分享 RailsConf 2016 - 我们如何为三万人的公司横向伸缩 GitLab
以下是本人在刚刚举办的 RailsConf 2016 上的演讲,介绍支付宝如何改造 Gitlab,作为整个阿里巴巴集团的代码管理后台。译自视频 http://v.youku.com/v_show/id_XMTU4MzU3MjEzMg==.html
引子
当初我把这个题目提交给 RailsConf 主办方的时候,提交到了“分布式时代”这个主题中。然而最后我惊讶地发现,我的演讲好像是那个主题中唯一的一个,竟然没有别人讲 Rails 应用如何伸缩的问题,或是讲 Rails 的分布式设计问题。我觉得这恐怕是因为作为 Rails 开发者,我们在开发的时候就比较注重遵循最佳实践,从而不会使得项目后期的伸缩成为什么大难题。
但是今天这个 Rails 应用——GitLab——却真是个坏小子,我今天就来讲讲我们是怎么修理他的。谢谢大家来听我的这场演讲!
自我介绍
我的名字叫潘旻琦(孝达),我来自中国,是蚂蚁金服体验技术部的一员。这是我的 Github 主页:https://github.com/pmq20 和 Twitter 主页:https://twitter.com/psvr 。欢迎大家关注我的主页!
GitLab 是什么
其实,偷偷地讲,GitLab 就是一个 GitHub 的开源克隆版。但是这个讲法难登大雅之堂;应该说,GitLab 是一个可以独立安装在你自己的服务器上的 git 盒子,让你拥有一个私密的代码托管协作平台。
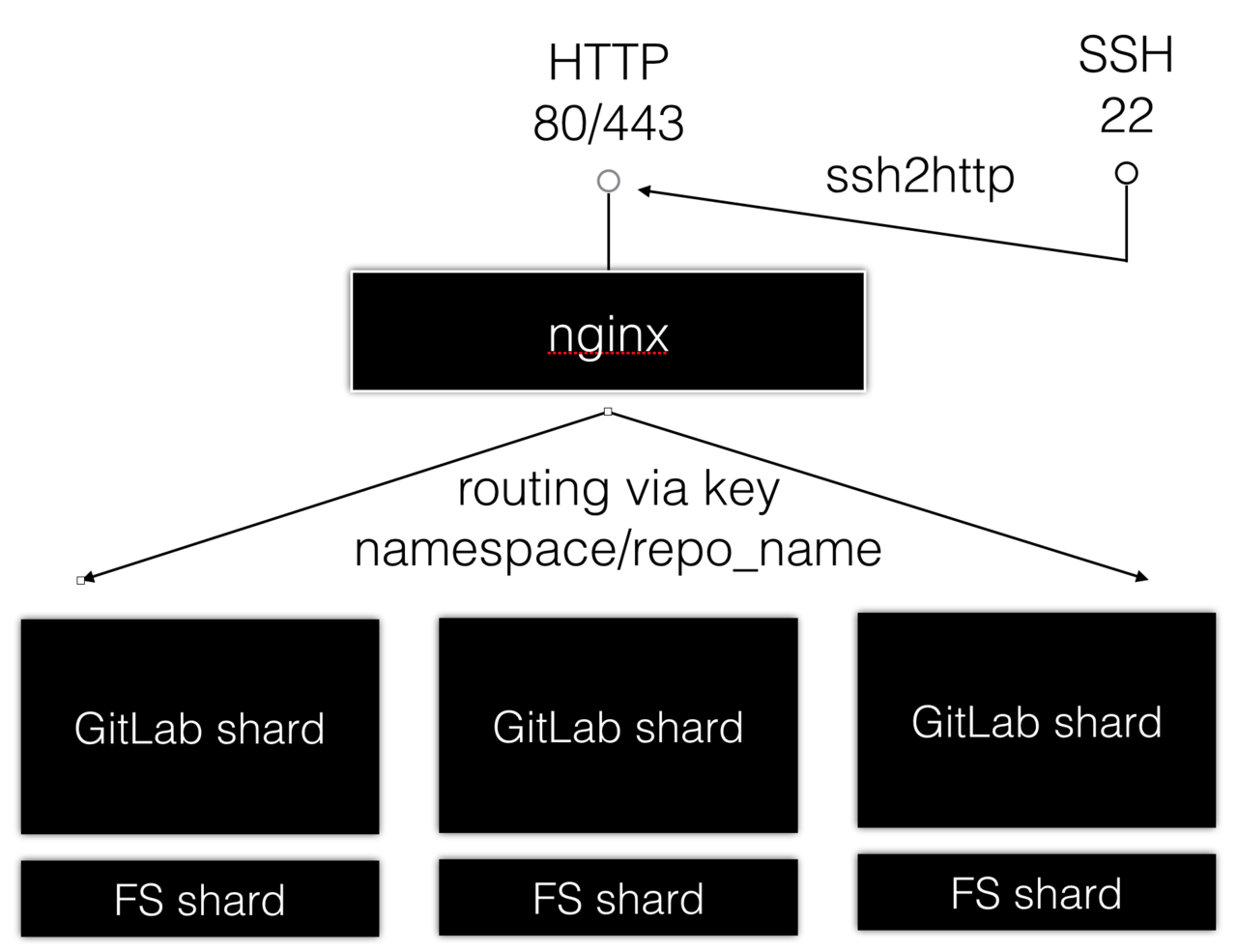
如果我们把 GitLab 看作一个黑盒,那么它对外无非提供了两个接口:一是 HTTP,二是 SSH。HTTP 接口不仅可以在浏览器上用,还可以在命令行上用。在命令行上,用户可以通过 HTTP 上传(git push)和下载(git fetch, git clone)代码;在浏览器上,作为一个 Rails 应用,用户可以进行各种页面上的交互操作,如浏览代码、发起 Merge Request、查看提交历史等。SSH 接口则相对简单,这个接口只能用在命令行上进行代码的上传下载。
在后端,以一个极度简化的视角来看,无非就是借助 git 来持久化用户传来的内容;然而成也萧何败也萧何,就是这一点导致了 GitLab 的横向伸缩难题。如果看得更仔细一点,GitLab 的数据持久层主要由三部分组成:一是文件系统,因为 GitLab 背后是通过调用 libgit2、git 命令、grit 来访问和操作存储在服务器文件系统上的 git 仓库;二是 MySQL,这个是用来持久化用户、权限、Merge Request 这些页面交互数据用的;还有 Redis,主要作 Sidekiq 的任务队列和 Rails 的缓存用。其实他们还支持 PostgreSQL,因为 ActiveRecord 抽象掉了底层数据源的具体实现。
接下来我们把 GitLab 打开,看看它的内部有哪些构造。一个简略的分层结构如图。
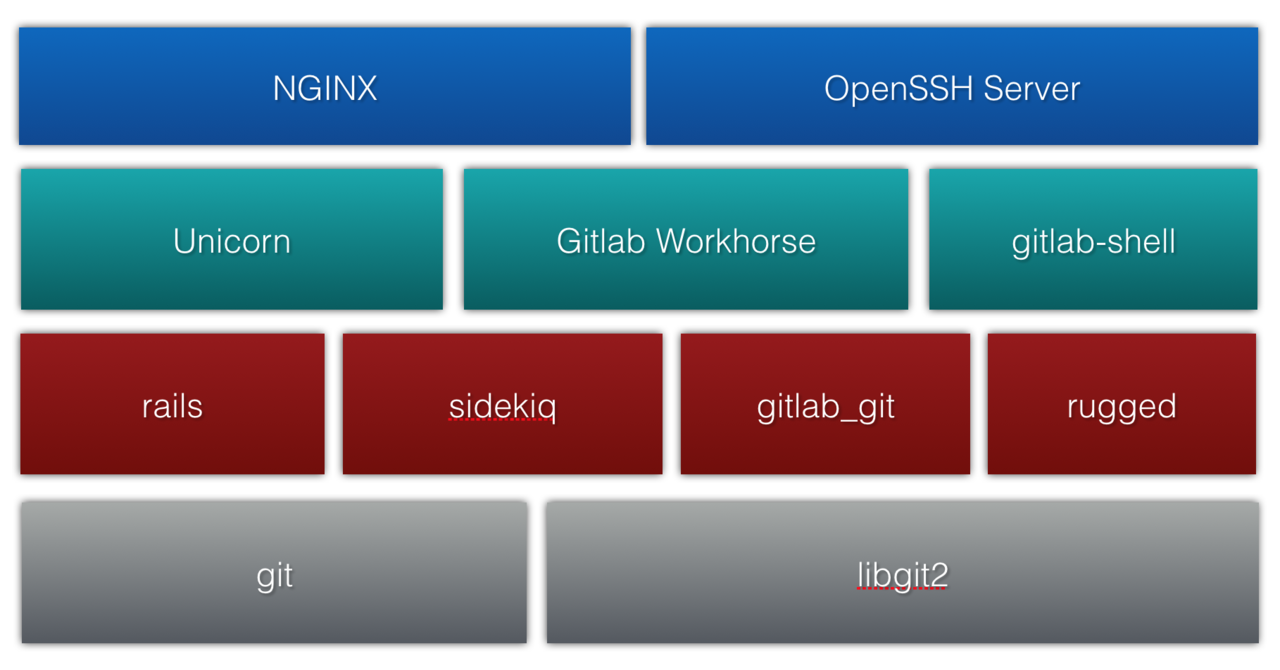
在最高层,Nginx 和 OpenSSH 分别用来接收客户端发来的 HTTP 和 SSH 请求。首先,当客户端发来的是一个 HTTP 页面请求,那么它会进入下一层的 Unicorn 进程,进而利用第三层的诸多 gem 获取关于仓库的信息或对仓库进行操作,这些 gem 包会调到第四层,通过调用原生 git 命令或通过调用 libgit2 中的函数对存在磁盘上的 git 仓库进行实际的访问和操作。其次,当客户端发来的是 HTTP 协议下的 git 操作,那么这个操作将直接被转向给 GitLab Workhorse,它会进一步借助 Unicorn 验证用户的操作权限,之后便将操作全然代理给第四层的原生 git 命令。因为这种请求不同于页面请求,是 I/O 繁重型,因此 GitLab Workhorse 用 go 写成,而不是 Ruby。最后,当客户端发来的是 SSH 协议下的 git 操作,OpenSSH 会在用户认证登陆成功后启动一个特殊的 shell——亦即 GitLab Shell——来调用第四层的原生 git 命令,而这个 shell 跟 Workhorse 类似,自身也不含用户逻辑,必须再内部调用 Unicorn 才能完成用户认证与鉴权工作。
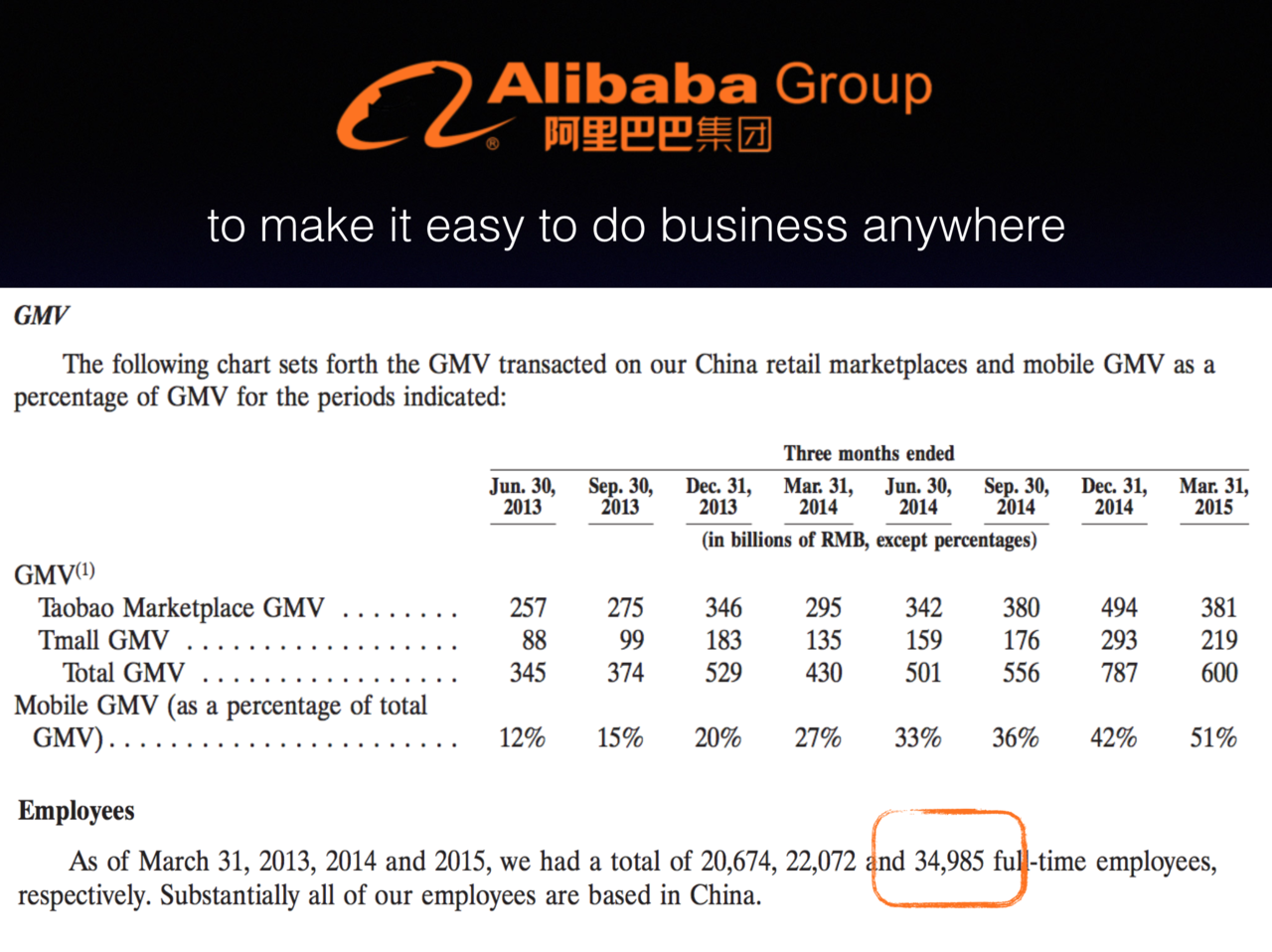
这个架构在小型开发团队中工作相当顺畅,但是很不幸,阿里巴巴有三万多员工,这个数字来自前年的财报,如图。就在我演讲的前几天去年的财报也公开出来了,股票价格又涨了不少,我们公司业绩相当给力哦。
横向伸缩 GitLab:前端
作为一名 Rails 程序员,系统中最容易的集群化部件就是 Unicorn 了,因为社区内有无数集群化部署 Unicorn 的文章,我们只要多跑几个 Unicorn 实例,再在前置服务器的 Nginx 中配几个 upstream server 就搞定了!
然并卵。Nginx 对于 HTTP 协议的负载均衡自然是得心应手,但别忘了还有 SSH。我们的前端机还必须能分发 SSH 请求,在这种需求下 Nginx 便不再合适了。为了解决这个问题我写了一个 gem 叫 ssh2http,源码在 https://github.com/pmq20/ssh2http 。它基本上消除了 SSH,而把请求的处理逻辑代理给了 HTTP。因为当对比 git 通过 SSH 及 HTTP 访问服务器的区别时,我们发现它们的通讯方式非常相似,所以写个代理问题就解决了。
但实际上我们没用这个方案,我们借助了阿里的中间件 VIPServer。VIPServer 是基于 Linux 内核 LVS 中的 IP Virtual Server(IPVS)机制实现的,它可以在 TCP/IP 的第四层上进行负载均衡,而不同于作用在第七层上的 Nginx。通过传输层复杂均衡,我们的前端机便可通吃 HTTP 与 SSH,因为负载均衡器已然对应用层的协议不可知了。当然这样也带来一些缺点,例如负载均衡器没法通过检查 HTTP 协议的返回值是否等于 200 来为集群机器的健康状态打分,因为这是应用层的逻辑。但基本的 IP 权重设置、IP 黑名单、简单的健康监测功能还是可以进行的。
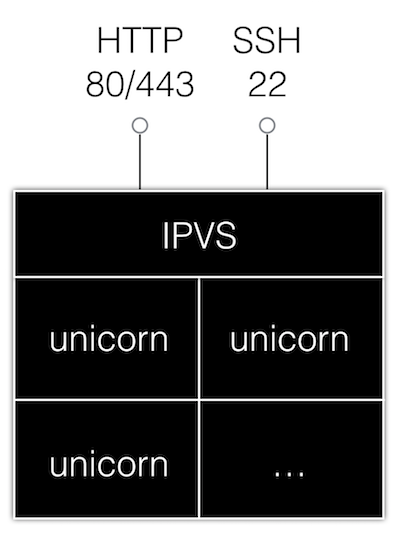
加入了 IPVS 之后那么问题来了,不光用户的 SSH 客户端开始抱怨同一个域名连接上的机器的 SSH 签名不一致,同一个用户通过网页添加的 SSH 密钥也只能允许他访问集群中的某台机器。为此,我们必须把集群中所有机器的 SSH 主机密钥设为一致,且必须在 rails 中将通过网页添加的 SSH 密钥广播给集群内的所有机器。用 sidekiq 实现这个不太合适,因为一个任务只能被集群中的一台机器抢占;我们是通过 redis 的 pub sub 数据结构来实现这一步的。
至此,前端的伸缩问题就解决了。
横向伸缩 GitLab:后端
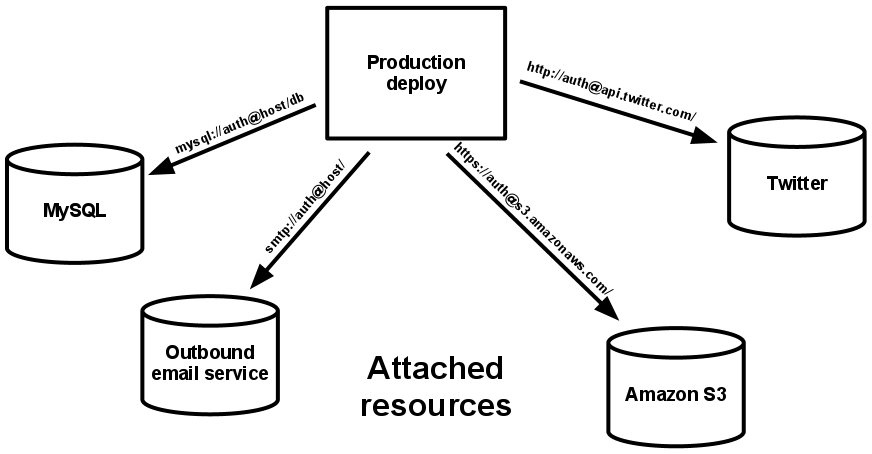
在讲我们的方案之前,我想暂停一下跟大家回忆受 Heroku 推崇的“The Twelve-Factor App”法则。之所以 GitLab 是个坏小子就是因为它没有遵守十二法则的第四条:“把后端服务当作附加资源”。对应用程序而言,不管是数据库、消息队列还是缓存,都应该是附加资源,通过一个 url 或是其他存储在配置中的服务定位来获取数据;部署应可以按需加载或卸载资源。然而 GitLab 系统中的三个组件——libgit2、git、grit——都是直接作用在文件系统上的,这就是万恶之源了。
其次,面临这样一个情况,我想提醒大家其实我们有很多选择,方案各有利弊,我接下来要详细讲的方案不一定适合你。如果将来你要伸缩其他的 Rails 应用,也可以按照类似的思路来思考问题。
一个方案是用官方企业版 8.5 以来加入的新功能 GitLab Geo。但 GitLab Geo 没有真正的解决问题,因为它是在集群中全量复制每一台上的 git 仓库的,没有分片。这个方案假定每台机器都有足够的磁盘空间来容纳全量的资源,但在阿里这个假设不成立,所以对我们来说用处不大。从分布式系统的角度评价,GitLab Geo 是一个一主多从、无分片全量复制的分布式系统,实现 CAP 定理中的 A 与 P。
另外一个方案是我们杜撰的,貌似很完美。首先,通过 ssh2http 消除 SSH,问题简化为纯粹的 HTTP 请求的问题。其次,注意到一个仓库的特征性名称是"namespace/repo_name",而且几乎每个请求的 URL 中都包含着个部分。那么我们直接通过这个名称作分片路由好了,只需要发明一个哈希算法,把"namespace/repo_name"哈希映射到集合 {0,1,2,...,cluster_size},便可以把所有请求在集群中分片分发,仓库也分片存储就好了。但这个方案也有问题,大家发现了吗?首先,别忘了 Sidekiq 也要分片啊!因为一个 unicorn 分片产生的任务只能由这个特定分片上的 Sidekiq 来处理,这样一搞复杂度很高。其次,应用层的修改也不能避免:例如,系统管理员的页面要列出仓库的列表,每个仓库后面还有大小,这个数据是跨分片的,只能考虑降级这种功能;类似这样的单请求跨分片场景应该还有很多。所以这条路并不好走。
那我们还是乖乖对付文件系统吧,我们有哪些办法呢?首先,我们可以使用网络附加存储设备,亦即硬 NAS(如 EMC 生产的存储设备),或使用软 NAS(如 Google File System);其次我们可以类似于 MySQL 的分片那样,将文件系统分片存储,然后通过远程过程调用的手法将请求发送到远程的文件系统上;最后,我们也可以整体去掉文件系统,将系统这部分进行改造。
在阿里实施去 IOE 战略后,硬 NAS 设备已不再属于集团考虑采购的范围;软 NAS 方案在阿里也不成熟,阿里目前还没有一个可以与谷歌的 GFS 媲美的内部中间件;RPC 的方案是可行的,而且是经过验证的,因为 GitHub 就是这样做的,可惜它不开源。因此,我们决心尝试第四个方案,我们打算去掉文件系统,改用用云端存储。
这里我们要提醒大家,使用 NAS 是值得考虑的。因为它很简单,我们只需替代掉系统中的一个组件,而无需引入接口的变化。但我们没有去走这条路,而且这条路也有它的问题:例如增加了运营成本,尤其是软 NAS,复杂度较高,需要能力很强的运维工程师来支持。其次,这个性能的损耗可能也比较严重,因为每个底层 FS I/O 都换成了较慢的网络 I/O;而且由于变化引入的位置在整个技术栈中处于的层次比较低,这种变慢的 I/O 的数量较大,做了乘法之后累积的延迟就大了。
我们走了第四条路——去掉文件系统,使用云端存储。阿里厂内有成熟的存储方案,即阿里云的对象存储(Object Storage Service,简称 OSS)服务,它类似于亚马逊的 S3,特别适合海量数据存储,且存储容量和处理能力均已实现自由伸缩。
整体架构
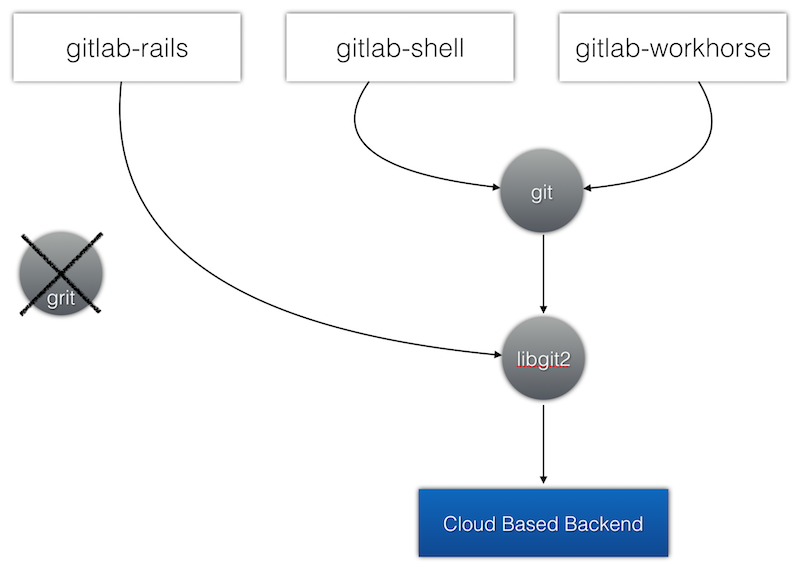
GitLab 中存在的 libgit2、git、grit 这三种访问 git 的方式实在是太多了,势必会对后期改造带来麻烦。因此,为了简化问题,我们先想方设法去掉 grit 这个组件。grit 主要用在 GitLab 的 wiki 功能上,被 gollum-lib 和 gollum-grit_adapter 两个 gem 使用。所幸,gollum 使用了适配器设计模式,可以直接撤掉 gollum-grit_adapter 而改用 gollum-rugged_adapter,而 rugged 是调用 libgit2 的。通过这种手法,系统就只剩下了 libgit2 和 git 这两种访问 git 的渠道。
libgit2 和 git 命令的应用场景都非常广泛,难以进一步简化。例如 libgit2 被上层 rugged 和 gitlab_git 这两个 gem 包封装后备用在 rails 的 MVC 的各个角落之中。而 git 命令则被 gitlab-shell 和 gitlab-workhorse 广泛使用,好多操作——诸如上传下载代码、生成压缩包、合并 MR 等——都是通过直接调用 git 命令来完成的。
我们观察到 libgit2 在设计上有一个非常有用的特性,亦即 git 对象的后端存储层 backend 被抽象出来,做成了可插拔的。例如官方提供的代码中,默认的 backend 是基于文件系统的,但也有将 FS 的 backend 换掉的例子,从而将 libgit2 的后端存储嫁接在 MySQL 以及 Redis 等其他数据源上。我们打算利用这个特性,为 libgit2 开发一个新的 backend,亦即一个基于阿里 OSS 的 backend,从而将 libgit2 的后端存储嫁接在 OSS 上。
然而,git 的后端存储确是写死在 FS 上了,如若替换则会引入代码的大改。但万幸的是,git 的开发思想非常 UNIX 化:git 包含 140 多个子命令,这些子命令之间互相调用,每个子命令做到了功能单一、简单。我们只需巧妙挑选其中的动刀点,在 libgit2 的新后端上重新实现某些子命令,甚至是某些子命令的某些参数,即可实现 git 的 libgit2 嫁接,工作量并不大。
libgit2 嫁接 OSS
libgit2 可插拔的后端分两部分:一是 refdb,用来存储分支名、tag 名等 git 指针;二是 odb,用来存储 tree、commit、blob 等 git 值对象。refdb 只能有一个,而 odb 可以有多个,且可设置优先级。我们新设计的后端包含了 OSS 存储的 refdb,以及包含了两个 odb:一是散装 OSS 存储,二是大包 OSS 存储。散装 OSS 存储优先级低,大包 OSS 存储优先级高。
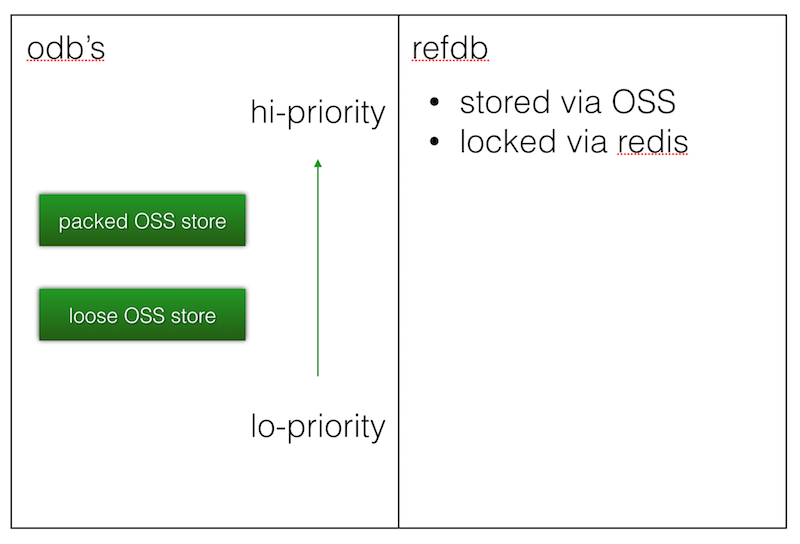
散装 OSS 存储和 refdb OSS 存储的原理一样,就是将原本作用在文件系统路径上的读写操作转到 OSS 上,读文件变成一个 HTTP 的 GET 请求,写文件变成一个 HTTP 的 PUT 请求。但如果只有这么简单的设计,系统的速度必然变得很慢,git clone 的性能将退化到 svn 一般,这是完全不可接受的。
因此,我们设计了更复杂的大包 OSS 存储。大包 OSS 存储的写的部分主要用在接收用户上传来的代码的场景。当用户传上来的代码的 pack 太大,不适合直接解压缩进行散装存储时,我们便直接调用 git-index-pack 命令为用户传来的 pack 计算索引,将 .idx(索引文件)和 .pack(用户传来的包)这两个文件直接存储到 OSS 上。
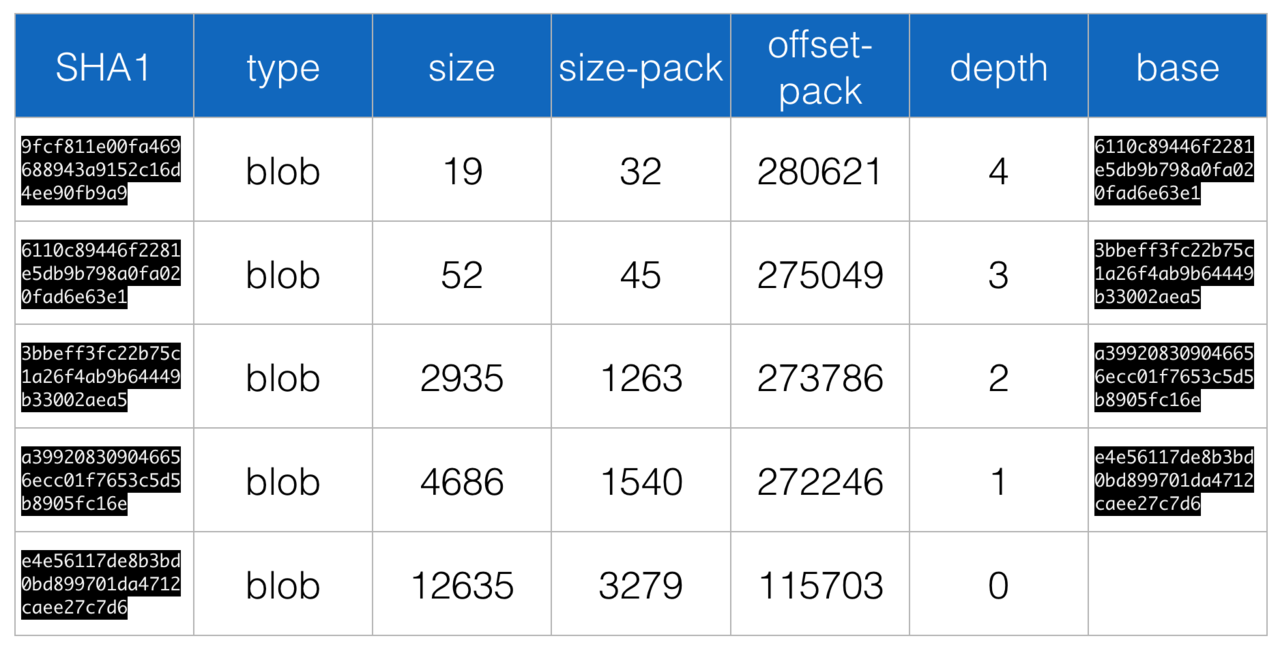
但读的时候,总不能把整个包下载下来。因此我们利用 OSS 的断点续传功能——亦即通过 HTTP 协议的 Range 头——巧妙地编写了大包 OSS 存储的读取逻辑,一个典型读取场景发生时产生的 HTTP 请求如图所示。
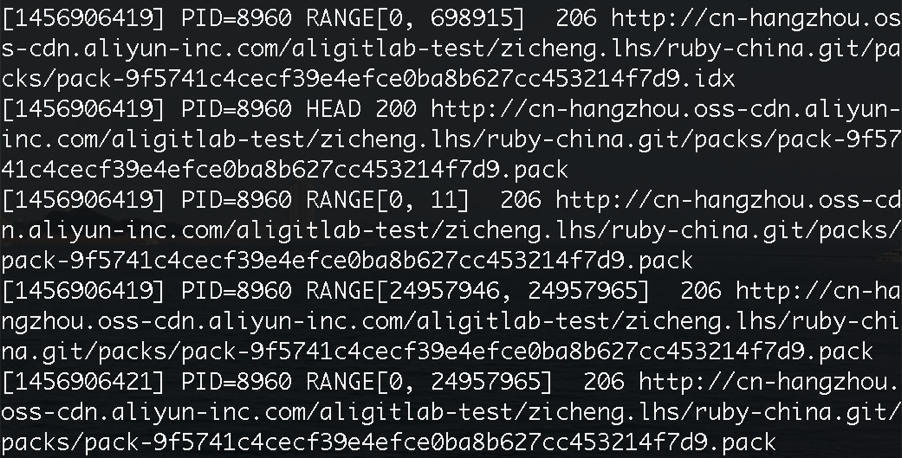
每当读一个文件,我们会先取下大包的索引文件 idx,从中计算出 pack 文件中目标对象的偏移量,然后通过 Range 请求取出需要的部分,成功后服务器返回 206 Partial Content。这时,取出的需要的部分可能因压缩,只是一个 Delta 片段,因此需要继续重复上述步骤直到找到 Delta 的 Base Root 并最终解压缩出来,Delta 到 Base Root 的链长一般不超过 10,且由于 git 在产生 pack 时的优良启发式算法,Delta 在 pack 中的偏移量与它的 Base 链距离不会太远,因此我们每次发出 Range 请求的时候会故意把 Range 的区间取大一些,这样能有效节省 Range 请求的数量,目前该窗口值我们取为 16 MB,这纯粹是一个经验值,可随观察结果进一步调整。
通过一个具体例子来解释,假设我们要取的 git 对象的 SHA-1 值为 9fcf811e00fa469688943a9152c16d4ee90fb9a9,因为它的第一个字节是 0x9f,进入 idx 索引文件的扇出表 IDX[8 + (0x9f - 1) * 4] 到 IDX[8 + 0x9f * 4] 字节取出以该字节开头的对象的编号范围,之后到该范围指向的 SHA-1 清单列表中进行二分查找看 SHA-1 值是否存在,当判断到存在时,跳过 对象总数*(20+4) 的区域(这片区域主要是和校验等),去读取该对象在 pack 文件中的偏移量。Range 取出 pack 文件的该偏移量处的内容之后,读取该处内容的类型,若发现是 OFS_DELTA(0b110),则继续读取其 Base 的偏移量,为其所有 Base 重复上述步骤直到取到其 Base Root 为止,最后遍历的整个链条如表所示。但得益于 pack 文件的良好设计,我们实际只需要很少 HTTP Range 请求便可完成整个链条的读取,因为我们可以看到 offset-pack 是单调递减的,链条整个区间长度仅为 164 KB,这对于一次 Range 请求的 16 MB 窗口而言绰绰有余。
git 嫁接 libgit2
开发完 libgit2 的新后端之后,接下来便是对接 git。上面已经分析过,这一步无法绕过,但工作量不大,因为 git 的命令小而多,只要找到最佳的动刀环节即可。
首先是下载代码,亦即 git fetch / clone。服务器端首先被调用的是 git upload-pack --advertise-refs,来广告服务器上已有的资源,这个部分我们可利用 libgit2 简单重写。然后被调用的是普通的 git upload-pack,这一步处理的是大量的 git 自定的应用层协议,不易修改,我们保持不动。接下来 git upload-pack 又自身调用了 git pack-objects,用来将数据进行打包,这是一个仅涉及数据 I/O 的完美的动刀点,且 libgit2 提供了等价的 pack builder 功能,我们用 libgit2 将其重新实现。
其次是上传代码,亦即 git push。服务器端首先被调用的是 git receive-pack --advertise-refs,重写思路类似。处理通信协议的 git receive-pack 亦不进行修改。接下来要分情况,git 源代码中很重要的一句话就是对“ntohl(hdr.hdr_entries) >= unpack_limit”的判断。当用户传来的数据较少时,git 调用 unpack-objects 将传输包解开,此处用 libgit2 进行改造,加入写入 OSS 散装后端的逻辑;反之,当用户传来的数据较多,git 调用 index-pack 直接为传输包生成索引,此处也用 libgit2 进行改造,加入写入 OSS 大包后端的逻辑。
跑分结果(无缓存裸跑分)
经过这些修改,性能变得如何呢?在把所有缓存关掉的情况下,我们得到了如下跑分结果,时间均为墙钟时间。
测试库:gitlab-ce,它包含 20 万个对象,打包后超过 100MB。
| 原版 | OSS 版 | |
|---|---|---|
| 全量 git push | 53.299s | 54.697s |
| 增量 git push | 3.059s | 2.845s |
| git clone | 47.096s | 1min14.12s |
| git fetch | 0.806s | 16.019s |
| GET /namespace/repo/tree/master | 74.5ms | 5877.7ms |
| GET /namespace/repo/tree/master/builds | 50.0ms | 4547.0ms |
缓存
我们看到,把 FS I/O 变成网络 I/O 后,系统不可避免得变慢了,所以必须在各层加入缓存。考虑到实际部署时集群内的每台机器上总有一定量的 FS 存储空间,我们打算将这一部分空间利用起来,做成 LRU 缓存,再加入两个 odb 后端层作为本地 FS 缓存层,使得整体呈现为汉堡包结构,我们称作“四合一无敌组合”。与此同时 refdb 也加入 redis 缓存逻辑,从而使较慢的 HTTP 请求仅发生在 redis 缓存被击穿的情况下,从而提升性能。
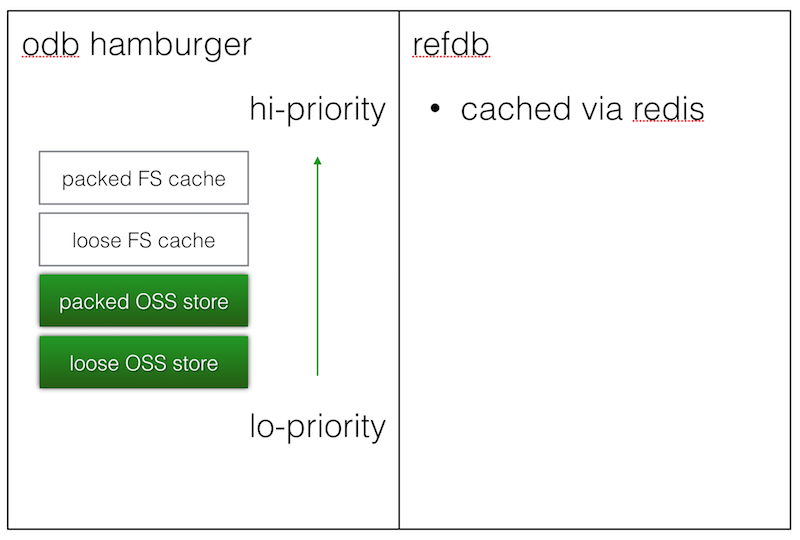
新增的两层的数据从何而来呢?对于散装本地存储,数据一是来自 ntohl(hdr.hdr_entries) < unpack_limit 时的 git-unpack-objects,二是来自散装 OSS 的读接口。当发生这两个场景的操作时,从 OSS 上取到的数据不再浪费,被缓存在 FS 上。对于大包本地存储,数据则也来自于两个场景,一是 ntohl(hdr.hdr_entries) >= unpack_limit 时的 git-index-pack,二是 git-pack-objects,原理类似。
后续工作
为了把成果回馈给开源社区,我们还有很多工作要做。例如:
- 开发基于 AWS S3 的 libgit2 后端,让大家可以在 Heroku 上跑 GitLab
- gitlab 项目:提交补丁减少对 git 命令的直接调用,改为基于 libgit2 的 rugged 库级调用
- gitlab 项目:提交补丁让用户选择后端存储,如可选将仓库存到 FS AWS S3
- gollum 项目:提交补丁让基于 libgit2 的 rugged 成为默认,不再使用 grit
- libgit2 项目:提交补丁提升性能,因为 pack builder 的实现跟 git 相比还很慢
