-
怎么把 Mac 里面这个地方的锁去掉 at 2014年12月12日
首先,登录用户是管理员的话,网络设置这里是没有锁的(见下面截图)。
其次,你的这个需求应该使用这个功能来实现:
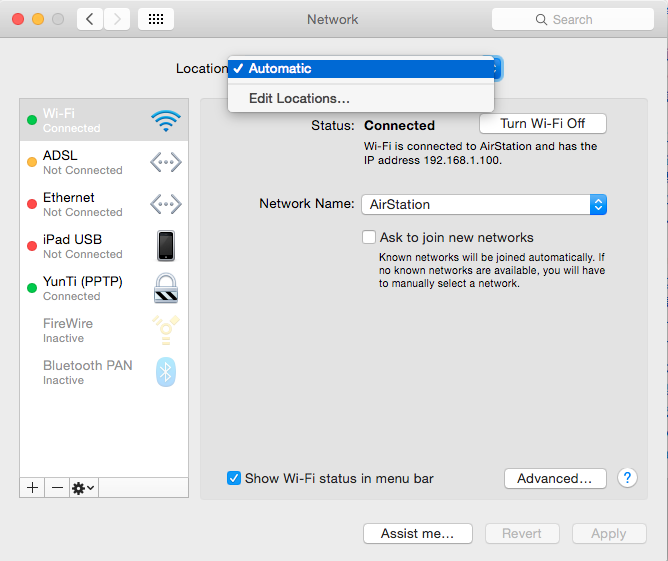
Location 允许你为不同的网络环境创建多种配置,一旦创建好,可以直接在顶部的 Apple 菜单迅速切换各种网络配置,而不是手动的一个一个去改。
-
出一个键盘,Mini Tctile Pro for Mac at 2014年12月06日
-
出一个键盘,Mini Tctile Pro for Mac at 2014年12月05日
-
作为开发者,你喜欢 markdown 还是所见即所得的编辑器 at 2014年11月29日
看楼上的众多评论,有了些(还不成熟的)想法:
- 无论是哪种编辑器最终的产出物都是 HTML(这决定了它的存在范围,如果是做其他用处比如印刷出版就没意义了,或者要加上更多需要考虑的要素了),从这个意义上来讲,是否有更好的编写 HTML 的方式?如果有,那么就消除了标签对应关系的烦恼,你唯一要学的就是 HTML 而已(这一点符合技术圈的广大受众,但不符合超出技术圈的),并且不是要很精通 HTML,因为目标是不需要考虑结构,全部是流水式的(除了个别复杂的排版需求,比如表格,嵌套式列表等)。
我是这样想的,其实 Markdown 能实现的,HTML 都可以做得更好。不能直接用 HTML 的原因可能很多,比如:
- 标签有特定格式,总是打
<>让人受不了——但是像 emmet 这样的工具可以解决此类问题; - 标签与内容会出现歧义,必须有方式来区别标签和标签的字面意义——Haml Jade 这类的工具都有类似的解决方法;
- 最麻烦的是,HTML 是结构化的文档,必须遵守一些嵌套的规则——这才是 Markdown 之流最大的意义,即破除结构化(其实也不完全,比如嵌套式列表还得靠缩进吧,当然嵌套式列表本身看起来就是缩进的,所以也还说得过去);
- 除了标签之外,更讨厌的是属性,谁记得住那么多。还好,文档写作几乎不需要什么属性来辅助,最最常用的无非就是超文本的内容,链接 图片 等等;我不知道有什么特别好的替代方案,Markdown 本身还可以吧,但需要学,它和 HTML 不一样。
- 等等我一下子没想到的问题
如果基于 Markdown 但是不需要改变标签(不用学新标签和 HTML 的对应关系),换言之 Markdown 有办法能识别所有的 HTML 标签且无需改动它们,可以支持像 emmet 那样快捷生成片段(不用全部功能,有一些很方便,比如嵌套式标签,而且这个都不太重要),加上 Markdown 本身无结构化的特性,内容的写作方面我觉得足够了。
wysiwyg 永远解决不了的问题就是你无法只用键盘完成所有的操作。你说快捷键?如果功能多了呢?如果和操作环境冲突呢?你不是还得要去记?再说快捷键不能解决所有问题,比如说插入一个链接,快捷键要么先让你处理 placeholder,要么先让你处理 link,可我有的时候就是忘了这个顺序导致不得不复制/粘贴好几次,总是无法一步到位。
还有 wysiwyg 对于结构的解释是依赖于编辑器本身的处理逻辑的,作者无法精确控制,有时候不得不用 hack 的方式来达到一些目的,这也是它的缺陷之一。总之 wysiwyg 是预先定义的规则下的写作,而不是自由写作,如果不考虑 HTML 自身的限制,它才是自由写作(当然,浏览器决定了 HTML 的规则,但这已经是极限,无法要求更多)。
- 在呈现上,也就是好看与否,因 HTML 的缘故,也就限定给 CSS 了。然而这一点几乎不受编辑者控制,特别是 markdown;wysiwyg 稍微好一些,但也不过是提供了预置的样式让你可以看得见,若是想自己完全控制那就要进入代码模式,也就等于 !wysiwyg 了。然而这一点没啥好的解决办法,你总不能再提供一个自定义 CSS 吧,那就不是写作而是页面开发了……如果做一个产品,做到两点就够了:
- 提供足够好的输出设计,就像 medium 那样,大部分人都满意就足够了;
- 在此基础上,提供自定义模板和预置模板,满足一部分人不折腾不舒服斯基的习惯就好了;
除此之外,夫复何求?
- 功能方面,其实第一点就已经决定了,不管是 Markdown 也好 asciidoc 也罢,又或者是预想中的新工具,全都是孙猴子,最终逃不过 HTML 的五指山。所以功能的上限已经是决定了的,无非就是实现一套描述这些功能的规则,其代价有多大而已。解决了第一点的问题,这个就迎刃而解——我都和 HTML 一比一无缝对接了,你还要啥自行车?
当然了,我们还有 JavaScript。但和 CSS 一样,这是不需要由作者掌控的范畴,可以用外挂的形式往上加,不过这是最后最后才需要去考虑的问题,锦上添花而已。
说到这,觉得自己说的都是废话,第一点里提到的不信别人没想过。大概 HTML 真的没法再简单了吧。
-
难以忍受 Yosemite 卡顿,看看抹盘重装看看如何 at 2014年11月28日
-
难以忍受 Yosemite 卡顿,看看抹盘重装看看如何 at 2014年11月28日
-
难以忍受 Yosemite 卡顿,看看抹盘重装看看如何 at 2014年11月28日
-
难以忍受 Yosemite 卡顿,看看抹盘重装看看如何 at 2014年11月27日
-
git 里 push request 注意事项 at 2014年11月20日
#5 楼 @hbin 嗯,你列举的两个例子很有典型性,很认同。不过我想补充一些个人的想法:
多人一起开发一个分支,是否是 feature 分支?因为多人一起去开发一个主干分支(比如 develop)在我看来是一件不可思议的事情,而通常针对上游的更新都是由主干分支去 tracking 的,所以在我常用的工作模式下,这个问题不存在。如果是 feature 分支,由于它长期处于不稳定状态中(直到 feature stable 为止),因此它不应该直接去 tracking upstream,也就不会有从 upstream rebase 这种操作出现了。一旦 feature 完成可以合并到主干,然后主干 rebase upstream;或者主干直接 rebase upstream 之后再 cherrypick feature(feature 预先 squash 或 merge 了)。因此你描述的状况究其根源还是 Git 模型不太合理。
无论是 merge 还是 rebase 亦或是 pull 的时候采用其中一种方式,都是可以指定冲突解决策略的,诚如你所说,rebase 在 reapply one by one 的每一步中其实都在做和 merge 一样的差异对比,和 merge 的区别就在于是一次性留到最后再解决还是一步一步去解决罢了。
然而在实际中,每一步的解决策略不一样是非常罕见的(也就是某一步要 ours,某一步要 theirs,某一步要各取一点这种),出现这种情况的,即使是 merge 的最终合并,也一样需要你耗费很大精力去逐行处理。
绝大部分情况下,我们对于每一步的处理决策都是一致的,而且通常都是要 ours(因为如果全都是 theirs 那索性 rollback 得了),于是你可以在执行 rebase 的时候就指明解决冲突的策略,比如这样:
$ git rebase -s recursive -X ours如此一来,Git 会自动递归的处理每一步的冲突,并且以“我方”的版本优先。于是你的问题也就不是问题了。
当然,绝大部分的情况并不能覆盖所有的可能,我在工作中也遇见过令人头疼的特例,但是 一)特例不应该影响我使用更好的选择,不能因噎废食,往往面对特例束手无策恰恰说明自己不够了解,还有成长的空间;二)就 rebase 这件事情来说,冲突解决策略非常多样化,我提到的 ours theirs 只是其中两种而已,有心人不妨通读一下 man pages 一定会收获更多。
总之我自己遵循的一个原则就是能不用 merge 就不用 merge,遇到棘手的情况就花时间找找更好的办法——不过我也觉得自己是有点偏执的,因此只作陈述,不作推荐。
-
git 里 push request 注意事项 at 2014年11月19日
#1 楼 @hbin 事实上 rebase 比 merge 更好(同步上游的例子)。
当然可以直接使用 rebase 策略来 pull:
$ git pull --rebase upstream这样可以省去 update 或 fetch 的步骤,不过若你要先预览对比再考虑 rebase(或 merge),那就还是分两步来做。
一般来说,一个人干活的项目无所谓,merge 也无妨,历史记录会难看点,但是只有你一个人总还是看得明白。而多人项目大家都用 merge 的时候,你看历史记录的时间线只会觉得头疼,rebase 会达到 merge 一样的目的,但是历史记录就好看多了。
当然,merge 的好处(without fast forward)是可以把一串历史记录合并成一个,这样你可以选择单分支浏览历史记录倒也不会嫌乱。不过 rebase 的意义在于如果一开始就坚持使用,那就根本不存在“视觉筛选”的难题,而且对于琐碎的提交记录,rebase 也可以做 squash 等等更细粒度的操作(前提是大家都有这个意识和习惯),怎么也比 merge 优雅的多。
不过 rebase 是有门槛的,相对 merge 而言,理解 rebase 的工作方式会更复杂,需要的操作也会比 merge 多一些。rebase 有搞乱历史记录的风险。rebase 不适用于 pull request(但是很适合同步上游库)。等等。
选择 merge 或 rebase 取决于团队的版本管理策略,以 pull request + review 为主的模式,merge 是合适的,特别是从 feature 合并到主干的过程,(不过单个 feature 自己的控制以 rebase 为主会很好)。
以中心式仓库为主的模式,rebase 显然是更好的选择——只要掌握它不会是障碍。
两者都是工具,根据情况选择合适的就是了。
-
求教跨域访问策略在 development 模式下和 production 模式下的区别? at 2014年11月15日
#14 楼 @darkbaby123 没折腾出原因来?后来是不是索性 CORS 去了?
-
求教跨域访问策略在 development 模式下和 production 模式下的区别? at 2014年11月15日
-
求教跨域访问策略在 development 模式下和 production 模式下的区别? at 2014年11月15日
-
求教跨域访问策略在 development 模式下和 production 模式下的区别? at 2014年11月15日
-
求教跨域访问策略在 development 模式下和 production 模式下的区别? at 2014年11月15日
-
求教跨域访问策略在 development 模式下和 production 模式下的区别? at 2014年11月15日
-
在 rails 中,自定义的 exception,放在哪比较好呢 at 2014年11月13日
异常类?
lib下吧。 -
这个是内存泄露么?两个页面,占用 2G 内存 at 2014年11月13日
-
大家都来贴下自己的 Ruby 开发环境吧:) at 2014年11月13日
#15 楼 @cassiuschen 目前没啥特别的好处(对纯粹使用者来说),对于插件开发者来说,Neovim 的插件机制和 Vim 很不一样,具体可以看看 Github 上的 wiki,我自己是有时间就玩玩 VimL 了。
不管怎么说,Neovim 是一群老 Vimer 做的改善,它不会改变你对 Vim 的操作习惯,但在各种可能改善的地方都做了改善(或者计划做改善)。目前的版本还是早期测试中,一般使用者不装也无所谓,装了呢大部分插件都无痛兼容,我唯一遇到有问题的是 UltiSnips,不过解决起来也很简单就是了。
-
大家都来贴下自己的 Ruby 开发环境吧:) at 2014年11月13日
mac + zsh + neovim - 刚换的
-
[译] 为什么我们开发的 Raptor 比 Unicorn 快 4 倍,比 Puma,Torquebox 快 2 倍 at 2014年11月13日
楼主的遣词造句可以看出下了一番功夫,并非无脑直译。不过有些句子翻译的有点过了,不但生硬了加了一些原文中没有的意义,而且还造成读者的困惑。
原文第一段最后一句:
Unicorn, Puma and Torquebox are already pretty fast, so beating them hasn’t been easy and has taken a lot of work.
你的翻译版本:
Unicorn,Puma 以及 Torquebox 已经非常快了,所以仅仅是打败它们就已经不是一件容易的事情,单就超越就已经需要花费大量的工作。
我尝试重新组织一下:
Unicorn,Puma 以及 Torquebox 已经非常快了,因此打败它们实属不易且颇费功夫。
还请琢磨琢磨,“单就超越”这句话从何说起?
在此声明,并非吹毛求疵鸡蛋里挑骨,只是翻译的确很辛苦,作为译者也不愿读者看了自己的译文还是颇多困惑而不得不求问于源,这样一来岂不是自己费了功夫,别人还得再费一遍不是?所以我只是想说既然选择了去翻译,那么准确——也就是“信达雅”的“信”是必须的。不仅仅是要把该翻的翻到,还得避免添加本没有的含义,这是为了避免歧义。
不过话说从头,翻译这么一大篇实属不易,一百个赞先给楼主。
-
这个是内存泄露么?两个页面,占用 2G 内存 at 2014年11月13日
打开 Chrome 的任务管理器,先确认一下所有的 tabs plugins 等等,看看是哪个异常。
-
为什么说 Raptor 比 Unicorn 快 4 倍,比 Puma 快 2 倍 at 2014年11月11日
#12 楼 @meeasyhappy 真实的链接我也不知道,人都说了 25 号才公布,这会儿估计还是一个 Private Repo 呢。只不过你说的那个我太了解了,肯定不是一个 Web Server,它是 Gary 大神捣鼓的一个玩具,是一个 MVC 框架。
-
为什么说 Raptor 比 Unicorn 快 4 倍,比 Puma 快 2 倍 at 2014年11月11日
#4 楼 @meeasyhappy 还真不是它,你搞错了。
-
如何用 JS 检测一张图片是否被正确加载了呢? at 2014年11月10日
因为你监听的是
window的load而不是img的,这样改:$('#bdimg').on('load', function () { // ... });另外,你那个
complete属性是什么?HTML 里没有这个属性。 -
新鲜信息的获取渠道 at 2014年11月03日
邮件订阅,每周系列,比如 Weekly Ruby,Weekly JavaScript,Weekly Node……等等,我发现只要你能说得出来,就一定会有 Weekly 系列等着你订阅。具体的地址网上搜索一下就可以了,但要注意不要订阅太多,这些邮件列表提供的信息量是很大的,订太多了看不过来都浪费掉,前一段时间我刚退订了一大批,就这样每天还会收到 10+ 这样的邮件,取舍很难啊。
Youtube 频道,某些频道频繁更新,特别是一些会议的,一般来说第一手信息,特别是新东西都会在各种会议,Meetups 等活动中最新与大家见面。可以先从 Confreaks 开始。
Twitter 我放弃了,娱乐性过大,有时候觉得纯粹浪费时间。 Github 如果不是和你的日常工作(私有的或开源项目)相关联,follow 什么的也没啥太大意义,个人觉得。 SO 把自己关注的几个子站订阅了每周邮件就可以了,太多了也看不过来,SO 的意义更在于遇到问题时有地方集中查找。
-
关于 rspec 中 its 的功能的疑问 at 2014年11月02日
语法糖,新版本里应该没有了,检查一下你用的版本。
顺便一提,这种语法已经被废弃了,你看的教程应该是落伍了。
-
纯 JS 的 Web 解决方案 MEEN at 2014年10月30日
#6 楼 @darkbaby123 嗯,顺着你的例子说一点。之前还有一个痛点,那就是组件化的过程。像 Angular/Ember 这样的东西提供了很多机制帮助我们封装可重用的组件,问题是封装完了之后如何分发?如何管理?如何升级?
虽然 npm 包括 bower 等在内都可以在一定程度上解决这个问题,但归根结底它们都是通用化的平台,在很多具体的开发中它们并不能彻底帮助开发者消除痛苦。比如说你使用 Angular 封装一个插件,你通过 npm/bower 去分发它,别人或许找到或许没找到,找到的或许知道如何下载如何使用也或许完全没有概念,如果他们有能力改善它但由于组件化本身缺乏标准,每个人都有自己的一套,所以也不见得很容易……等等等等,总之问题多多。
Ember CLI 定义了一套 Addon 的规范和机制,你可以很轻松的开发出可重用的各种组件——不仅仅是插件,任何组件都可以,甚至包括命令行的命令扩展都没有问题。所有的这些组件都遵循统一的代码结构,统一的文件组织,统一的分发与管理机制,统一的使用方式。对于其他人来说,重用组件几乎就是一个没有代价的事情。当 Ember 的整个生态圈大到一定规模的时候,你就能体会到今天定义一套统一的 Addon 机制是多么有远见的事情!
-
纯 JS 的 Web 解决方案 MEEN at 2014年10月29日
#3 楼 @serco 只谈前后分离,这是一种架构上的选择,Ember 是最好的选择?那要看情况,具体什么情况很难三言两语讲清楚。就好像 Angular vs Ember,我也喜欢后者更多,但是我不一定会每次都选择 Ember。具体的因素可能会有很多,比如“重量级”会是其中之一。
这个问题应该这样总结:
我选择前后分离,是出于架构上的选择,而不是出于我要使用 Ember 或其他的框架。出于架构选择即意味着我将受益于前后分离给我带来的好处:比如说项目管理上的透明性/灵活性;比如说实现一套 API 可以适用于多个客户端;比如说平衡 C/S 两端的负载等等……但绝不是因为我要使用 Ember 或其他的什么。
因此,如果选择前后分离,和 Ember 是否为最佳方案,这两者是没有必然的因果关系的。
举例来说,我要搞一个个人网站,类似博客。我决定采用前后分离是出于可能的两个原因(这里是举例):一、我有一个小伙伴帮我写 Backend API,他完全不懂前端,我也搞不明白他用的后端技术,所以我们决定在项目结构上让前后完全解耦,互不干涉;二、除了 Web 端,我还想在移动端的几个平台上尝试一下,所以一套 API 满足我几个应用端的需求是一个很好地选择。
然而,尽管我喜欢 Ember,但是 Web 这边一定要用它吗?未必。首先,一个博客类的 Web 应用没有必要非得 SPA;其次,对于这种类型的应用 Ember 明显太重了,值得吗?我很怀疑。
关于 Ember CLI,我觉得你不够了解它,如果它只是像 Yeoman 那样梳理出一套自动构建体系我就不会过多提它了。Yeoman 选择了 Grunt,Ember CLI 则用了 Broccoli(技术上说,Grunt/Gulp 是 Task Runner 而 Broccoli 是 Build Tool,它们是有区别的。好比 Ruby 世界里 Rake 和 Assets Pipeline 的区别),但是若仅仅如此也没有必要说 Yeoman 太小儿科了。我觉得你还是好好地研究一下 Ember CLI 再说吧,至少通读一遍官网的文档(目前还不算多,正在不断补充)再下定论,总而言之并非你现在说的那么简单。
React,如果只说一件事情关于它的优势,那就捡 Virtual DOM 来说吧。简单地说,无论 DOM 的变化多么复杂,React 的机制是把所有繁复的操作“封装”在一个看起来很像真实 DOM 的 Virtual DOM 里(当然,给你提供的 API 还是很简单的,所以实际写代码也很简单),当产生变化的时候,React 使用类似于 Git 的 diff 算法来比较前后的差异,于是可以很高效的只更新变化的部分,最后一次性的把 Virtual DOM 替换成真正的 DOM。我们都知道最影响性能的就是操作 DOM,React 则把操作 DOM 这件事情进化成理论上的最优方案,所以才可以在性能上产生令人惊叹的结果。这一点是目前的 Angular 也好,Ember 也罢,任何一个涉及到操作 DOM 的 JS 工具都无法媲美的。
但是这不是 React 的全部,鉴于我自己也还在学习于摸索阶段就不继续献丑了。
WebComponent 是一种若干先进技术和概念性技术的结合产物,无论是 Angular 的 Directive,还是 Ember 的 Component,甚至是 React 自己,或多或少都是在某种程度上对于 WebComponent 的一种实现。它解决的不是一个问题(比如说 View 层),而是许许多多问题的综合解决方案。比如说高度可定制化的自定义标签;对于复杂结构的良好封装(基于 Shadow DOM)从而实现非常灵活的可重用性;具备分离作用域的样式封装(想想 Sass/Less/Stylus……主要做的事情);提供具备完整生命周期和交互接口的脚本封装;灵活的模板系统,原生支持的模板导入。
可以设想若是 WebComponent 实现良好,浏览器支持也完备,那么我们可以丢弃很多现存的第三方解决方案,比如说支持数据绑定的模板系统;比如说 CSS 的预处理器等等。我们也可以获得很多更先进更方便的模块化组件,它们可以纯视觉化的设计和实现,它们可以拿来就用,直接提供各种对外的编程接口(相比通过 DOM 编程实在是繁琐 + 低效),也可以在不用考虑耦合/继承等带来的副作用的前提下去修改结构、样式、行为。对于高度模块化和可重用化的 web 开发提供了浏览器级别的原生支持。
太多的东西很难用语言去描述它的优点和前景,我建议你还是多多 Google 一下看看一些完整的资料和例子,比如说 Youtube 上 Google Developer 频道有很多关于 WebComponent 的视频,好好看看。
