先说我的想法,如果 fork 频繁的话,有可能会影响性能。
首先这个是针对 low delay 的 request,比如 20m 这种,而且也只是猜测。然后,我觉得这个大概率会被打脸,毕竟 Shopify 有很多优化经验。但技术吗,要抱着怀疑的态度去看,要大胆假设,小心求证。打脸了也是次学习的机会。
下面会先介绍一下我对这个 Gem 和相关问题的理解。为什么会觉得有性能问题,压测以及有的没的。
Background
因为一般 web server 都是无状态的,所以很容易横向扩展。流量一台扛不住,我就再加一台。如果一个 app server 需要内存 2GB,我们搞两个,就需要 4GB。但实际上,这两个 sever 跑的代码是一样的,那么共享代码占用的内存,就可以省很多的内存。比如从 4GB 降到 2.2GB。而操作系统刚好提供了 copy on write(COW)。
操作系统在 fork 进程的时候,不会 copy 物理内存,而是只写一个新的 page table,物理内存是同一份。当某个进程改内存的时候,就需要 trigger page fault exception,操作系统处理这个 exception 的时候,要 duplicate 一下内存,以及改 page table 的映射,之后回到抛异常的指令,再执行一次。这个就是 cow 大致的工作原理。
看起来,我们 fork Ruby 应用,就可以省很多内存,但实际上并没有,因为 Ruby 应用在运行的时候,会改很多的内存(我还不知道啥原因,Ruby 是解释型语言,代码应该是丢在 data 那块的,可能跟 GC 之类的有关),这样导致被共享的内存越来越少,内存也越用越多。
pitchfork 的解决方案是隔一段时间,回收进程,然后再创建新的。
我们知道,随着 Ruby 应用的运行,被共享的内存越来越少,如果为了省内存,就不能太久 fork 一次。但 fork 对性能是有影响的,如果频繁的 fork,虽然省了内存,但会影响性能。或者说,我们要知道,多久 fork 一次,会省多少内存,以及对性能有什么样的影响。
pitchfork 压测用的参数是 refork_after [50, 100, 1000],我们这里先按照,当一个进程,处理了 50 次请求,就会重新 fork 一次。
假设一个请求是 20ms,50 次请求,共消耗 1000ms。然后回收这个 process 再 fork 新的。假设应用消耗 2GB 内存,在这 1s 内,需要写 200MB 的内存。
现在我们来看,系统需要多少时间进行处理。一个 generation(回收旧的,fork 新的),系统需要做的事情有,回收进程,fork 新进程,以及处理 page fault。
fork 新进程根据下面这个图 [1],fork 2GB 的进程大约需要 10ms。回收进程,虽然系统会用 lazy 来处理,我们可以假设这个会分担到每个 generation。回收进程消耗的时间要比 fork 多,因为 fork 只写 page table 但回收进程的时候,要擦掉非共享内存里的内容,所以要大于 10ms(这个地方,八成是错的,因为系统这块似乎也有优化,似乎是没有 0 的 table 才会去擦除)。
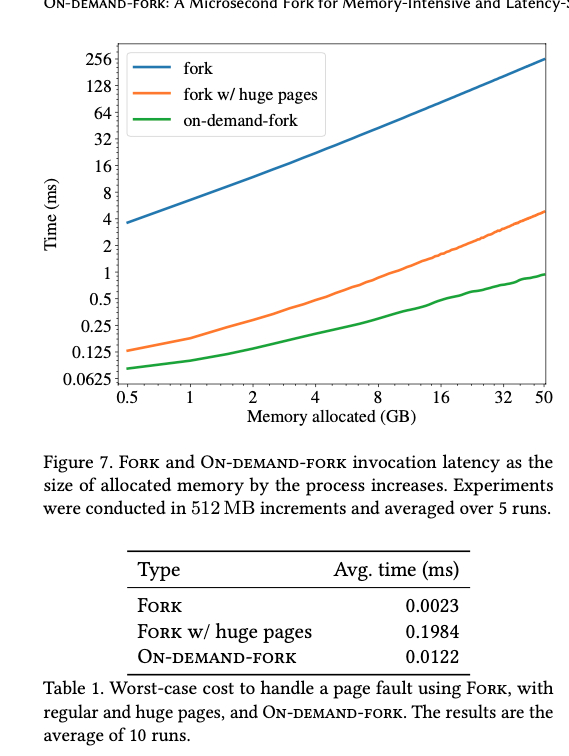
现在我们来算 page fault 产生的影响。根据假设,一个 generation 需要写 200MB 的内存,一个 page 是 4kb(咱不考虑什么 huge page,这个应该是全局的设置),每次 page fault 需要 0.0023s,依旧是需要 200 mb * 1000kb/mb / 4kb * 0.0023 = 111.5 ms。
那么系统上要消耗大约是 1 - 1000 / (1000 + 111.5) ~ 10%
这种算法有没有问题?有。比如 50 次请求,只多了 10MB 的内存,那损耗可能只有 1% 左右。再或者,系统处理 page fault 时有优化,比如做了 batch,那就会更快。再比如时间数据是有问题的。等等等等,都影响结论。所以需要具体 benchmark。
这里不是说会有影响,而是说,经过分析,发现有可能有影响,所以需要 benchmark 来验证。
Benchmark
第一个变量是多久 fork 一次,需要给不同频率的 fork 对应的内存使用。最好用比较真实的项目和比较真实的流量,比如 RubyChina。最后还可以有就是做长时间压测。
第二个变量是性能影响。一个是系统多花了多少时间,p50,p99 的延迟。
这个 Gem 毕竟刚开始开发,相信之后会有人给出更详细的 benchmark。
Others
个人比较好奇,为啥 Ruby fork 后,随着进程运行,会有内存的问题。以及为啥不好在 Ruby 层面改。和有没有其他解决方案。
References
- On-demand-fork: A Microsecond Fork for Memory-Intensive and Latency-Sensitive Applications
https://www.cs.purdue.edu/homes/pfonseca/papers/eurosys21-odf.pdf