浅谈 Markdown 编译器
作者不是科班出身,基础比较差。一直在补习一些基础知识,也包括编译原理。最近和朋友交流的时候有提到 AST(抽象语法树),虽然以前也零散的看了一些文章,实际上还是比较模糊的。
在这一篇文章中,我会尝试谈一下编译器。虽然参考了诸多资料,不过文中观点难免掺入主观想法,我也希望文中的错误与不足之处能被各位指出。
基础知识
编译原理是计算机专业的一门重要专业课,旨在介绍编译程序构造的一般原理和基本方法。内容包括语言和文法、词法分析、语法分析、语法制导翻译、中间代码生成、存储管理、代码优化和目标代码生成。
解释器与编译器
解释器
解释器根据程序中的算法执行运算。简单来讲,它是一种用于执行程序的软件。如果执行的程序由虚拟机器语言或类似于机器语言的程序设计语言写成,这种软件也能称为虚拟机。
编译器
编译器能将某种语言写成的程序转换为另一种语言的程序。通常它会将原程序转换为机器语言。编译器转换程序的行为称为编译,转换前的程序称为源代码或源程序。如果编译器没有把源代码直接转换为机器语言,一般称为源代码转换器或源码转换器(source code translator)。
过去人们提到编译器时,首先会联想到费时的编译过程。不过由于编译后实际执行的是机器语言,因此执行速度很快。而对于解释器,人们通常认为它会在程序输入的同时立即执行,执行速度较慢。这就是两者的基本区别。现代的解释器内部常采用各种类型的编译器,已经越来越没有必要将解释器和编译器区分看待。
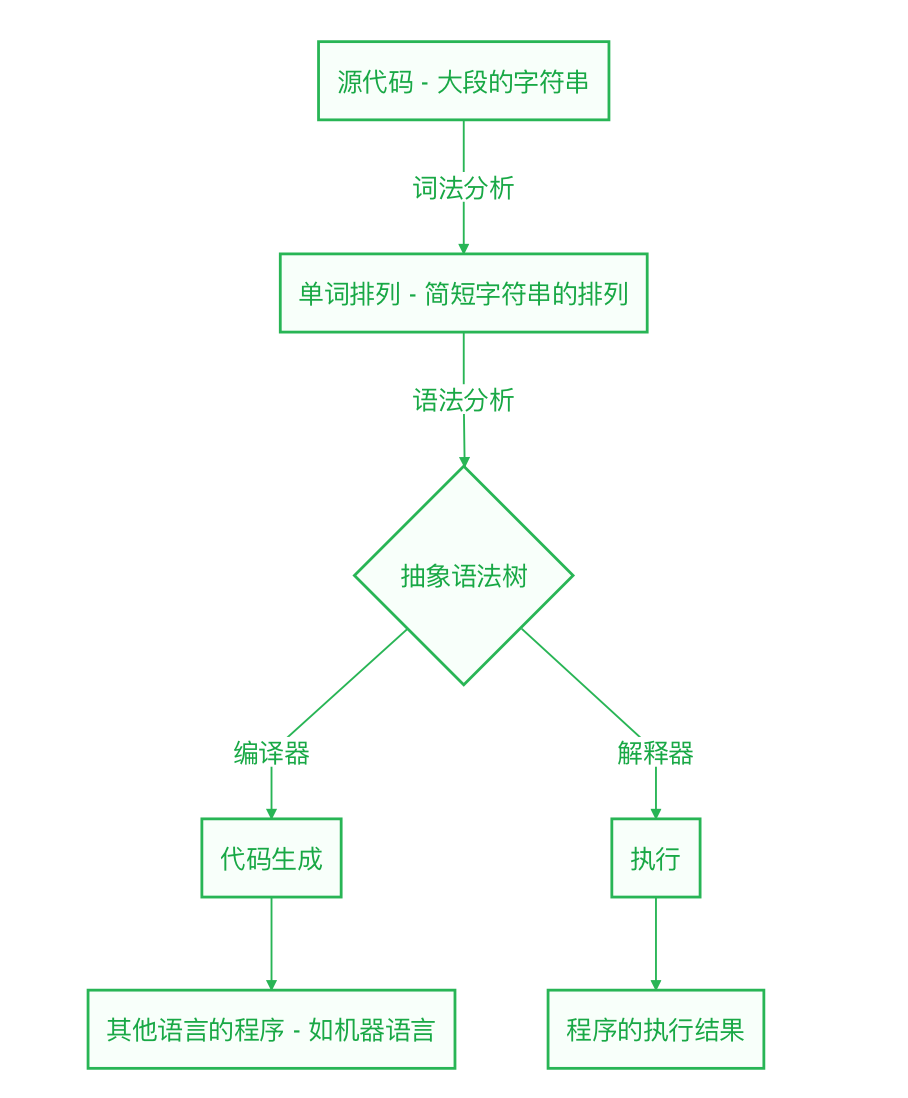
语言处理器的结构
无论是解释器还是编译器,语言处理器前半部分的程序结构都大同小异。如下图所示
分割单词
语言处理器的第一个组成部分是词法分析器(lexical analyzer、lexer 或 scanner)。程序的源代码最初只是一长串字符串。从内部来看,源代码中的换行也能用专门的(不可见)换行符表示,因此整个源代码是一种相连的长字符串。这样的长字符串很难处理,语言处理器通常会首先将字符串中的字符以单词为单位分组,切割成多个字符串。这就是词法分析。
词法分析器将把程序源代码视作字符串,并把它分割为若干单词(token)。分割后得到的单词并不是简单地用 String 对象表示,而是使用 Token 对象。这种对象除了记录该单词对应的字符串,还会保存单词的类型、单词所处位置的行号等信息。
用于表示程序的对象
语言处理器在词法分析阶段将程序分割为单词后,将开始构造抽象语法树(AST,Abstract Syntax Tree)。抽象语法树是一种用于表示程序结构的树形结构。
构造抽象语法树的过程称为语法分析,依然属于语言处理器的前半阶段。经过词法分析后,程序已经被分解为一个个单词。语法分析的主要任务是分析单词之间的关系,如判断哪些单词属于同一个表达式或语句,以及处理左右括号(单词)的配对等问题。语法分析的结果能够通过抽象语法树来表示。这一阶段还会检查程序中是否含有语法错误。
以 13 + x * 2 为例
单词序列

抽象语法树
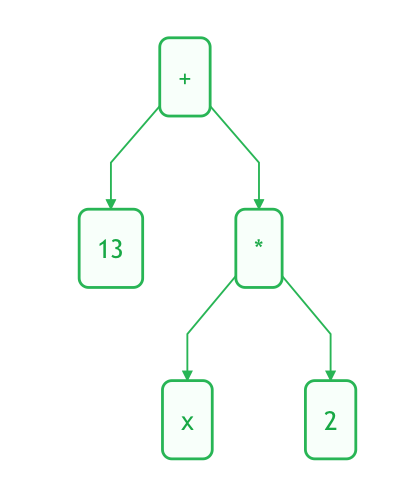
抽象语法树仅用于表示语法分析的结果,因此通过语法分析得到的单词并不一定要与抽象语法树的节点一一对应。抽象语法树是一种去除了多余信息的抽象树形结构。例如
(13 + x) * 2
这样一个表达式来说,它与之前的例子不同,包含了括号。乘法运算的左值不再是 x 而是 13 + x。那么它的抽象语法树是
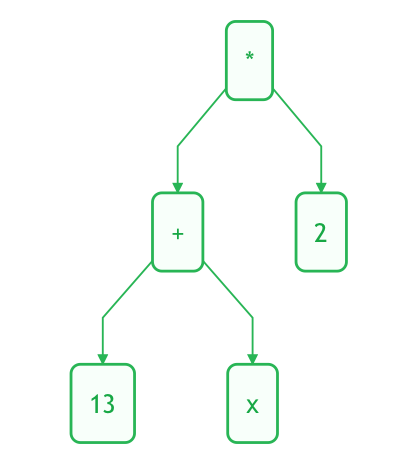
程序中的括号等信息不必出现在抽象语法树中。除了括号,句尾的分号等无关紧要的单词通常也不会出现在抽象语法树中。
抽象化原本指的就是去除多余的内容,抽取出事物的本质。
实战
分割单词
使用正则表达式来分割单词,支持
# ## ### ```
以下面为例
# 标题
\```
x = 1
y = x + 2
\`\`\`
单词序列
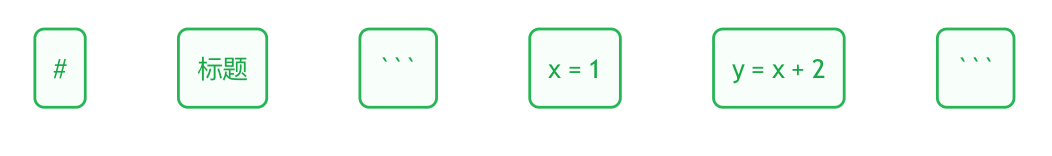
部分代码
@regex = /(^###)|(^##)|(^#)|(^```)|(.+)/
def read
File.readlines(@filename).each_with_index do |line, i|
# i 从 0 开始 需要先 + 1
@line_number = i + 1
readline(line)
end
end
def readline(line)
array = line.scan(@regex)
if array.length != 0
array.each do |item|
add_token(item)
end
end
end
def add_token(item)
if item[0] != nil
token = Token.new('H3', @line_number)
elsif item[1] != nil
token = Token.new('H2', @line_number)
elsif item[2] != nil
token = Token.new('H1', @line_number)
elsif item[3] != nil
token = Token.new('Code', @line_number)
elsif item[4] != nil
token = Token.new('Text', @line_number, item[4])
else
raise "bad token at line #{@line_number}"
end
@queue << token
end
构造抽象语法树
抽象语法树使用栈转树的方式实现
抽象语法树
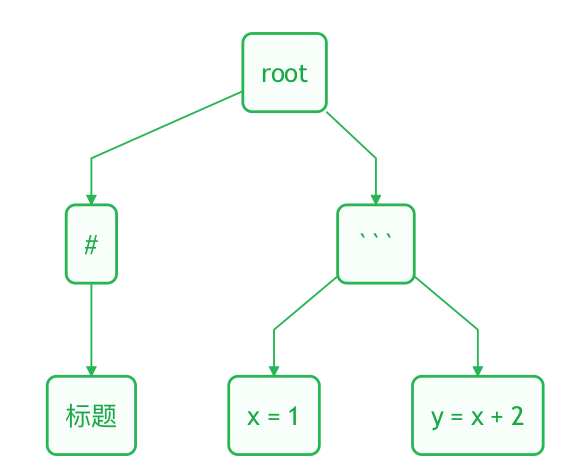
部分代码
def ast_runner
index = 0
ast = []
# 遍历队列
while @queue.length > index do
token = @queue[index]
case token.type
when 'H1', 'H2', 'H3'
# H1 H2 H3 规则
node = ASTList.new(token)
# index 向后移动 1 位 指向下个节点
index += 1
next_node = @queue[index]
# 去除左边的空格
next_node.text.lstrip!
# 将节点附加到 children 末尾
node.children << ASTLeaf.new(next_node)
when 'Text'
# Text 规则
# 直接生成叶子节点
node = ASTLeaf.new(token)
when 'Code'
# Code 规则
node = ASTList.new(token)
# Code 未闭合前一直循环
while true do
# index 向后移动 1 位 指向下个节点
index += 1
next_node = @queue[index]
if next_node.type == 'Code'
# 当前节点为闭合节点 退出循环
break
else
# 将节点附加到 children 末尾
node.children << ASTLeaf.new(next_node)
end
end
else
raise "bad token type at line #{token.line_number}"
end
# 将节点附加到 ast 末尾
ast << node
# index 向后移动 1 位 进行下个迭代
index += 1
end
ast
end
运行
$ ruby lexer.rb
H1
└── Ruby Markdown
一个使用 Ruby 实现的 Markdown 编译器
H2
└── 解释器与编译器
H3
└── 解释器
解释器根据程序中的算法执行运算。简单来讲,它是一种用于执行程序的软件。如果执行的程序由虚拟机器语言或类似于机器语言的程序设计语言写成,这种软件也能称为虚拟机。
H3
└── 编译器
编译器能将某种语言写成的程序转换为另一种语言的程序。通常它会将原程序转换为机器语言。编译器转换程序的行为称为编译,转换前的程序称为源代码或源程序。如果编译器没有把源代码直接转换为机器语言,一般称为源代码转换器或源码转换器(source code translator)。
过去人们提到编译器时,首先会联想到费时的编译过程。不过由于编译后实际执行的是机器语言,因此执行速度很快。而对于解释器,人们通常认为它会在程序输入的同时立即执行,执行速度较慢。这就是两者的基本区别。现代的解释器内部常采用各种类型的编译器,已经越来越没有必要将解释器和编译器区分看待。
H2
└── 运行
Code
└── ruby lexer.rb
Code
├── lexer = Lexer.new("README.md")
├── parser = lexer.parser
├── parser.show
└── puts parser.to_html
<h1>Ruby Markdown</h1><p>一个使用 Ruby 实现的 Markdown 编译器</p><h2>解释器与编译器</h2><h3>解释器</h3><p>解释器根据程序中的算法执行运算。简单来讲,它是一种用于执行程序的软件。如果执行的程序由虚拟机器语言或类似于机器语言的程序设计语言写成,这种软件也能称为虚拟机。</p><h3>编译器</h3><p>编译器能将某种语言写成的程序转换为另一种语言的程序。通常它会将原程序转换为机器语言。编译器转换程序的行为称为编译,转换前的程序称为源代码或源程序。如果编译器没有把源代码直接转换为机器语言,一般称为源代码转换器或源码转换器(source code translator)。</p><p>过去人们提到编译器时,首先会联想到费时的编译过程。不过由于编译后实际执行的是机器语言,因此执行速度很快。而对于解释器,人们通常认为它会在程序输入的同时立即执行,执行速度较慢。这就是两者的基本区别。现代的解释器内部常采用各种类型的编译器,已经越来越没有必要将解释器和编译器区分看待。</p><h2>运行</h2><pre><code><p>ruby lexer.rb</p></code><pre><pre><code><p>lexer = Lexer.new("README.md")</p><p>parser = lexer.parser</p><p>parser.show</p><p>puts parser.to_html</p></code><pre>
总结
从 分割单词 获得单词序列到 构造抽象语法树,再到生成代码,基本上实现了一个最简单的编译器。
在做的过程中你会发现编译原理的确是大作业,细做的话每一步,有太多东西,另外解释器也不简单。

 已修正
已修正