-
你们写程序是用 if 多,还是用 unless 多? at 2022年03月03日
我脑容量比较小,每次看到 unless 会卡壳。所以写代码会倾向于用
if !xxx,但是 RubyMine 会自作聪明的帮我改成 unless. -
not in 踩坑记录 at 2022年02月14日
PostgreSQL 和 MySQL 的默认索引结构是个 B+ tree,
not in和!=都没有办法利用索引,导致全表扫描。如果存在被屏蔽的黑名单用户,我是宁可建一个冗余字段 status 然后
select * from users where status = 'active' and xxx = xxx因为 status 只有几个数值,建了索引效果也不好,一定得跟着一个其他的过滤条件。比如 company_id = xxxxx。
-
搭了一个 forem at 2022年02月10日
看上去真不错啊,这个和 discourse 什么区别?
-
[上海] SAP 诚聘 Web 前端工程师 at 2022年02月03日
你发垃圾信息,真是发错地方了。
我把你的账户封了。
-
[上海][2021 年 12 月 28 日] Ruby / Rails 线下聚会召集 at 2021年12月27日
Jetbrains 刚好又给了一个优惠券,到时候发给大家。
-
有哪些,是项目开始运行甚至成熟后,非常后悔没有提前配置或加上的? at 2021年12月06日
权限是要加的,scope 也是要加的,比如 company.resources.find_by()
uuid 可以保证第二道防线。
-
有哪些,是项目开始运行甚至成熟后,非常后悔没有提前配置或加上的? at 2021年12月05日
我后悔“一开始为什么不在每张表里创建 UUID 这个字段”
作为企业级应用,给前端返回数据时,用 integer id 很危险,很容易被人按照顺序爬数据,暴露了不属于当前客户的资源。
如果用 uuid,即使自己不小心写了有问题的代码,UUID 可以作为第二道防线。
-
有哪些,是项目开始运行甚至成熟后,非常后悔没有提前配置或加上的? at 2021年12月05日
我后悔“一开始就测试写太多,代码写的太完善”,就是大家说的 'premature optimization'。
因为和客户聊后,发现需求变来变去,一开始写的很多测试都白写了,浪费了大量时间。
-
关于如何系统提升自己专业能力的问题? at 2021年11月25日
-
关于如何系统提升自己专业能力的问题? at 2021年11月25日
-
关于如何系统提升自己专业能力的问题? at 2021年11月25日
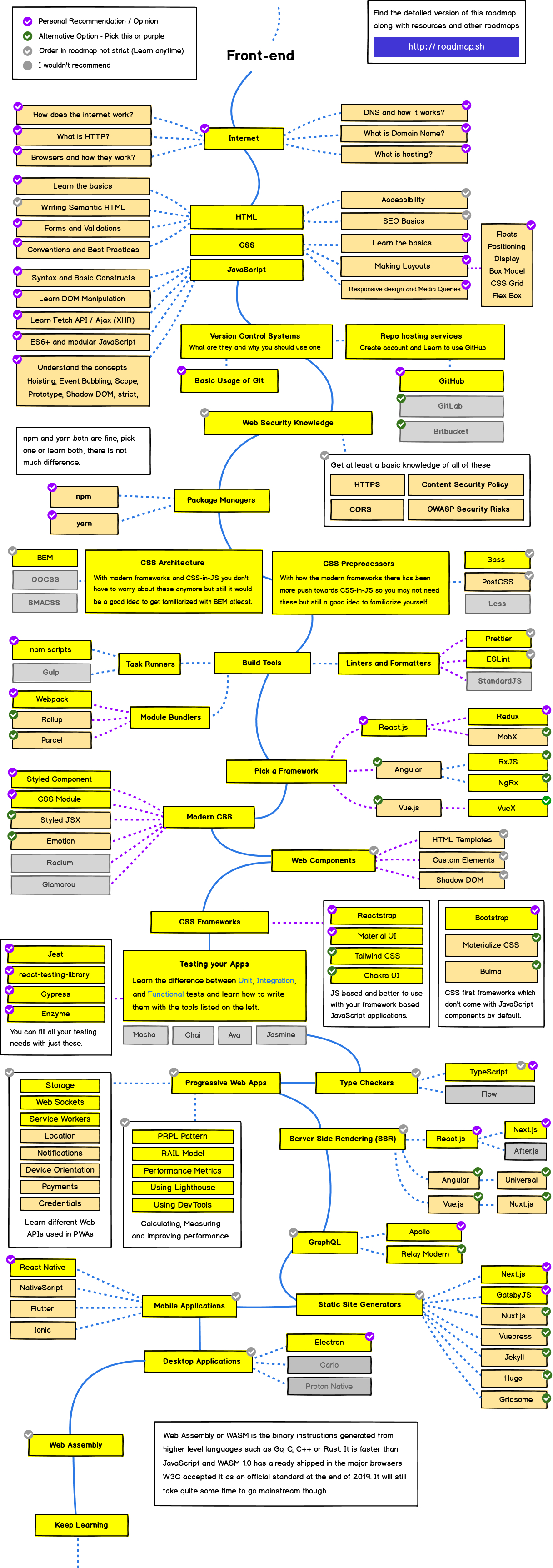
Back-end Roadmap
-
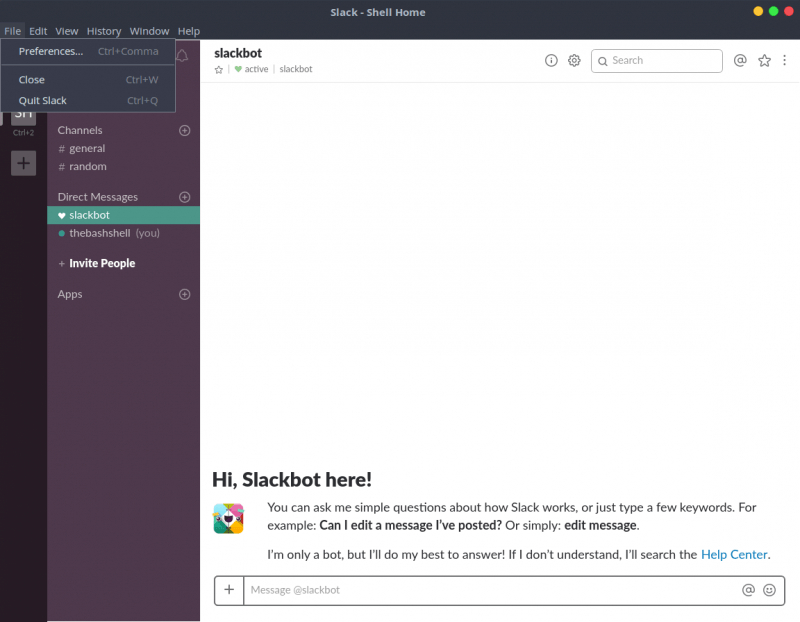
electron 是不是就是无头浏览器? at 2021年11月15日
Slack 的客户端,也是用 Electron 写的
-
electron 是不是就是无头浏览器? at 2021年11月15日
Electron 很强大的,Visual Studio Code 就是用 Electron 写的。
-
我的论坛类 SideProject 但反响不好 求提点意见 at 2021年11月11日
-
我的论坛类 SideProject 但反响不好 求提点意见 at 2021年11月10日
作为一个大龄青年,给点反馈:你可以把产品的目标放到需要找点乐子的人身上。
有了孩子之后,总是觉得时间太少,更不愿意和和别人闲聊。但凡有可支配时间,基本上都是直奔主题,都花在了这些方面:
- 出去锻炼
- Udemy,极客时间,Oreily
- 写 side project,尝试点新东西
- 读书
- 和老朋友面对面的聊天
我这种 35 岁 + 的人应该不是你们的目标客户,我懒的去认识一些泛泛之交的朋友,懒得打游戏,懒得去消磨时光。说来讽刺,作为一个 IT 从业者,业余时间却不愿意花一秒钟泡在技术营造的各种社交软件里。
-
最好用的 10 款 MySQL 管理工具横向测评 - 免费和付费到底怎么选? at 2021年11月03日
各种工具用下来,还是 Jetbrains 家的 Datagrip 最好,差不多支持所有数据库,PG,MySQL 等等。
https://www.jetbrains.com/datagrip/
欢迎参加 Ruby Tuesday 上海线下活动,每次活动赠送一个 Jetbrain license。
-
Foreman 是干什么的? 为什么不用 systemd ? at 2021年10月15日
非常感谢你提供使用方法,但我问题是“为什么用 foreman?它和 systemd 的渊源是什么?”
此外我不打算使用它,有两点原因。
1. capistrano-puma 和 capistrano-sidekiq 都提供了脚本生成 systemd 文件,我感觉没有必要再引入一个 gem 做抽象。
cap production sidekiq:install cap production puma:systemd:config2. 我基本上不会在本地起守护进程,通常都是开一个新的 terminal 的 tab,然后运行
bundle exec sidekiq你通常会在本地使用 foreman 吗?
-
Gemfile.lock 中的 Platform 是什么意思? at 2021年09月27日
我刚才试了一下这个命令
bundle lock --add-platform jruby bundle lock --add-platform mingw结果发现 Gemfile.lock 中的 nokogiri 下载了好几个版本。
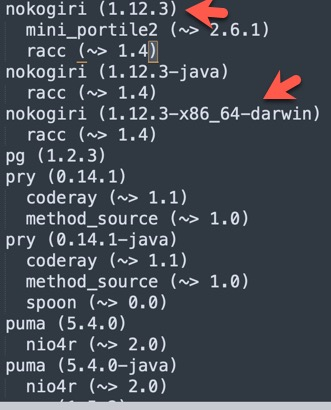
如果有些版本需要编译,我的 Mac 电脑下载了 windows 版本,也无法编译啊。
难道 Gem 不同 platform 的版本,都是预先编译好的吗?
(请熟悉编译的同学指导一下)
cc @rocLv
-
Gemfile.lock 中的 Platform 是什么意思? at 2021年09月27日
这是 bundler 作者的答复,但是我还是没 get 到他的点。
https://github.com/rubygems/rubygems/issues/4269#issuecomment-758564690
Hi @schneems!
So, I've been sleeping on this issue, and I think what we have now is quite good to be honest. Let me try to explain why we did this, and why I believe it's a good thing.
Context
In previous bundler versions, bundler didn't consider platforms for resolution at all. What bundler would previously do is to resolve dependencies without considering platforms, and then at installation time, pick up platform specific variants with the same version as the resolved version if they exist. That approach had several problems:
- Resolution correctness. Resolution would be incorrect sometimes, since it can happen that for the same gem and version number, a platform specific variant can have different dependencies than the standard variant. Without considering the specific platform for resolution, we might not get a valid set of dependencies, since new unconsidered constraints can be introduced after resolution. This is rare, but not that rare. For example, nokogiri recently released prerelease versions meeting this condition.
-
Safety. Not only resolution is invalid, but the previous approach meant resolution was not actually fully locked. Say you're using
foo-1.2.0in your application. You have a lockfile specifically locking foo to 1.2.0, you test it in CI and in your staging environment, and it's all good. Then someone pushesfoo-1.2.0-x86_64-linuxto rubygems.org, a platform specific variant for foo 1.2.0, that, for example, has a critical bug, or that was pushed by a malicious actor. Then when you deploy to production,foo-1.2.0-x86_64-linuxwill be installed because it matches the running platform more closely. To me this is totally unexpected, if you have aGemfile.lockfile, no third party release should be able to change the set of third party code that you run.
Resolving for the specific running platform and recording the exact resolution in the lockfile fixes the above issues.
Current situation
- I believe we can improve on it but the current error message is not too bad, and allows for easily fixing the issue.
- This error will only happen if you are using bundler in frozen mode (with
BUNDLE_FROZENorBUNDLE_DEPLOYMENT). If you're not using frozen mode, then bundler will automatically re-resolve using the running platform if it's not already in the lockfile. If you are using frozen mode, I believe it means that you explicitly want to avoid the second issue I mentioned above, so... an error if that can't be guaranteed seems appropriate. -
Yes, some tutorials could be broken by this, but only under some circumstances:
- If the tutorial provides a
Gemfile.lockthen bundler will respect that. Meaning, if the lockfile was generated with previous bundler versions, bundler will still fallback to how it worked in previous versions. But if you generate a lockfile from scratch, then it will use the more secure and correct mode. - If the tutorial does not set frozen mode, then bundler will re-resolve and just work as mentioned above.
- If the two above are not met, yes, things can break, but just like they could break if there's a new Rails release or whatever dependencies the tutorial uses. I believe that's acceptable, but I'm willing to help updating any popular tutorials that we detect to be affected by this.
- If the tutorial provides a
Please let me know what you think.
-
如果应用没有负载均衡之类的需求,只是单机部署,用 puma 和 nginx 起服务是不是没有区别呢? at 2021年09月26日
现在大家都上云了,通常整个 flow 是这样的:Application Load Balancer -> Nginx -> Puma
今天我也有类似的疑问,如果有了 ALB,还需要 Nginx 吗?
看完 2 楼的回答,豁然开朗,Nginx 还是需要的。
-
「大型 Q&A」有人对开发 Shopify App 感兴趣吗? at 2021年09月23日
很好奇 shopify 是如何集成各个 shopify app 的。有空我也学习一下,借鉴一下他们的实现思路。
- 怎么加载 shopify app
- 怎么部署 shopify app
- 等等。
-
使用 MySQL 持久化数据时没有同步的问题 at 2021年09月14日
以下两种情况会导致你所说的问题。
1. after_save
你推送 id 进入 RabbitMQ 的逻辑用的是
after_save而不是after_commit.通常 DB 有四个级别,serializable, repeatable read, read commit, read uncommitted. MySQL 默认隔离级别是
repeatable read,不同 transaction 内部未提交数据,对于其他 transaction 不可见,避免了 dirty read, phantom read 的问题。after_save 时,数据库的事务还没提交,其他事务是看不到你创建的记录的。数据库的隔离级别是一个很有意思的话题,是很多面试必考题目,值得学习。
解决方法:使用
after_commit就可以避免类似 bug。2. 数据库读写分离的延迟
primary 和 replica 之间通常有 0.5-10 秒的延迟。在延迟很高的情况下,你的写入成功了,但是从库却没有数据。
解决思路有三种
发送消息时,延迟 10 秒。比如像 sidekiq 的 MyJob.perform_in(10.minutes)
你可以强制这个任务读写都使用 primary database。
使用计算和存储分离的数据库,比如 Aurora,数据库节点之间 0 延迟。
-
[上海][2021-09-14] Ruby 聚会召集 (因为台风取消本次活动) at 2021年09月13日
@oslivan-github @xmonkeycn @ericguo @kowalskidark @zfben @lifeixiong
因为台风的原因,本周二活动延期。
-
[上海][2021-09-14] Ruby 聚会召集 (因为台风取消本次活动) at 2021年09月06日
我把你的主题加进去了。
-
北美的美团 - Chowbus 中国研发中心招聘 Ruby/Go 后端工程师 at 2021年09月02日
给邻居点个赞。
-
哪个基于 Rails 的开源博客系统比较开放、体验较好? at 2021年08月30日
hugo 也不错。
-
Rails 4 以后跟后端没关系了 at 2021年08月28日
真是愁啊,本来今年想学学前端,结果前端又出了幺蛾子。
(就在我发这条评论时,又有个前端工具诞生了)
-
Rails 4 以后跟后端没关系了 at 2021年08月28日
过去为了优化前端的加载速度,大家会把把很多小 javascript 打包为一个大文件。
HTTP/2 支持多路复用,这让过去的最佳实践变的没有意义。这是大家去掉 webpack 的原因之一吗?