Rails 求指教,关于冷热数据分离,各位大神们是如何在 Rails 中处理的?
版本
rails 3 + ruby 1.9 + mysql 5.7 + Tidb
场景
热数据存储于 mysql,冷数据存储于 Tidb
我想,很多数据量大的系统都会出现类似这种场景
比如一个系统中 order 数据, 在现在 2018 年了,1 or 2 年前的数据,用户基本没有需求访问了吧?有也是处于极少数情况。
问题
请教各界朋友
- 有什么方案可以处理这种场景?
- 如何在现有系统中,(不改动 or 少量改动) 的集成?
想法💡
获取结果流程
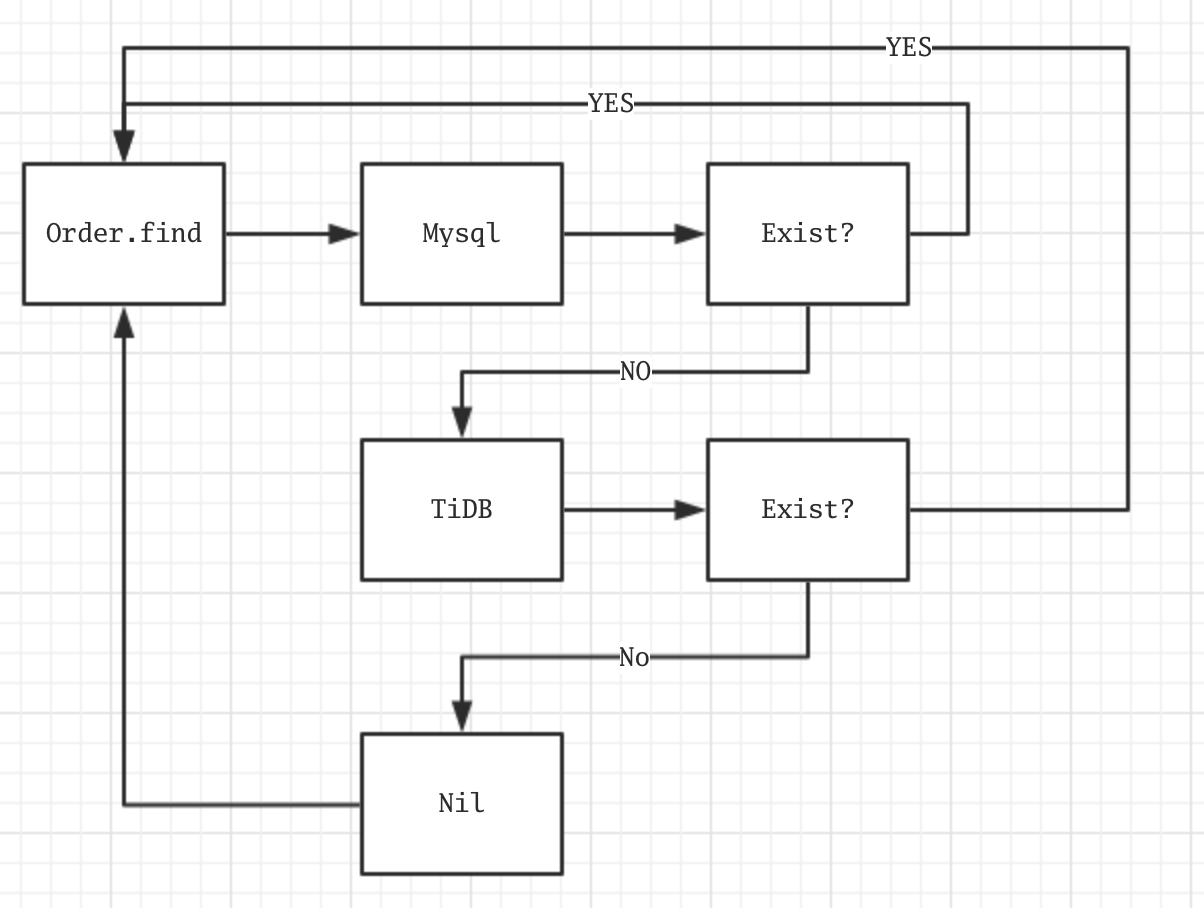
插件,我可以在任意
model使用插件代理该model的所有 select sql,让插件在不同情况下切换不同数据源
但,我好像不知道该如何实现它 ...
简单点,你可以给 ActiveRecord 来个猴子补丁,规则先定好
如果规则想自动化,就需要做一个热点系统。系统主要是做热点数据的筛选分类和转移,请求的分发等等。
一个 controller 可能会有很多直接调用查询或间接
ActiveRecord 可能有 find、find_by、all、last、first...等等的产生 select sql 的方法
如果给 ActiveRecord 的这些方法去打补丁,就需要给所有会产生 select sql 相关的方法都打上吗?
请问,可以用什么方式可以挂在所有产生 select 的方法上?
你可以看下 全面理解 ActiveRecord 和 Rails 怎么做数据库分库的?
另外一个办法就是你在 model 层根据具体情况去选择不同的 db,比如按时间切分
if time > Time.new(2017)
# mysql select
else
# Tidb select
end
这个办法比猴子补丁难度小的多,就是改动的地方比较多,同时你可以想办法用元编程其他的手段去扩展 ActiveRecord。
想到 DHH 这段演讲 6:19 开始
分库真的是必须的吗?我接触过最大一个表 1 亿数据也没有分库,索引合理数据库能撑住。
看顶楼已经用了 TiDB 了,不考虑全用 TiDB,让它解决扩展问题?
小规模数据可以这样:
- 按照 created_at 分区 (partition)。例如三个月或一年一个区 (看具体情况),这个最简单。数据分布情况对应用透明,最近的查询会自动落到最新的分区上(得带上分区字段的查询条件)。
- 按照某字段分表。例如,可以是 created_at,三个月或一年一个表 (看具体情况),分表的情况由应用自己维护。在查询时先按照 created_at 计算一下是在哪个表,然后就直接从对应表拿数据。
分库是上级决定了
目前 亿量级别的数据应该都会考虑把查询放在 TiDB,Mysql 保留热数据 update
迁移 TiDB 还属于逐步迁移的过程,这个也是一次 TiDB 的实验,还不敢全动
那是没有大量的聚合查询在 mysql 里面搞,搞几次 join,mysql 内存耗尽就很苦逼。mysql 一般来说 500 万一张表。
冷热分两种 db?真是 no zuo no die…要么老老实实做 sharding 要么换个可以 auto sharding 的库,要么搞 proxy…
你上面的流程能 work 的前提是你的系统只存在简单的 select 查询…
你们是啥系统,都达到这种规模,但还搞出这种过家家一样的方案,交易所吗
为何要 mix oltp olap 呢?聚合查询在 slave 做或 etl 到一个 analytics db 这是很容易的。oltp olap 混用可能 500 万一张表会出问题,但这是架构问题…
用两种 DB 并不是为了处理冷热的场景而决定使用两种 DB, 而是打算使用 TiDB,属于试用阶段而考虑让冷数据先放 TiDB
proxy,目前是在研究的,我想的是 proxy 并非 proxy db,毕竟目前还只是针对一个 model
至于你说过家家的方案,sorry,可能是我个人想出来的解决思路有点 low
如果 TiDB 可以满足需求,最后要切换过去,那么现在做得分库可能是不必要了,甚至成为迁移的阻碍。
不如压测一下 TiDB 行不行,可以的话直接切过去。
声明:我没用过 TiDB。
分库分表很简单,技术上就是典型的分库分表。
但这只是手段而已。
分库分表的目的,是为了扩大尚未冷却的数据的承载量,比如你单表 800w 数据量达到性能瓶颈、同时业务要扩大发展,那么分库分表就可以承载到 4000w 的数据量(数字是我估计的,意在表示量级)。
处理冷热数据,最关键的是从业务上界定冷热边界,也就是在业务里划清界限;业务的思路理清楚后,根据需求,把冷数据从业务系统里迁出来就是了,至于存储细节,冷数据要怎么存、怎么用,也是需求决定的(如果完全没用,是不是可以扔掉,嗯,当然这么爽的办法现实中几乎不可能,所以就意淫一下)。
处理冷热数据分离,难点在于界定冷热边界后的工程。有些代码实现,一开始没考虑那么多,现在就需要考虑了,这些代码分散在工程里,到处都是,你得一条一条拆,也有可能需要在 ORM 框架层面动手脚(比如做个 Proxy 之类的)。
至于 TIBD,我没有使用过,所以无法推荐(或不推荐),不过楼主的确可以一试。而且,上亿级数据放在 MySQL 里,会死。
可以看一下 ProxySQL 它能满足你提到的这些需求: https://github.com/sysown/proxysql
另外一个是 Vitess 但我对它不熟,听 Github 的人说他们在评估这个,你也可以看一下: https://github.com/vitessio/vitess
是我一激动没说清楚。。
我本来是想说,MySQL 里单表存这么多数据,查询效率会非常低;MySQL 一般到千万级就可以做分表了。
非常感谢大家的积极回答,你们的每一个意见和建议对我都有或多或少的帮助
最近有点少来了
目前先用octopus
能用,有点丑陋
module CoreExt
module ActiveRecord
module ConnectionAdapters
module ExecutionControl
# 切换TiDB connection
def tidb_conn
::ActiveRecord::Base.connection_proxy.current_shard = :tidb
::ActiveRecord::Base.connection_proxy
end
# 记录当前线程使用的connection,当切换tidb后,一直使用tidb
def current_connection
Thread.current['octopus.select_connection'] ||= :master
end
def current_connection=(shard_symbol)
Thread.current['octopus.select_connection'] = shard_symbol
end
def execute(*args)
# 只拦截 SELECT 并且是白名单内的
return super unless args.first =~ /^SELECT/
# 这里很蠢,用args.last的"Order Load"来判断当前select table
return super unless WHITELIST.include?(args.last[0...-5])
if ::ActiveRecord::Base.connection_proxy.current_shard == :master
if self.current_connection == :master
result = super
return result if result.count > 0
self.current_connection = :tidb
end
result = tidb_conn.select_connection.execute(args.first, args.last)
else
result = super
self.current_connection = :tidb
end
::ActiveRecord::Base.connection_proxy.clean_connection_proxy
result
end
private
# 需要使用tidb的 table 名单
WHITELIST = ["Order"...]
end
end
end
end
ActiveRecord::ConnectionAdapters::Mysql2Adapter.include CoreExt::ActiveRecord::ConnectionAdapters::ExecutionControl
这个贴先结了吧,有问题再重新开一个
再次感谢大家!!!
