-
Recurrent Neural Network (RNN) Introduction at 2025年12月27日
只是好奇心比较重

-
10 年开发后,我后悔坚持的 8 个技术信仰,不知你踩中几个 at 2025年09月18日
Serverless,如果这玩应省的钱,可以给你雇佣几个工程师,那为什么不用?如果不能,用它不是闲的吗。不是说技术怎么样,而是你理不理解,用的对不对。ORM 也类似,知道为什么用,知道它的上限在哪。再多数一句,多数 web 服务,性能都不是什么大问题,可扩展性才是。
别太相信自己的经验,一个人的经验是有限,方向错了,时间也很难弥补。推荐看看 Berkeley cs50 和 MIT 的 system design 或者 distributed system。--- 我特别喜欢给那些喜欢琢磨命名的程序员推荐这些,个人的恶乐趣。
-
新人想学 Ruby,大家伙从业多年的来给些意见呢,谢谢 at 2025年06月23日
如果之前学过一门语言,直接写/让 AI 写就行,不懂的就问 AI。语言没那么重要了。
Rails 了解一下它的哲学,细节也不需要知道,有 AI。
除非是你想当 Ruby 的熟练工,那最好多学一些。
再就是找一个难度合适的项目练手,ruby 资料很多,遇到问题问 AI,查文档就行。
-
How SDB Scans the Ruby Stack Without the GVL at 2025年02月11日
我从 18 年开始就看类似的事情了,琢磨的时间比较久吧

我智商平平,有的时候还挺蠢,但耐心还行。经历上算是吃过见过,看的东西应该不算少吧。
-
使用 Rails 8 提供的默认任务队列 Solid Queue at 2025年01月10日
Martin Kleppmann 的回复。
Update 9 Feb 2016: Salvatore, the original author of Redlock, has posted a rebuttal to this article (see also HN discussion). He makes some good points, but I stand by my conclusions. I may elaborate in a follow-up post if I have time, but please form your own opinions – and please consult the references below, many of which have received rigorous academic peer review (unlike either of our blog posts).
He makes some good points, but I stand by my conclusions. 说明没办法说服 Martin Kleppmann。Martin 说有时间会回复,但并没有,有可能说明这些 good points 并不值得在写一篇东西。
我也完全同意 Martin 这句 please form your own opinions – and please consult the references below。
-
使用 Rails 8 提供的默认任务队列 Solid Queue at 2025年01月09日
https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
Before I go into the details of Redlock, let me say that I quite like Redis, and I have successfully used it in production in the past. I think it’s a good fit in situations where you want to share some transient, approximate, fast-changing data between servers, and where it’s not a big deal if you occasionally lose that data for whatever reason.
-
聊聊代码的复杂性 at 2025年01月07日
可以以产品经理的身份在产品的角度优化一下
这个国内有叫需求让步的,英文里是 trade-off,软件/系统设计常用手段。
设计的话,个人喜欢这本 Principles of Computer System Design: An Introduction
前司更喜欢聊架构,代码方面的没人花心思说。技术负责人,有不少开源项目,代码质量没啥问题。不过他不会强调这些,也没人聊这个。
-
使用 Rails 8 提供的默认任务队列 Solid Queue at 2025年01月04日
我想说的是,Redis 虽然用在缓存挺合适的,用在异步队列,除非大家不在意丢偶尔会丢。
Before I go into the details of Redlock, let me say that I quite like Redis, and I have successfully used it in production in the past. I think it’s a good fit in situations where you want to share some transient, approximate, fast-changing data between servers, and where it’s not a big deal if you occasionally lose that data for whatever reason.
-
使用 Rails 8 提供的默认任务队列 Solid Queue at 2025年01月04日
我一直没搞懂,为啥要用 Redis 作为异步队列的存储。
我一直认为,除了缓存,使用 redis 都不是一个严肃的事情。
https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
-
PostgreSQL 数据库删除外键约束引发的死锁问题 at 2024年12月14日
学习了,感谢大佬分享!
线上问题排查不容易!
-
今天使用 cap 发布,遇到了 puma 随机占用 CPU 100% at 2024年11月25日
可以试试 stack profiler,rbspy,vernier 之类的。
-
无 root 权限、证书查看 Ruby HTTPS 请求内容 at 2024年09月18日
https://github.com/yfractal/sdb/pull/4 可以查看 http 了,同样不需要 root 权限。
-
Rust2go: calls Go from Rust at 2024年06月27日
sorry, I don't know the answer. Maybe need to ask Rust2go's author. I guess it's much faster than Thrift or Protocol Buffers as it doesn't need deep copy except go returns variable to rust. I think this copy can be avoided too, if Go can keep an additional reference of the variable and let Rust release the reference when it is dropped.
-
Rust2go: calls Go from Rust at 2024年06月27日
I believe this is achievable, this article introduces similar things
https://metalbear.co/blog/hooking-go-from-rust-hitchhikers-guide-to-the-go-laxy/
-
eBPF USDT in Rust at 2024年05月23日
哈哈哈,是的。
-
希望各位前辈能给到我一些建议 at 2023年08月20日
多跟你身边的人聊聊,大公司人多,有技术好的人概率更大,看看他们怎么看待后端开发,框架是后端很小的一部分。
做 Rails 的,多数是小项目。全栈,确实开发更快。但项目复杂、难度大的项目,能把后端的事情做好的程序员都不多,更别说再做前端开发。
-
什么差异导致了 AI 领域选择了 py 而不是 rb? at 2023年07月14日
-
GitHub 网站的代码是基于 Ruby on Rails 的;他们每周都升级到 Rails 的 main branch 最新的 commit,一直都用最新版的 Rails;真是艺高人胆大 at 2023年05月06日
Github 这种服务,三天两头挂。。。
-
如何看待 RESTFUL 规范?你们的后端接口是否仍遵守这个规范呢? at 2023年03月25日
有利有弊,听老板的。
-
解决搜索问题就一定要上 ElasticSearch 吗? at 2023年02月21日
 需求需要技术支撑,有的时候,需求在现有的情况下,不那么合理,就需要需求让步。所谓的 trade-off。
需求需要技术支撑,有的时候,需求在现有的情况下,不那么合理,就需要需求让步。所谓的 trade-off。选用 ES 一个主要原因是性能。数据库 like 扛不住了,或者不想影响其他查询太多,所以才上 ES。ES 简单的找找文档就能搞定,真正优化什么的,就需要深入研究。
技术影响需求,到了一定阈值,甚至决定了需求。比如延迟超过 10s,这个就不仅仅是技术问题,而是需求问题了。
-
从业绩的春天到发不起工资的寒冬 at 2023年02月14日
技术是工具,或者说是手段,不是目的。
之前的 leader,说他刚来的时候,技术上还会管管我们。之后我们都进入角色了,技术就不怎么需要他了。这个时候,他主要任务是忽悠产品,砍需求,在技术和产品之间找平衡。以及教育他的领导没事少管闲事,这个是他的领导在全体会议上说的。
-
程序员的悲哀是什么?(怎么看?) at 2023年01月11日
说事就说事呗,抒啥情啊。。。说了一大堆,观点不明确,数据也没有。。。
还不如找个算命的聊聊天,或者看看成功学找找自我安慰。
神烦这种,指点人生的人。
-
Ruby 3.2 带来的 YJIT 性能提升提升 ~40% at 2022年12月30日
lead 这个项目的人有博士学位,之后一直做 compiler 相关的工作。
-
分布式 ID 有什么好的建议 at 2022年10月14日
这个 id 都是从一个 Redis 里拿。
-
分布式 ID 有什么好的建议 at 2022年10月12日
哈哈哈哈,Redis 这种太粗糙了
只试用与可用性要求不高,还可以重试的场景。 -
分布式 ID 有什么好的建议 at 2022年10月12日
线上跑的单机,偶尔并发高会出现重复 id 插入失败
多线程,需要锁。
这对数据库查询性能是不是有影响
没影响,数据是大体离散的。除非有非常特别的 query。
要不用 Redis INCR key 算了。Redis 单机性能可以 6w+,够用了。如果这个的 qps 10w+,当我没说。
-
Ruby 有协程吗? at 2022年10月10日
一些有趣的问题
- 既然有系统线程了,为什么还要搞协程
- 为什么叫协程
- 对编程有什么影响
- 怎么实现的
-
有人想聊聊 Shopify 新出的 app server pitchfork 吗? at 2022年10月09日
先说我的想法,如果 fork 频繁的话,有可能会影响性能。
首先这个是针对 low delay 的 request,比如 20m 这种,而且也只是猜测。然后,我觉得这个大概率会被打脸,毕竟 Shopify 有很多优化经验。但技术吗,要抱着怀疑的态度去看,要大胆假设,小心求证。打脸了也是次学习的机会。
下面会先介绍一下我对这个 Gem 和相关问题的理解。为什么会觉得有性能问题,压测以及有的没的。
Background
因为一般 web server 都是无状态的,所以很容易横向扩展。流量一台扛不住,我就再加一台。如果一个 app server 需要内存 2GB,我们搞两个,就需要 4GB。但实际上,这两个 sever 跑的代码是一样的,那么共享代码占用的内存,就可以省很多的内存。比如从 4GB 降到 2.2GB。而操作系统刚好提供了 copy on write(COW)。
操作系统在 fork 进程的时候,不会 copy 物理内存,而是只写一个新的 page table,物理内存是同一份。当某个进程改内存的时候,就需要 trigger page fault exception,操作系统处理这个 exception 的时候,要 duplicate 一下内存,以及改 page table 的映射,之后回到抛异常的指令,再执行一次。这个就是 cow 大致的工作原理。
看起来,我们 fork Ruby 应用,就可以省很多内存,但实际上并没有,因为 Ruby 应用在运行的时候,会改很多的内存(我还不知道啥原因,Ruby 是解释型语言,代码应该是丢在 data 那块的,可能跟 GC 之类的有关),这样导致被共享的内存越来越少,内存也越用越多。
pitchfork 的解决方案是隔一段时间,回收进程,然后再创建新的。
Will it hurts performance?
我们知道,随着 Ruby 应用的运行,被共享的内存越来越少,如果为了省内存,就不能太久 fork 一次。但 fork 对性能是有影响的,如果频繁的 fork,虽然省了内存,但会影响性能。或者说,我们要知道,多久 fork 一次,会省多少内存,以及对性能有什么样的影响。
pitchfork 压测用的参数是
refork_after [50, 100, 1000],我们这里先按照,当一个进程,处理了 50 次请求,就会重新 fork 一次。假设一个请求是 20ms,50 次请求,共消耗 1000ms。然后回收这个 process 再 fork 新的。假设应用消耗 2GB 内存,在这 1s 内,需要写 200MB 的内存。
现在我们来看,系统需要多少时间进行处理。一个 generation(回收旧的,fork 新的),系统需要做的事情有,回收进程,fork 新进程,以及处理 page fault。
fork 新进程根据下面这个图 [1],fork 2GB 的进程大约需要 10ms。回收进程,虽然系统会用 lazy 来处理,我们可以假设这个会分担到每个 generation。回收进程消耗的时间要比 fork 多,因为 fork 只写 page table 但回收进程的时候,要擦掉非共享内存里的内容,所以要大于 10ms(这个地方,八成是错的,因为系统这块似乎也有优化,似乎是没有 0 的 table 才会去擦除)。
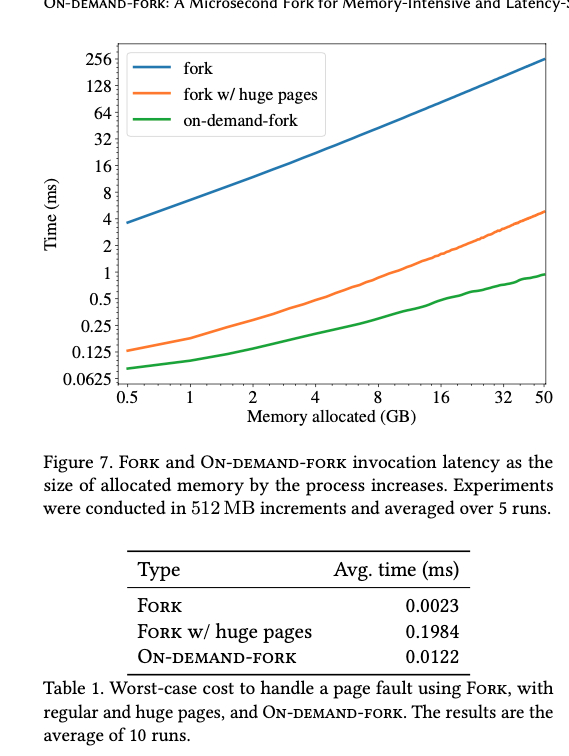
现在我们来算 page fault 产生的影响。根据假设,一个 generation 需要写 200MB 的内存,一个 page 是 4kb(咱不考虑什么 huge page,这个应该是全局的设置),每次 page fault 需要 0.0023s,依旧是需要 200 mb * 1000kb/mb / 4kb * 0.0023 = 111.5 ms。
那么系统上要消耗大约是 1 - 1000 / (1000 + 111.5) ~ 10%
这种算法有没有问题?有。比如 50 次请求,只多了 10MB 的内存,那损耗可能只有 1% 左右。再或者,系统处理 page fault 时有优化,比如做了 batch,那就会更快。再比如时间数据是有问题的。等等等等,都影响结论。所以需要具体 benchmark。
这里不是说会有影响,而是说,经过分析,发现有可能有影响,所以需要 benchmark 来验证。
Benchmark
第一个变量是多久 fork 一次,需要给不同频率的 fork 对应的内存使用。最好用比较真实的项目和比较真实的流量,比如 RubyChina。最后还可以有就是做长时间压测。
第二个变量是性能影响。一个是系统多花了多少时间,p50,p99 的延迟。
这个 Gem 毕竟刚开始开发,相信之后会有人给出更详细的 benchmark。
Others
个人比较好奇,为啥 Ruby fork 后,随着进程运行,会有内存的问题。以及为啥不好在 Ruby 层面改。和有没有其他解决方案。
References
- On-demand-fork: A Microsecond Fork for Memory-Intensive and Latency-Sensitive Applications https://www.cs.purdue.edu/homes/pfonseca/papers/eurosys21-odf.pdf
-
PostgreSQL 数据库存放路径初窥探 at 2022年09月28日
-
PostgreSQL 数据库存放路径初窥探 at 2022年09月28日
