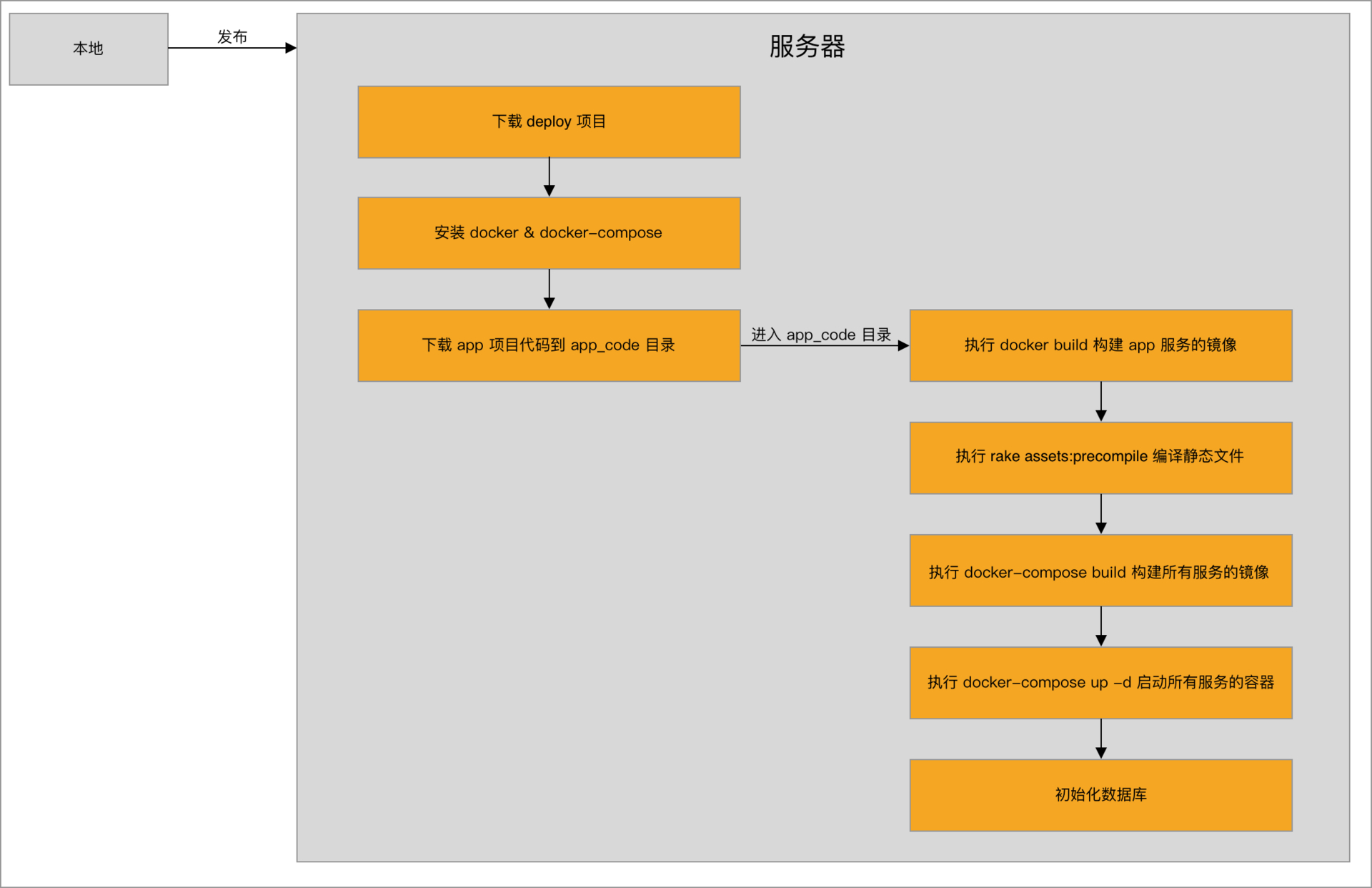
现在整个服务还是很简单的,我想如果后期加入各种系统,比如后台管理,数据统计,环境配置,自动化测试/压测之类的就挺复杂了。
现实是在公司内部,各种系统是不同团队维护的。如果要整体 docker 化,现在 docker 以及配套的系统并不能即装即用,那么他们都需要去学习,这个学习成本还是比较高的,并且遇到了坑一般的团队可能不太好解决。
像 @Rei 提到的,如果有一天能达到 Heroku 这种程度那就好了。