-
“渲染 xml 和 json 数据” 不太懂 at October 10, 2012
-
“渲染 xml 和 json 数据” 不太懂 at October 09, 2012
XML 和 JSON 应该都算是一种以文本方式保存的数据结构。
其实 HTML 也是文本方式的数据结构,它和 XML 的共同点就是都用成对的标签来扩住数据主体(字符串、数字等等)。不过 HTML 的结构并不严谨(但是作为开发者,严谨的写 HTML 标签是好习惯!),这是因为它的目的是用来友好显示数据的,浏览器足够聪明来判断 HTML 的标签结构,并且把它渲染为人类所习惯的显示方式。另外:HTML 是 XML 的子集,这一点值得注意。
如果说 HTML 是用来给人看的,那么 XML 就是用来给机器看的。因为 XML 对格式要求十分严格,所以计算机语言可以很准确的解析 XML 数据结构,并获取它需要的数据部分。
为什么要 XML?因为大量的数据直接写在源程序里既不好读也容易出错,当程序处理需要外来数据的时候,我们就可以把数据保存在像 XML 这样的文件内通过外部加载,个人觉得这其实有点“数据封装”的意思。
JSON 呢?JSON 其实就是 JavaScript 的对象,因为它简洁优秀的数据结构表达形式,使得它逐渐成为程序员首选的数据结构封装格式;并且由于它对 JavaScript 的天然友好性,它更适合于在 web app 里作为数据结构的外部封装。
前面说得太抽象了。举个例子,你做了一个 web app,然后你封装了一些 API 允许把这个 app 里产生的数据暴露出去,这样其他的网站或者手机应用就可以通过你的 API 获得你网站里的数据,其他开发者就可以引用这些数据重新渲染显示在他们自己的网站或者手机应用中。
问题是,你的数据用什么形式发给他们?直接给 HTML 文件?这显然不靠谱。因为:1) HTML 的标签是不严谨的(至少可以写的不严谨,比如缺少关闭标签,混乱的多层嵌套等等——这对浏览器不成问题,它们都很宽松,但是对于写程序的时候来解析数据就是大问题了);2) 如果直接把你的 HTML 结构发给他们,一旦对方想改一下这些数据在页面上的显示结构就会很麻烦了,对于使用你的 API 的人来说,他们只希望要数据本身,而不是封装数据的结构标签。
所以 XML 和 JSON 就是更好的选择,而且对于 web 相关的应用来说,JSON 更胜一筹;而对于其他的一些应用平台,比如 RSS,那么 XML 可能就足够合适了。
因此,Rails 的
respond_to方法允许我们同时渲染多种格式出去,这为我们对外暴露数据提供了很大的便利——你不用自己去写外部数据封装的方法了。像你上面的例子,对于@user这个对象里包含的所有属性,当你通过浏览器访问.html后缀,看到的就是网页(实际中不需要后缀,这是因为router定义了获取数据的 URL,如http://myapp.com/users);访问.json即可以获得 JSON 格式的相同数据,XML 亦然。最后请看看来自 Github 的范例:
https://github.com/nightire https://github.com/nightire.json
Plus,推荐 LZ 看一个视频教程,来自 PeepCode 的: https://peepcode.com/products/play-by-play-tenderlove-ruby-on-rails
在这部视频里,Aaron Patterson 演示了一个小型 Rails 应用的开发过程,这个应用要求获取指定用户在 Github 上的活动详情,并对不同的活动计分,最终统计出这个用户的总得分。你可以看到 Aaron 是如何利用 Github 提供给我们的 JSON 数据的,包括如何获取,如何解析,如何分解数据然后保存在数据库对应的表中等等等等,相信会让你豁然开朗。
-
望有经验的 Rails 程序员总结一下 Rails 开发流程 at October 09, 2012
#14 楼 @alijan 首先,不用客气,大家都是一路摸索,有些心得体会相互交流也是应该的。
关于你说的第六点,这个恐怕就是“大概”说一下也能写出一本书来,呵呵,我自认还没那个能力,也还在学习摸索之中。所有的知识,目前我获得的,无非就是通过几个途径:搜索、教材(书、互动教材)、视频、读源码。诚然如你所说,一时得来的结果未必适合新手看,但需知从新手到高手都必须要有个过程,在这个过程里没有捷径可走。
如果我们请一个高手“大略”说说这些复杂,那么即使他说完了,新手看不懂的地方还是看不懂;除非他更加深入浅出的说——那就真的是长篇大论了,会涉及到 N 多书籍、教程、视频、搜索的结果。那么这样就真的好吗?我觉得不是的。因为每一个人的基础起点不一样,对事物理解的方法和顺序也不一样,直接喂到嘴里的饭未必会觉得好吃。
一时看不懂是没有关系的,记下来(不是死记硬背,而是留心知识点之间的关联)先,慢慢去理解。另外,在这个过程中,保持旺盛的好奇心是至关重要的。
拿我自己来说吧。最开始我被 Rails 所吸引是因为神奇的 ActiveRecord,有人告诉我说你用 Rails 去写 web app,可以完全不用考虑 SQL。这句话真的 hit 我了,因为作为一个编程菜鸟,曾几何时我也特别渴望自己写一个 web app,但是艰涩的 SQL 总是让我望而却步(当然,也是因为懒,下不了那个决心去学会它 ^^)。在没有类似 ActiveRecord 的年代,应用程序每一次要从数据库里获取数据都要写又臭又长的 SQL,而且获取数据的逻辑越复杂、条件越繁多,SQL 语句的复杂性也就随之增加;更要命的是,完成同样的数据库请求,SQL 可能会有多种写法,它们之前会存在效率不同的问题,如果你不熟 SQL,你真的很难很好驾驭它。
我真的是因为这个原因才开始接触 Rails 和 Ruby 的,不久就被它们折服了~~~Rails 做了什么?ActiveRecord 所做的一件重要的事情,就是把一系列复杂的 SQL 查询封装起来,留给我们一些简单、容易理解、可以灵活组合搭配的接口供我们调用。于是,你真的可以完全不考虑 SQL 的问题,并且它还保留了让开发者继续写原生 SQL 语句的自由,这样你即使不信任 Rails 封装的一系列方法,也依然可以按照自己的方式来。
Rails 开发组以及社区的活跃份子们通过大量的努力积累了一系列的最佳实践,并把它们扩充进 Rails 丰富的 API 之中,使得 Rails 日益完善,能够应对现实开发需求中各种各样对于数据查询的要求。它是简单,但是简单背后也有复杂的一面。我在开始学习的时候总觉得有些数据查询似乎用 ActiveRecord 也是满足不了的,然而无一例外的在过一段时间之后我就会在书里、视频里、或者搜索的时候发现:哦,原来 Rails 是可以的,只是我还不知道!所以,你需要什么?你需要不停地探索、挖掘、积累。
更有意思的是,因为学习 Rails 让我充满了好奇,我慢慢地也学会了很多 SQL 了。这是因为有的时候当我觉得 Rails 神奇的我无法理解的时候,我就会去看源代码,试着理解它背后的实现。当然,有的时候可以成功理解,有的时候嘛,道行还是不够啦。Anyway,至少每一次探险都能让我学到一些东西,于是日久天长,SQL 我也能熟门熟路了。所以当我看到或听到有些人说:“不要去学 Rails,它就像傻瓜照相机,虽然简单,但却会让你学不到真东西”的时候,我个人是不以为然的,因为能不能学到真东西完全取决于你怎么学,而不在于“老师”怎么教——当然,像 Rails 这么优秀的“老师”还是值得尊敬的,因为它凝聚了 Ruby 的优雅和众多开发者的集体智慧。
就象这样,Rails 表象的简单和它背后隐藏的复杂相辅相成,简单是为了好用,快速应对现实开发的种种需求变化,但开发者应当以这种简单为起点而不是终点,否则就会变成“知其然不知其所以然”,当然就不会创造出伟大的产品啦!
这是一个关于 ActiveRecord,也就是 Model 部分的例子。还有一个让我体会很深的是关于 RESTful,我想所有的初学者在读入门教材的时候都会看到作者有介绍 RESTful,并且都会推荐进阶阅读,那么大家是否真的去看了呢?你对 RESTful 了解有多少?CRUD 为什么会成为“惯例”?HTTP Methods 究竟如何发挥作用?这些问题你好奇过吗?探索过吗?
以前我就没有,因为“面向资源的架构”神马的,这样的词我一看就头大,我一直觉得这是架构师级别的大侠们研究的领域,我不觉得像我这样木有计算机专业背景,只当了不到一年的前端页面工程师能够驾驭这种重量级的话题。但是 Rails 再次改变了这一切,当我学了一段时间 Rails 觉得有点恶心,停滞不前的时候,我遵循了那些教材里的建议,去读了几本书,其中《RESTful Web Services》这本真的是让我有醍醐灌顶的感觉。可以这么说,在 10 楼的回复里,讲解范例的那一段,若不是因为我读了这本书,我想我是不可能解释到这个程度的。而上述的一切,若非是 Rails 领我进门,我想我也是不可能会去学习和理解的。
总得来说,我个人觉得 Rails 是很适合初学者——特别是没有什么计算机背景和开发经验的初学者——学习的 Web 开发框架。我这么说并不是因为它很简单,可以让你 3 个月速成写出一个 Github 来:这是不怎么现实的;我这么认为,是因为以下几个原因:
Rails 是用 Ruby 开发的。Ruby 是一门非常非常适合入门的语言,并且它也是一门非常非常强大的能用一辈子的好语言。它的好在我看来最重要的一点就是优美的表达能力!特别是对于像我这样只有 HTML+CSS 经验的初学者来讲,这一点非常重要,学习 Ruby 第一次让我有了我不只是在写代码,我更是在表达和交流的感觉(我是文科生,接近于自然语言的表达方式更能让我产生共鸣和理解)。在此之前,我曾试图学习 Java / C++ / PHP,PHP 算是最简单的了,但我学得都痛苦无比,唯独 Ruby 让我倍感亲切和自然。
正如 Aaron Patterson 在 RailsConf 2011 发表的演讲中所说,Rails 是一个开发框架,但它不只是一个开发框架,它以及社区选择和它一起工作的所有工具共同组成了一个美妙的 eco-system(生态系统)。如果不是因为 Rails,我不可能会去学 CLi;如果不是因为 Rails,我不可能会去学 Git;如果不是因为 Rails,我不可能会去学 TDD……你可以说学 Rails 是一个大坑,我要说那得看你的追求如何,因为无论你是否选择 Rails 或是 Ruby,只要你想要做出优秀,甚至是卓越的应用程序,这些坑你是必须要填满的,sooner, or later.而 Rails,这是引导并伴随我们走过这一路的最佳伙伴——也许不是唯一,但至少很适合我——每当你迷茫不知前路何处的时候,去看看那些 coder 用 Rails(或者 Ruby)做了什么,你总能学到些什么。
我无法告诉你未来,或许几年以后 Rails 都不是我的第一选择了,因为我也时常听到看到别人说它的缺陷:并发处理、可扩展性、安全性、性能瓶颈……等等等等,我还没到这个地步,我往往都听不懂他们在说什么?不过这不是问题,朝好的方向想想,我对自己说:若不是来学习 Rails,你甚至都不会有机会去了解这些!总有一天,当你了解了复杂事物的方方面面,相信你一定会做出最佳的判断和选择。
Keep moving on...with Ruby & Rails.
-
望有经验的 Rails 程序员总结一下 Rails 开发流程 at October 06, 2012
我也是新手一枚,可能比楼主接触的早一些,多一些,且谈谈我的一点体会吧。
事实上,我觉得楼主你现在面临的问题并不是具体的技术细节,因为常规的功能在过了一遍 Rails Tutorial 之后应该就都学会了,无非就是自己动手的时候想不起来。不过这也简单,多看看范例和 API 就好。
对于初学者而言,最麻烦的就是不知道该如何下手,这个楼主也提到了。我觉得原因不在于具体的技术,而在于对整个产品开发过程的了解还不够。换言之就是对全局的把握和掌控,我想这个需要长时间和大范围的涉猎积累才能有所进步。大多数的 coder 都会写具体的功能,但是却不会从宏观的角度规划一个产品的 roadmap,在常规的开发团队里,这通常都是项目经理或是产品经理的工作,而工程师只需要看着需求文档一个功能一个功能,一个模块一个模块的实现下去就好了,因此就不会觉得迷茫。
问题就是,对于绝大多数个人开发者,并没有参与全局开发的经验,更不要说全局性的设计一个产品了,所以具体的某个技术好学,但总是缺一条线把这些技术连接起来。所以呢,我的建议是在领略过 Rails 的概貌之后(比如说过了一遍 Rails Tutorial),先去了解一下一个完整的 web 产品的组成,梳理出一个线路图出来,就容易找到方向了。
这个事情并不是想象中那么复杂,我们完全可以参照一些成熟的产品架构来学习。举个例子吧,比如说你要开发一个论坛类的产品,那么你首先要为这个产品定义一下大体的功能。我们不谈那些独创的特色功能,就从复制一个典型的论坛说起,都需要什么呢?(这个要靠你自己想,如果你想不出来,就多去看看别的论坛,分析它们拥有哪些功能,功能之间是如何交互和组织的等等。)
这个时候,你要学会自言自语,对着自己说:“假设当我第一次访问这个论坛的时候,我首先看到的是一个欢迎页面。这个页面是否会有动态的内容暂时我还不确定(比如说从论坛的所有板块里提取出的热点话题等等),所以我先当它是个几乎静态的吧。”
此时,你会面临一个选择:我是要生成什么?scaffold? model? controller?
Rails Tutorial 里实际上给出了答案,就是在最开始解释 MVC 模型的时候。
对于一次不需要和数据库交互的用户请求,MVC 的处理过程是:用户请求(浏览器:发出请求)-> 路由(router:将请求映射至控制器的行为,也就是 action)-> 控制器(controller:对应的 action 处理相应的请求,处理后交给视图渲染)-> 视图(view:渲染完成交还给控制器)-> 控制器(controller:将结果返回给浏览器)-> 输出(浏览器接到发出请求后的响应)
可以看到,这个过程里没有 model 的参与,这是因为我们假设的目标是一个静态的页面,是不需要和数据库模型交互的。这个过程实际上就是 Rails Tutorial 里前五章的内容。
于是,答案就是生成一个 controller 就够了。scaffold 生成的是一个完整的 RESTful 资源,包括了 model, controller, views, assets, test...显然超出了我们的预定计划(当然它也可以做到我们要做的,只不过有点资源浪费罢了),目前需要的不是一个完整的 resource。
此外,你还可以多想一步(可选,即使现在想不到,将来也可以手动添加):既然上述的流程说的是来自用户的一次请求,那么对于其他的请求呢?
刚才提到了,router 负责将用户请求映射至 action(在 controller 中),那么对于静态页面来讲,基本上就是你有多少个页面,就要有多少个 action,因为每一个页面都会用一个独立的 URL 来确定位置,也就是有一个独立的请求。
所以,假设我们的静态页面有:首页、关于、帮助、联系,于是我们就可以开始动手执行:
rails g controller static_pages home about help contact在这条命令里,static_pages 就是控制器的名字,意思是“静态页面”(这个不是强制的,我只是模仿 rails tutorial 里的做法,这样 LZ 你也比较熟悉。实际开发中我喜欢对静态页面控制器命名为 portals 或者 entrance,请随意),也就是“用来控制静态页面部分的控制器”。在这个控制器中,拥有四个 actions:home / about / help / contact,分别对应计划中的四个页面(当然可以用别的名字,只不过 routes.rb 里的配置要和它们一一对应,另外不要用 CRUD 的名称,因为它们是和 RESTful 资源对应的——这就是“惯例重于配置”的思想)
接下来,router 里面设置好如何将用户请求转至对应的 action:
root to: "static_pages#home" get '/about', to: "static_pages#about" match '/help', to: "static_pages#help", via: 'get' match '/contact', to: "static_pages#contact"这几句用语言表述下来就是:
对于来自网站的根路径(root)的 get 请求,如:
http://myapp.com/,转交给 static_pages 控制器的 home 行为(action)来处理对于来自网站的 about 路径的 get 请求,如:
http://myapp.com/about,转交给 static_pages 控制器的 about 行为(action)来处理以下雷同,第三个 match + via: ‘get’等同于第二个直接 get;第四个只有 match,代表对于来自该路径的所有类型的请求(get post put 等等);这里都是举例,实际情况实际处理。
OK,到了这一步,控制器已经可以通过 action 将处理的结果交给 views 渲染了。对于静态页面来讲,action 的内部几乎不需要写代码,rails 通过 action 的名字就可以找到对应的 views。比如说对于 about action,对应的视图就是
/app/views/static_pages/about.html.erb接下来,你在视图里写什么,浏览器就可以通过
http://myapp.com/about看到什么。再往后,搞定静态页面之后,你大概会先碰到注册、登陆、验证三部曲。那么这就需要用到 model 了,因为你需要在数据库里记录一个注册用户的信息啊,对不对?那么实现的思路其实和上面也没什么不同,无非就是在 MVC 的工作流程里多了 model 这个环节,同时 controller 要负责的逻辑处理也酌情增加,于是整体的复杂度有所提升罢了。
That's it! 总结一下就是:
- 要全面的了解一个 web 产品到底是怎么设计和定义的(功能?模块?内容?体验?)
- 要深入的领悟 web 的通信机制和 mvc 框架的工作机制
- 要学习对于各种解决具体问题的具体手段
- 多测试。尤其是当你不知道要做什么的时候,测试的意义就在于可以让你先把结果写出来,然后提示你距离达到这个结果你还有多远要走
- 多看文档、视频。比如说上面讲的 routes.rb 里 get / match 的区别和用法,一开始我看 rails tutorial 也是不明就里,于是就去看了官方的 guide,这才算是明白了。
- Rails 很简单,但前提是用他的人要有系统而扎实的基础知识。Rails 的简单是因为它及其聪慧且优雅的隐藏了一整套 web 应用框架背后的种种复杂,如果你要驾驭这种简单,你就要懂得背后的复杂——你可以不用学会写如何处理这些复杂,但你至少要知道这些复杂是什么,它们怎么工作的。
即兴写就,看着有点乱,还请各位海涵,希望对 LZ 有用。
-
求一个 `shell prompt` 配色方案. (抓图) at September 23, 2012
自用配色一枚
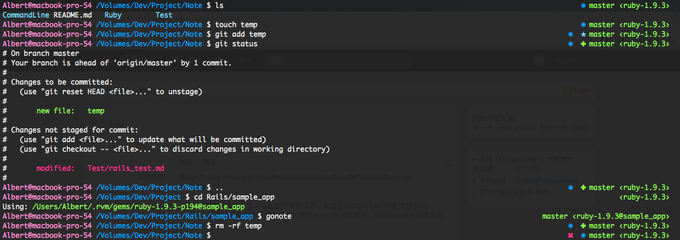 个人比较喜欢明亮的配色,左边显示常规信息,右边显示 Git 和 Ruby 环境,很直观。
个人比较喜欢明亮的配色,左边显示常规信息,右边显示 Git 和 Ruby 环境,很直观。 -
真实代码是如何于测试代码双向交互的? at September 09, 2012
Sorry guys...
看到 p57,我忽然就懂了:
为了让真实的代码能够正确运行,需要建立一个简单的运行脚本,如下:
#! /usr/bi/env ruby $LOAD_PATH.unshift File.expand_path('../../lib', __FILE__) require 'codebeaker' game = Codebreaker::Game.new(STDOUT) game.start事实证明,应用环境下传进去的不是什么
output对象,而是STDOUT啊啊啊啊啊! 对不起各位,占用大家宝贵时间了,俺实在是单纯,真的以为写output参数就是在找那个坑爹的output对象,竟然连 formal parameter 都忘了……我错了
-
昨天买了 codeschool 一个月的课程 at September 09, 2012
#9 楼 @cisolarix 有,比如 railstutorials.org,讲得很全面,很细致,不过它并没有 cc 那样的交互式练习,只有全套视频加免费的在线书(也有 PDF 和实体),所以你得在本地搭环境动手做。
-
真实代码是如何于测试代码双向交互的? at September 09, 2012
#1 楼 @lgn21st 是的是的,我忘了说是请了解这本书的高手帮我解答,不好意思。
书我只看到 70 页,内容不算多,所以这两天我已经反复读了三遍,依然摸不着头脑,干脆我把源码贴出来吧,我感觉我可能是卡在一个愚蠢的问题上了,但我就是找不到答案。
应用结构:
- codebreaker/ - features/ - step_definitions/ - game_steps.rb #1 - support/ -env.rb #2 - codebreaker_starts_game.feature - lib/ - codebreaker/ - game.rb #3 - codebreaker.rb - spec/ - codebreaker/ - game_spec.rb #4 - spec_helper.rb问题里提及的几个文件,分别用 #1 ~ #4 标注,下面依次是源码:
#1
game_steps.rb# 这里定义了用于输出信息的 Output 类 class Output def messages @messages ||= [] end def puts(message) messages << message end end # 这里实例化……问题是,真实代码如何知道 `output` 对象在这? def output @output ||= Output.new end # 以下是 Cucumber 的 Step Definitions Given ... do end When ... do # 难道是这里传给 Game,所以真实代码知道的? # 问题这是测试代码啊,应用真实运行的时候并不会调用测试代码,对吗? game = Codebreaker::Game.new(output) game.start end Then ... do |message| output.messages.should include message end#2
env.rb# 这里导入了应用程序的 PATH,所以 Cucumber 知道我们要处理的是 Ruby # 这里应该是单向的,对吧?也就是说**测试** 通过这里知道 **应用**,但**应用**并不因为这里而知道**测试**,我说的对吗? $LOAD_PATH << File.expand_path('../../../lib/', __FILE__) require 'codebreaker'#3
game.rbmodule Codebreaker class Game # 这里就是我的疑惑产生的地方: # Game 初始化的时候传递了 `output` 进来,它怎么知道 `output` 从哪里来的? # output 实例化的时候不是在 #1 的测试代码里面吗?这里又没有 `require`…… def initialize(output) @output = output end def start @output.puts 'Welcome to Codebreaker!' end end end#4
game_spec.rbrequire 'spec_helper' module Codebreaker describe Game do describe "#start" do it "sends a welcome message" do # 这里也不是非常理解,`double` 方法是“伪”了一个 output 对象,所以它不关心 output 从哪儿来,只要证明 output 对象有 puts 方法就好了,对吗? # 那么 既然 output 是“伪”的,RSpec 又何从知道它一定 should_receive(:puts) 呢? output = double('output') game = Game.new(output) output.should_receive(:puts).with('Welcome to Codebreaker!') game.start end it "prompts for the first guess" end end end所以总结一下我的疑惑就是: 已知:
output对象来自于测试代码 #1,它属于 Cucumber,Cucumber 通过 #2env.rb接触到真实代码 #3 那么:#1 以及 属于 RSpec 的 #4 又是怎么接触到存在于 Cucumber 中的output对象的?这是一种什么原理或机制? -
新发现的 ruby-china 的 bug at September 09, 2012
这的确是一个 BUG。
当用户激活帮助时,会插入一个
<div class="modal-backdrop fade in"></div>,而取消帮助的时候就会从 DOM 中删除这个节点。问题是fadeOut是有时间间隔的,如果在此间隔内立刻激活帮助的话,就会中断之前的fadeOut重新fadeIn进来一个新的<div class="modal-backdrop fade in"></div>。而且之前的fadeOut被中断了,旧的<div class="modal-backdrop fade in"></div>也没从 DOM 中删除掉,于是 BUG 就可以重现了。这个解决起来应该很简单,
fadeIn的时候,先检查有没有<div class="modal-backdrop fade in"></div>存在,如果有就不插入了,这样的话即使fadeOut被中断,也只会有一个<div class="modal-backdrop fade in"></div>存在于 DOM 之中。而且@Peter,RSpec 肯定应该是可以做出这样的测试的,前提是测试人员有前端的开发经验,知道这一 BUG 的重现条件即可。我初学 RSpec,不敢班门弄斧,不过 Jasmine 一定可以。
-
十万火急,快!!! at September 09, 2012
你给的提示太少了,初步的想法是如果 spawn 挂了,那么应该还有 ruby 回遡的全局日志,先查看一下日志里面有啥重要信息吧。
-
想问一下配置 alias 的问题 at September 09, 2012
是啊,放着进程管理干嘛不用呢
-
昨天买了 codeschool 一个月的课程 at September 08, 2012
每一门课都有 5 刀抵扣,下次付款会直接扣除,确定。 learning by doing 就是在线练习,没有说过什么实际案例啊。目前 cc 的课程都是基础课,所以你感觉基础知识多这并不奇怪。而且 cc 的风格是大纲式的,多数 exercise 的答案都不在 screencast 里,你需要动动脑子或者 google 一下,比较适合初学者。
-
请教一个关于 Agile Web Development with Rails 的问题 at March 24, 2012
我检查一下再吧,新手,不是很敢确定。。。
-
jQuery plugin: Elastic at March 24, 2012
精神可嘉! 不过这个问题全世界已经纠结好久了,基于兼容性的考虑,Shadow DIV 还是最好的处理办法。 当然,LZ 如果能另辟蹊径那是最好,大致看了一下源代码,hard code 有点多,重用性不太好啊⋯⋯
-
请教一个关于 Agile Web Development with Rails 的问题 at March 24, 2012
-
请教一个关于 Agile Web Development with Rails 的问题 at March 24, 2012
我是按照这本书的配置一步一步做下来的,ruby / rails 等的版本都和书中保持一致,并且其他的范例目前都很正常,没有出过任何问题。
我是新手,还没有学到 route 的部分,所以我很难说是否配置的正确。不过我想,按照书里做的,没道理错吧?(书都第四版了,要是有问题早都应该被指出了才对)
 个人比较喜欢明亮的配色,左边显示常规信息,右边显示 Git 和 Ruby 环境,很直观。
个人比较喜欢明亮的配色,左边显示常规信息,右边显示 Git 和 Ruby 环境,很直观。