-
为什么说绝大多数人都没搞懂区块链接,区块链的实质创新是什么 at 2018年02月11日
是不矛盾,我就是补充一下我觉得就连 token 这个问题也是要打问号的。
-
为什么说绝大多数人都没搞懂区块链接,区块链的实质创新是什么 at 2018年02月11日
我现在不敢单独说一个区块链项目好坏。牵扯利益是一方面,另一方面是来吵的人通常很暴怒又不知道自己在说什么,但这些都是小问题。
区块链是解决去中心化问题的一个手段,不代表所有去中心化问题都可以用区块链解决。现在啥玩意都能套区块链,况且区块链已经成熟解决的货币去中心化问题,还有一堆问题讨论了好多年至今都找不到解决方案。
某某项目做区块链物联网,看了半天也没看出和以太坊做有啥区别。动不动说自己是 OSI 第三第四层的底层协议,明明没有现有 OSI 第三第四层你连设备发现都做不出来。
动不动说自己是区块链几点零。某某翻了不知道多少倍的项目,做的不是 devcon 上说了很多次的 sharding 吗?会上提到的问题怎么又不解释了呢?
一堆项目从 17 年憋 ppt,憋到 18 年憋了白皮书,里面要么公式都没,要么公式都在胡扯。翻遍 GitHub 也没找到实现了点啥。但最最大的问题是,靠着同行衬托,做到这些都已经是明星项目了,当然涨个不停,就是可以投资啊。
我最早接触比特币的时候,丝绸之路还很火。这么多年看了各种白皮书、黄皮书,后来又开始读大项目代码细节。但越看越多,越看越深入,这个疯狂的市场,越来越看不懂。
每次一说区块链的问题,就有人冲上来:你比中本聪、Vitalik 还牛逼?你想的问题他们想不到?我确实不比他们牛逼,因为他们确实想到了啊。bitcointalk 和以太坊的 Devcon 这些问题都讨论好久了。这些资料 Google 很好搜,会议也是全程录像的。被有些人一问我也怀疑了,到底是我牛逼,还是你们瞎啊。
在今年 1 月 16 日写了篇骂区块链的文章,当晚就在各种韭菜群里被狂骂。写完第二天区块链各个币都暴跌了,如果这些币当中真的有哪一个超越了比特币,真真正正解决了不得了的问题,为什么大家跌得比比特币还狠呢?
所以我现在是不想再多说什么了。
附 1 月 16 日写了如下这篇文章:
中本聪的野望
在说这个问题之前我们还是先来理一下区块链是什么。中本聪在白皮书中通过描述区块链的机制,目的是实现一种点对点的电子货币系统。
简单来说就是设计出了一种账本系统,保证账本系统内的所有人都不能篡改账本的共识。为了实现这一目的,区块链首先被设计成了一个类似于「顺序表」的系统,只能不停往上增加数据,不能在任意地方随意插入数据。其次,引入了 PoW (Proof-of-Work) 机制,其基于哈希 (hash) 这一概念。
每一个区块的产生需要计算自己所有数据和上一个区块的哈希的哈希,同时这个哈希还必须以多少个 0 开头。由于我们无法反向计算一个以多少 0 开头的哈希数据长什么样,只能纯随机地进行猜测,但我们又很容易验证这个结果。最后一个需要解决的问题是如何鼓励人们去产生下一个区块,也就是挖矿。给那个算出这个结果的人奖励一定的货币,即解决了发行问题,也解决了共识问题。
于是中本聪基于一个纯数学的概念创建了一个公开、透明、对等的账本系统。再也没有了中央银行,人民的财产由人民自己保护,谁对维护社会做得贡献多,谁就能获得更多的资产。
按劳分配,完美!
完美…吗?
答案是否定的。比特币诞生后的不久就产生了一个违背比特币原则的许多发明:矿场、瘦钱包。
矿场
我们先来谈矿场。挖矿之所以保护了所有用户的权益基于的是其博弈的数学本质。然而随着比特币的区块难度上升,单个设备挖出矿的概率很低,虽然一旦挖出就是一笔巨款。为了降低风险,矿工们选择抱团挖矿,这也就诞生了矿场。为了降低挖矿的成本,现在的矿机被设计得非常简单,验证区块合法性这个本身被设计的挖矿目的被某个矿场中心所替代,所有的从机只负责算哈希。放弃义务的后果就是放弃了权力,矿工们今天已经沦为了矿场的利益工具。像比特币现金、比特币钻石、比特币黄金这些一个比一个胡扯的东西被分叉了出来。参与分叉的矿工大多甚至都没有意识到自己的挖矿工具突然参与这次分叉活动。
比特币不是共产主义,它不会保护产生有钱人。但比特币设计基于的算力博弈,是需要保护不能产生一个算力巨头的。矿场的诞生使得这个设计彻底破灭。
瘦钱包
瘦钱包在比特币的白皮书中被简要提到过:「不运行完全节点也可验证支付,用户只需要保存所有的 block header 就可以了。用户虽然不能自己验证交易,但如果能够从区块链的某处找到相符的交易,他就可以知道网络已经认可了这笔交易,而且得到了网络的多少个确认。」
这里说的是「验证支付」而不是「验证交易」。为了验证交易,我们需要存储了整个区块链的完整节点。在比特币的原始白皮书中,并没有故意去分开钱包和节点。作为一个 P2P 网络他们应该是一体的。但今天我们看到有完整节点钱包的用户凤毛麟角。写稿的时候,全世界共有 11611 个节点,其中中国有 827 个节点。这一数字已连续下降数年。
维护比特币钱包是困难而昂贵的,节点消耗大量的硬盘、带宽、电,很多用户也没有维护节点的运维能力。如果是用完就关,那更是吸血驴一般。而比特币矿场、交易所们,维护了这些节点。他们从维护节点中获取到了更大的利益。数量过少的节点更可能被政治冲击、技术冲击。
更何况,P2P 网络依然需要种子连接来启动,这并不是完全的去中心化。如果 DNS Seed 遭到劫持,理论上可以通过修改,手动编译来解决,但现在的区块链用户们,具备这样的专业素质吗?
这就类似于电驴是 P2P 技术,但我们可以把 VeryCD 端了啊。BT 下载是 P2P 技术,我们先培养迅雷吸血用户,再把迅雷一锅端了,你到哪里去找 Peer 节点去?
以太坊很忙
比特币之后,区块链 2.0 的头衔常放在以太坊身上。对于上述的问题,以太坊一个都没有解决。相反,以太坊引入了更多问题。以太坊引入了一个图灵机 EVM,用于执行合约。听起来好像很好,但以太坊则是从空想社会主义踏入了空想共产主义。以太坊引入了 gas 来评估合约运行成本,这是一个极其粗糙的模型。以太坊无法正确评估一个合约的资源消耗,如果你要在运行程序前知道这个程序的运行花费,这等价于图灵停机问题,是理论上的无解。
加入了图灵机并不代表可以解决所有问题。像 Filecoin 这种在区块链上存储文件的模型,通过 PoSt 证明了存储,但对于流量又无法证明。这使得所谓的万能应用根本无法实现。更不要扯迅雷那种可以自己停机的所谓「区块链项目」了。
更麻烦的是,gas 同时评估计算、内存和存储,这使得标准非常失衡。对于某些合约定价可能过低,对于另一些则过高。在以太坊上,这种事情的发生是日常。活跃的合约比起一个账本实在是过于复杂了,这使得以太坊的拥塞极易发生且很难预测。
速度、安全性、规模三者不可兼得,必须舍弃一个。以太坊舍弃了规模,现在某些号称自己是区块链 3.0 的系统则是舍弃了安全性。目前根本没有一个完美的方案来平衡这之间。
比账本更复杂的合约也造成了很多问题,如果合约本身签得有问题怎么办?对于这个问题,大多数以太坊合约都通过后门的形式允许发布者二次修改合约,而签订者毫无还手之力。这使得以太坊空空增加了这一大堆问题,对于其想要达到的开放、平等的合约系统也没有实现。
代币邪恶论
对于这些问题,许多人仍选择视而不见。而代币的狂热更是让投资人的热钱滚滚涌入,与其说是投资,这毋庸置疑是投机。这些投资人白天在会议上吹着区块链技术,晚上自己连区块链的实现原理根本不了解。做互联网的、买房的、养猪的、炒股的、炒期货现货的都在把钱扔进来,有钱不赚当傻子?还有人声称区块链「代币」是邪恶的,但「区块链技术」本身不是,可以有巨大的应用场景。醒醒吧,世界上就没有区块链技术。区块链技术里的每一样东西都是我们学习密码学都见过的。像是给企业内部部署私有链,完全也是无稽之谈,靠简单的公钥私钥就能解决的事情,非要套上区块链的外壳,把事情复杂化。今天说「代币」是邪恶的,但「区块链技术」本身不是的,说到底是资本的既得利益者,他们要么希望让泡沫更高,或是希望借机在其中捞一笔。
不得不说,今天的区块链和 2008 年的次贷危机的前奏已经非常像了。次贷危机之所以能危机,是因为通过次贷,使得账目表面上没有那么难看,等无法收场时,就已经变成巨大的窟窿了。区块链的今天也是这样,所有的事情都在掩盖代币,通过一次次的 ICO 和新概念,掩盖之前区块链已有的问题。一旦问题爆发,涉及到的资金将是空前的,甚至是远超 2008 次贷危机的。并且区块链的全球化、点对点的特性会让任何政府直接调控的难度变高,将会成为前所未有困难的金融大危机。
我不希望这一天会发生在 2008 年后 10 年的 2018。
-
RubyMine 的 object literal (不知道是否可以这么称呼) 的 formatting 出错 at 2018年02月11日
看了下 RubyMine 应该会尊重你对 Hash 构造的换行,只是会调整缩进。试了几次都没有复现这个情况。
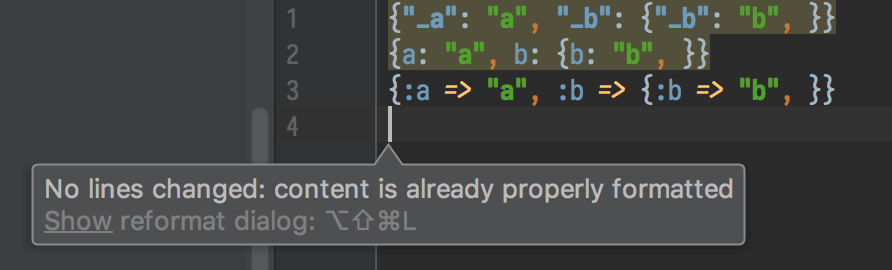
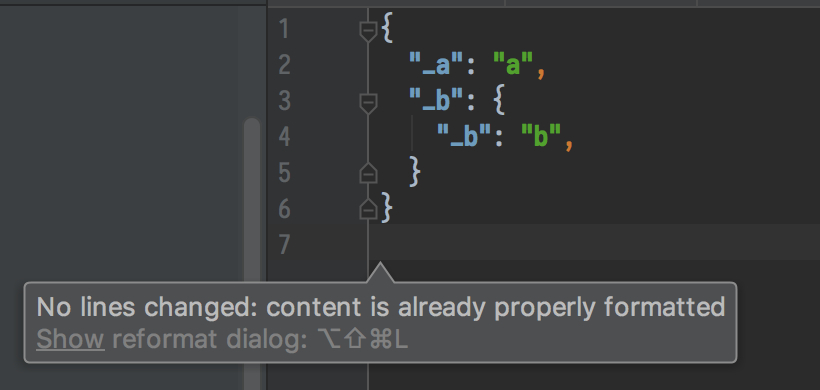
Format 前:
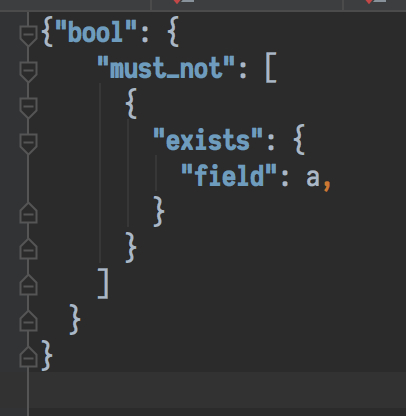
Format 后:
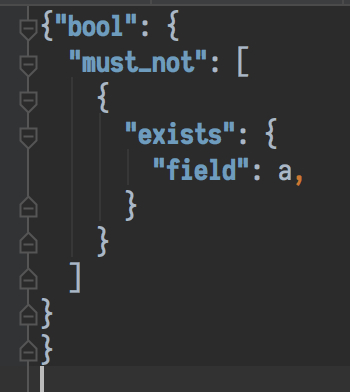
我的 RubyMine 版本是 2017.3.2。不知道是不是和版本有关
-
C 线程默认就是绕开 GIL 的,反而是你回调 Ruby 线程才需要主动加锁。这个问题,7 年前就加入对应的 C API 了。Feature #4328
MJIT 解决的问题和 AutoFiber(Thread::Green) 解决的不是一个问题,对性能都有很大的影响,但影响的地方不一样。一个是计算,一个是 I/O。
Green Thread 不是 Thread。哪怕在 Ruby 3.0 目前的规划中,跨 Thread 永远是有锁的,Guild 间可以无锁,一个 Thread 可以部署多个 Guild,Guild 间不能共享变量,必须依赖 Guild 通讯。而 Thread::Green 甚至可以是 Guild 之下的,可见和 Thread 没啥关系,更接近于单线程版本的 goroutine。Thread::Green 的加入使得不必使用 Thread 的地方可以不用 Thread,降低上下文切换的成本,这对 Ruby 虚拟机性能影响是很大的。
和 Cocoa 里的 GCD libdispatch 做的也完全不是一个东西。GCD 是对于线程的封装,是来解决并行问题的,而 Thread::Green 是来解决并发问题的,并行不是并发的唯一解决方案,Thread::Green 也不是并行的方案。
-
JIT for MRI 开始开发了 at 2018年02月11日
MJIT 这个优化还是要先讨论一下 https://github.com/vnmakarov/ruby/tree/rtl_mjit_branch 这个 branch,在 Ruby Issue 上是 Feature #12589。2017 年 RubyKaigi 上最后一个大演讲就是这个。
演讲见此:https://www.youtube.com/watch?v=qpZDw-p9yag (各位可能要熟悉一下毛式英语)
Vladimir Makarov 在 Redhat 里工作,开发 gcc 了 20 年。来优化 Ruby 解释器上手就是一套连招,可以说是相当厉害,一个叫 RTL,一个叫 MJIT。在此之前 JIT 在 MRI 上的尝试也有一些,这里就主要说一下这个实现的不同。
_______ _________________ |header |-->| minimized header| |_______| |_________________| | MRI building --------------|---------------------------------------- | MRI execution | _____________|_____ | | | | ___V__ | CC ____________________ | | |----------->| precompiled header | | | | | |____________________| | | | | | | | MJIT | | | | | | | | | | | | ____V___ CC __________ | |______|----------->| C code |--->| .so file | | | |________| |__________| | | | | | | | MRI machine code |<----------------------------- |___________________| loading首先,MJIT 和 YARV 的实现是解耦的。这一点很重要,Rubinius 支持 JIT 了一段时间又不支持了,很大程度上就是和虚拟机耦合在一起的 JIT 实现会把开发进度拖入泥潭。一方面,Ruby 语言本身还在发展,在 JIT 开发过程中会不会牵制语言。对于对于调试的难度也有很大的上升。而 MJIT 可以很容易开关,类似于外挂在 YARV 上,这是非常好的。
RTL 指的是 Register Trasfer Language。gcc 的中间语言就是表示为这种形式。vnmakarov 用这玩意作为 Ruby 的中间语言,来替代 YARV 的 ISEQ 设计。RTL 比起基于栈的中间语言设计,执行速度和对内存的消耗都更少,给予更大的优化空间。
这一套连招打完对于性能的提升可以说是非常恐怖的。我们看一下 benchmark:
v2 base rtl mjit mjit-cl omr jruby9k jruby9k-d graal-22 while 1.0 1.11 1.82 387.29 9.28 1.06 2.3 2.89 2.35 nest-while 1.0 1.11 1.71 4.97 3.97 1.05 1.38 2.58 1.66 nest-ntimes 1.0 1.02 1.13 2.19 2.43 1.01 0.94 0.97 2.19 ivread 1.0 1.13 1.31 13.67 9.48 1.13 2.42 2.99 2.33 ivwrite 1.0 1.18 1.78 15.01 7.59 1.13 2.52 2.93 1.97 aread 1.0 1.03 1.44 19.69 7.03 0.98 1.79 3.53 2.17 awrite 1.0 1.09 1.42 13.09 7.45 0.96 2.18 3.74 2.55 aref 1.0 1.13 1.67 25.73 10.17 1.09 1.87 3.69 3.71 aset 1.0 1.51 2.68 23.45 17.82 1.47 3.61 4.49 6.33 const 1.0 1.09 1.53 27.53 10.15 1.05 2.98 3.89 3.01 const2 1.0 1.12 1.31 26.13 10.06 1.09 3.05 3.81 2.41 call 1.0 1.14 1.54 5.53 4.75 0.9 2.18 4.99 2.86 fib 1.0 1.21 1.43 4.16 3.81 1.1 2.17 5.03 2.26 fannk 1.0 1.05 1.1 1.1 1.1 0.99 1.71 2.32 1.02 sieve 1.0 1.3 1.72 3.34 3.36 1.27 1.49 2.42 2.02 mandelbrot 1.0 0.94 1.11 2.08 2.11 1.08 0.96 1.56 2.45 meteor 1.0 1.24 1.27 1.71 1.71 1.16 0.9 0.92 0.54 nbody 1.0 1.05 1.14 2.73 3.07 1.26 0.97 2.31 2.14 norm 1.0 1.13 1.09 2.52 2.49 1.15 0.91 1.45 1.62 trees 1.0 1.14 1.23 2.3 2.21 1.2 1.41 1.53 0.78 pent 1.0 1.13 1.24 1.71 1.7 1.13 0.6 0.8 0.33 red-black 1.0 1.01 0.94 1.3 1.14 0.88 0.98 2.52 1.03 bench 1.0 1.16 1.18 1.54 1.57 1.15 1.28 2.75 1.81 GeoMean. 1.0 1.12 1.39 6.18 4.02 1.09 1.59 2.48 1.83 可以说是脚踩 Graal,吊打 JRuby,3x3 目标立刻实现。三倍是什么?提升六倍也可以啊。
去年演讲结束后,就有提问在会上劝进 Matz 要不要合并。Matz 的意思是很明确的,说这玩意好应该合并,然后就基本上钦定硬点会后这半年来社区 JIT 的努力方向。
但这次合并到主干的代码和 RTL-MJIT 还是区别很大的,Issue 为 Feature #14235。首先合并的不是 Vladimir 完整的 fork,而是一个由 Kokubun 拉出来的分支,这个分支叫做 YARV-MJIT。只包括 MJIT 的部分,只在 JIT 中使用 RTL,而没有在 IR 上完全用 RTL。
这是因为,RTL 版本的 MJIT 要通过回归测试得到合并,短时间内要做的工作太多了。而且 Ruby 还在发展,要 RTL 的开发也完全跟上难度很大。合并的理由主要是 trunk 上很多优化工作和 MJIT 重复了,不要把一件事做两遍。另外就是这个提交的 issue 和 YARV-MJIT 开发主分支上还有一些区别,去掉了一些激进的优化,这使得性能比 YARV-JIT 更慢一点。至少能用了。
benchmark 大约是比 2.0 提升了 2 倍左右,比完全体的 RTL-MJIT 的 6.18 倍还是慢了不少。但这个合并至少确认了 MRI 的 JIT 开发方向,减少了大家做的许多其他尝试。但这个优化在回归上还是有一些问题,也有一些 bug。即使合并了,也需要在加入特定参数才会开启,2.6.0 里并不会默认启用。
另外就是标题里这个「开始开发了」,其实不太对,开发了快一年了,这次是要开始合并到 Ruby 主干了。
-
这么说倒是,应该对 Ruby Thread 做过处理的应该都会调用到这些方法了。
-
对,方案就是增加这些 hook。但这些 C 扩展还是要手动手动加上 hook 以支持。这几个本质是让同步等待由 Ruby 去监听 fd,等变化了再返回来调用 C。不知道第三方社区的跟进力度会如何了。
-
Linux、Ruby 不冷没天理! at 2018年02月04日
好久没看到那么有意思的帖子了。
“我”技术不行,我用工具干嘛得懂怎么修理工具?
当然自己不会修,受制于人的话,那其实这几个也没啥区别。但是工具出了问题,还是要有人来修的。如果微软家的系统真的可以通过花钱解决一切问题的话,那我也愿意花钱解决,谁没事喜欢自己乱折腾呢。
2016 年的时候我上报了一个在 Windows 更新后产生的 UAC 权限的严重 bug,提交了大半个月还没 fix。打电话给客服和我说直接重装系统吧。感觉微软家几个客服里也就只有 Azure 的客服专业点。
后来上微博发了牢骚,又得到了微软微博客服的官方回复。

最后只好停机 fresh reinstall。
当然苹果也好不到哪去,有一次给 Safari 的 JavaScript 引擎 Nitro 提交了 bug report,拖了一个大版本,Safari 从 9 升到了 10 才 fix 的。
Linux 嘛,逼急了至少还有自己修的可能嘛。
苹果......你知道苹果系统多少?你知道苹果的手机和笔记本为什么配置这么高?
微软......你知道微软系统多少?你知道微软的服务器为什么配置这么高?

完全一致!
-
有考虑使用 Sinatra + ActiveRecord 替换你的 Rails 项目吗 at 2018年02月04日
引入 ActiveRecord 其实就可以考虑不要上 Sinatra 了,ActiveRecord 还依赖 ActiveSupport,一通下来,已经半个 Rails 都导入进来了。除了写路由的方法发生了变化,总的来说没有区别。特别是加个 WebSocket 还要自己处理集群平衡。如果使用 Redis (Ohm) 做数据库,那感觉还是挺爽的,明显会变快不少。重写一个 ActiveRecord 可以考虑直接上 Sequel 吧,基本满足需求。
-
Auto Fiber 的处理方式非常暴力,Hijack 所有的 I/O 操作,然后直接去把 fd 取出来塞进去,我写的 midori 在处理 redis 连接的也参考了这一做法。Auto Fiber 目前面临最大的一个难点就是 C 语言里面的 I/O 阻塞,因为 I/O non-blocking 的问题是一处阻塞,处处阻塞。
去年 RubyKaigi 我演讲完会后 ko1 问了我怎么看 Auto Fiber,我就讲了这个顾虑。因为 Auto Fiber 的 Hijack 还是基于 Ruby 层的 I/O,如果是 C 扩展,则并不能全自动的转换过去,相应地 C 扩展里需要正确使用 Ruby 新加入的 API,例如
rb_iom_waitfd和rb_iom_waitpid等进行处理。如果 C 程序直接使用了同步方法,或者没有正确使用异步方法,Ruby 并不会主动去调度这些东西。另外一个难点就是 Mutex。比如 midori 在 monkey patch Redis 驱动的时候,一上来就遇到了死锁问题,这是因为驱动本身并没有考虑到异步后的数据顺序问题。于是额外对里面的锁结构进行了改造,类似的问题在一些 DB 驱动上也是比较常见,甚至 Ruby 一些内置方法的 C 实现也受到影响。
这事实上对于社区压力还是挺大的,现在 Ruby 还是挺想合并 Issue #13618 的,但对于生态的影响也确实有顾虑。不过感觉最倒霉的还是 socketry,iom.h 合并进来,至少把 epoll 和 kqueue 都统一实现了,再不济 nio4r 也没啥意义了。我写的 midori 也有一大半功能都没啥用了。不过长远来看,这也是终于从语言、标准库层面接入异步了,可以说非常进步了,随着 Ruby 3 现在的特性来看,Thread 里包 Guard 里包 Auto Fiber 可以说并发上会很爽。
-
MySQL 惊险恢复记 at 2018年01月05日
4 GB 的 log,只有几百 MB 的数据库。。。
-
Ruby 2.5.0 已发布 at 2017年12月31日
这其实是一个回归问题,报错的复现是:
[].delete 1 { 'NG' }在 Ruby 2.3 系列以及更早的 Ruby 版本中,从 2.3.0 到 Ruby 2.3.5 中,这个语法是非法的,会报错。
❯ ruby --dump=parsetree -vwce "[].delete 1 { 'NG' }" ruby 2.3.5p376 (2017-09-14 revision 59905) [x86_64-darwin17] -e:1: syntax error, unexpected '{', expecting end-of-input [].delete 1 { 'NG' }在 Ruby 2.4.0、Ruby 2.4.1 中,会返回
NG。parser 的结果如下:
❯ ruby --dump=parsetree -vwce "[].delete 1 { 'NG' }" ruby 2.4.1p111 (2017-03-22 revision 58053) [x86_64-darwin16] Syntax OK ########################################################### ## Do NOT use this node dump for any purpose other than ## ## debug and research. Compatibility is not guaranteed. ## ########################################################### # @ NODE_SCOPE (line: 1) # +- nd_tbl: (empty) # +- nd_args: # | (null node) # +- nd_body: # @ NODE_PRELUDE (line: 1) # +- nd_head: # | (null node) # +- nd_body: # | @ NODE_ITER (line: 1) # | +- nd_iter: # | | @ NODE_CALL (line: 1) # | | +- nd_mid: :delete # | | +- nd_recv: # | | | @ NODE_ZARRAY (line: 1) # | | +- nd_args: # | | @ NODE_ARRAY (line: 1) # | | +- nd_alen: 1 # | | +- nd_head: # | | | @ NODE_LIT (line: 1) # | | | +- nd_lit: 1 # | | +- nd_next: # | | (null node) # | +- nd_body: # | @ NODE_SCOPE (line: 1) # | +- nd_tbl: (empty) # | +- nd_args: # | | (null node) # | +- nd_body: # | @ NODE_STR (line: 1) # | +- nd_lit: "NG" # +- nd_compile_option: # +- coverage_enabled: false这是一个不符合预期的 parser 行为,所以应该被移除。移除的工作发生在 Ruby 2.5.0 的开发过程中,见:Issue #13547。
因此,在 Ruby 2.5.0 中,该行为已被修复。但是需要注意的是,这不止是 Ruby 2.5 系列才这么进行了修改,Ruby 2.4.2 同样也解决了这个回归问题。
这引发了另一个 Issue, Issue #13898,说的是 Ruby 2.4.2 作为小版本更新,是否应该保持和 2.4.0、2.4.1 的向后兼容。目前该 Issue 已被 Rejected,回归问题可能不作为向后兼容的考虑。
-
Rails 时安装 Nginx 不成功 at 2017年12月30日
给 log 加个 code block 啊,这排版咋看。。。
看了一下,没找到哪里报错啊?
-
为什么 Ruby 这么好用,却从未进入 TIOBE 前三名? at 2017年12月30日
没有啦,至少人家就事论事的话,如果能最后达成共识,也是好事啊。
-
为什么 Ruby 这么好用,却从未进入 TIOBE 前三名? at 2017年12月30日
你先等等。。。
如果 JIT 对 Ruby 那么重要,对标 LuaJIT,Ruby 也有已经实现了 JIT 的 JRuby 和 Rubinius 啊。。。
JRuby 倒是去年搞了个 GraalVM + TruffleRuby,真的还挺快的。但还是风声大雨点小。
最近 Rubinius 还把 JIT 从实现中移走了🤦♀️
-
为什么 Ruby 这么好用,却从未进入 TIOBE 前三名? at 2017年12月30日
Ruby 的官方实现 JIT 现在还是没有的,MJIT 目前还在比较初步的开发状态。可能 2020 年前才有可能加。Python 是 1991 年发布的最早版本,Ruby 是 1995 年,Java JDK 1.0 是 1996 年。Ruby 随着 YARV 的引入,现在也可以编译到 Bytecode,也可以说是某种意义的编译语言了,但是和 Java Hotspot 区别还是比较大的。要是说像 Python,我就更想不出什么原因了。
如果不是 VM 层面,而是语言层面,倒是讲得通一些。Ruby Python 和 Java 肯定都有不少像的地方。Ruby 不严谨地来看,特别是早年可以看成是 LISP + 面向对象 + 减少括号 + Perl 里的字符串。Java 从 LISP 和 Smalltalk 里学了很多东西,而 Python 也是一门很像 LISP 的语言。。。那么 Ruby 和他们像不如说是大家都像 Lisp 吧。
这么一想,其实还是挺推荐 Rubyist 去接触一下 LISP,可能会对 Ruby 的一些设计理解得深刻许多。LISP 是一门 1958 年的语言,是世界历史第二悠久的高级语言,但是确实有很多很有远见的设计。
-
为什么 Ruby 这么好用,却从未进入 TIOBE 前三名? at 2017年12月30日
为啥 Ruby VM 结合了 Java 的 Hotspot 和 Python 的 Interpreter?感觉都没啥关系啊?
-
有没有人在树莓派上玩 Ruby on Rails? at 2017年12月30日
我前几年在 Raspberry Pi 2 上跑过一次,就是实验性地用了一下,当时发现的一个问题是 Hash object 的 performance 不是很好。用来跑 Rails 不是很确定。
-
『编程项目赚了两千万』,这些人的良心不会痛吗? at 2017年12月30日
其实这个项目现在想想还是很有问题的。当时 xdite 在台湾的时候就已经惹出过很多事情了,哪怕是后来某个帖子说的什么「肌肉记忆」,其实这个说法 xdite 在台湾就说过很多次。
2015 年的时候我去台北参加会议,就已经听到了还多 xdite 的负面新闻,包括其实更早,在 2014 年就搞出过「由爱生恨之诈神传」的事情。包括有一个生成 xdite 幹话语录的 Ruby gem,也是在 2014 年发起的。我当时写炮灰工程师文章前在一些大陆的 Ruby 群里也问过,发现大多数人都不知道这些事。
我觉得这个还是解释了,xdite 和李笑来来大陆办这个培训班,社区一开始觉得是好事,有一个问题是可能也是两岸的交流不是很多,信息比较闭塞,大家当时确实对对岸已经发生过的 灾难 没有意识。更何况,培训的价格和台湾当时她开的一致,只是货币从新台币换成了人民币(这点真是厉害啊)
至于 xdite 其人,我倒是觉得她是个利益至上、见风使舵的人。这可以解释很多问题,包括当时 xdite 也写过一些台独的文章,现在也能找到一些 Tweets 她之前说自己是绿啊什么,后来 xdite 突然开始骂柯 P 墨绿啊台独的时候,又把这些文章删掉了。大家有兴趣可以去 Web Archive 上找找 blog.xdite.net 删掉的内容。我倒不是觉得台湾人不能持有台独的观点,这是自由,但是持有这样观点的人,过了没几年突然就把中国改口叫大陆来大陆赚钱,自然是为了钱可以放下信仰的表现。
这么看来 xdite 与李笑来的合伙是完美的,一个是见风使舵的人,一个是吹风大师。至于你问:
这些人的良心不会痛吗?
一个有良心的人会见风使舵和乱吹风吗?
-
Ruby 2.5.0 已发布 at 2017年12月28日
jemalloc 这玩意好是好,就是没见过几个人用(逃
-
Ruby 2.5.0 已发布 at 2017年12月28日
2.6 的 JIT 可能不会被编译,需要手动开启编译选项才行。。。
-
Ruby 2.5.0 已发布 at 2017年12月26日
谢谢提醒,因为前几项和 rc1 版本一样我拿过来了🤦♀️
-
UCloud 已经不是 UCloud,而你大爷还是你大爷 [2017/12/25 更新] at 2017年12月25日
我不用查维基,我也知道 ACID 指代的是哪四个单词。这不是一个要背的概念,这是任何一个深入使用数据库的人都应该掌握的知识,也是大学本科教学的内容。不知道是你的问题,不是我的问题,也不是维基百科的问题。
-
UCloud 已经不是 UCloud,而你大爷还是你大爷 [2017/12/25 更新] at 2017年12月25日
”你个中间件做 reduce 的玩意“:你可能不知道,阿里云 Hybrid MySQL(请注意:是 MySQL,不是 PG,不要再搞错了),就是基于一个中间件发展起来的。
你先来找找哪里我说 PG 了?
-
UCloud 已经不是 UCloud,而你大爷还是你大爷 [2017/12/25 更新] at 2017年12月25日
回到 23 号关于形式化验证的讨论。当时我在给另外一为客户,讲解 UDDB 架构的问题。旁边的你突然插问测试的问题。我当时问:是不是指 SQL 覆盖性测试。然后你说是,并说 TiDB 做了形式化(确切地说,你当时用的是 Formal Verification,我翻译成形式化验证是不会有错的)。我当时表达了这不可能。因为如果能够对 SQL 代码做形式化验证,那么大部分公司都应该不需要测试人员了。
不要说你翻译的啥,我当时用的就是中文「形式化测试」。我当时问的是「你对架构怎么进行测试的?」你回答说「我们有一些测试」。这句废话回答得很好,我只好接着问,是通过了什么测试,是 MySQL 自己的测试集吗?然后你回答「对,类似的」。我立刻提出,MySQL 自己的测试集不能覆盖这种集群情况,哪怕是已经做了集群测试的 AWS 和 TiDB 也在做了形式化验证后发现了更多问题。到你这里就变成什么玩意了?
是听力不行,理解力不行,还是故意来混淆视听?
至于你说「因为如果能够对 SQL 代码做形式化验证,那么大部分公司都应该不需要测试人员了。 」你这对形式化验证的理解真是弱啊。你形式化验证通过,代表你形式化验证本身是正确的了吗?还来说什么「那么大部分公司都应该不需要测试人员了。 」我看你不但是完全不懂数据库,连测试都不懂吧。
-
UCloud 已经不是 UCloud,而你大爷还是你大爷 [2017/12/25 更新] at 2017年12月25日
而分片内多副本一致性,是指在分布式系统里(出于容灾或读性能提升考虑,需要多副本),需要多副本部署。这就产生的多副本一致性的问题。
多副本一致性的解决,一般采用 Paxos、Raft 算法,你用了吗?你不是和我说「MySQL 会自己解决的吗?」
在我的个人经验里,任何哪怕具有一点数据库从业经验的技术人员,都应该是能够清晰地识别这个概念的。
对的,所以你不能,你是想说你一点数据库从业经验也没有吗?
-
UCloud 已经不是 UCloud,而你大爷还是你大爷 [2017/12/25 更新] at 2017年12月25日
等那么久终于等到当事人回应了,如果当事人是这么一个偷换概念的态度和理解,我想实在是非常说明问题的。
分布式事务
当时的情况,是我和另外一位客户(我们组总共有 4 位客户)在讨论 UDDB 如何实现分布式事务,所以我介绍了二阶段提交的做法。您在中间插问了节点间多副本一致性的问题,因为当时我们在探讨分布式事务的问题,而多副本一致性问题跟分布式事务无关(是完全独立的两个问题),所以当时我说的是:这并不是我们讨论问题(分布式事务)的范畴。
我先来给你念念维基百科:
为保证事务(transaction)是正确可靠的,所必须具备的四个特性:原子性(atomicity,或称不可分割性)、一致性(consistency)、隔离性(isolation,又称独立性)、持久性(durability)。
连一致性都做不到还来谈分布式事务?你是看 2PC 看傻了吧。2PC 协议是分布式事务的解决方案,用于保证属于多个数据分片上的操作的原子性。根本保证不了数据分片内的数据的一致性,完全不适用于 UDDB 的场景。保证不了这一点,也没有任何额外的解决方案,既不满足 ACID,也不满足 BASE,还来谈什么分布式事务,甚至说出事务和一致性是无关独立的问题,也是六得不行。
形式化验证
您提到 TiDB 对 SQL 解析代码做了形式化的验证,然后发现了几个 bug,同时提到 aws 也有这样的方法。我认为的是,对 SQL 解析的代码做形式化验证,这是一个不可能有解的问题。UDDB 只是收集了很多 SQL 测试用例来做测试,而 TiDB 这块也是这么做的。
我和你解释了三遍这个 Formal Verification,倒最后没想到理解的还是「对 SQL 解析代码做了形式化的验证」。被怼了一天一夜,你不会上 Google 查一下到底是做了什么验证吗?
http://lamport.azurewebsites.net/tla/formal-methods-amazon.pdf
这里有一篇 AWS 自己写的 paper,自己念一下再回来说。
OLTP
我的理解是在讨论一个概念时,需要结合实际的应用场景才有意义。HTAP 从概念上理解,是 OLTP+OLAP,但技术需要结合具体的产品讨论才有意义。正如我当时举得一个阿里云 Hybrid MySQL 的例子,阿里云 Hybrid MySQL 也称之为 HTAP,但假如你看过阿里 Hybrid MySQL 的产品文档,你就会发现,他们文档里面写得很清楚,针对的场景就是物联网、大数据分析等领域,并不是涵盖 OLTP+OLAP(所以我当时反问过你:如果 Hybrid MySQL 能涵盖 OLTP+OLAP,那就是阿里下一代产品了,又为何定位在物联网和大数据分析领域?)。假如你对分布式数据库产品多去了解一点,这个结论是不难得出的。
我先不说别的,阿里云的 Hybrid for HTAP 在 Sharding 上还做了分区键。要是阿里云的 Hybrid for HTAP 连 OLTP 都做不到,你个中间件做 reduce 的玩意也敢说自己能做到 OLTP?阿里云怕杀鸡用牛刀说「针对的场景就是物联网、大数据分析等领域」,到你嘴里就变成除了这个就干不了别的了,我也是佩服得不行。
另外既然当时我举的例子既然是 TiDB,你回去打开自家 UCloud 的官方网站
https://www.ucloud.cn/site/product/cloudtidb.html
这里对 TiDB 怎么描述的啊?你要不要继续回去打你东家的脸才开心?
TiDB 的设计目标是 100% 的 OLTP 场景和 80% 的 OLAP 场景。
这就是 TiDB 对自己 HTAP 设计目标的描述。
结
本来觉得这个事情造成的影响很大,特别是对 UCloud 公司的影响是超出预期的,也想避免扩大影响。没想到当事人竟来上一篇这么偷换概念的文章,看来是丝毫没有悔改之意,我必须予以驳斥了。
-
调查显示编程语言 Ruby 在缓慢衰落,缺少爆发点 at 2017年12月24日
我觉得有个问题是,Ruby 或者 Rails 一直都没有做错什么事。另一方面 Ruby 社区看事情也不是那么激进,也一直没有话题可以炒。就不像 JavaScript 社区随便出个什么新东西就能立刻把老东西的全家都批判一遍🤦♀️
-
消息提醒的未读数字不能重置 at 2017年11月16日
点进去数字只 -1,有个 bias 去不掉,是因为第二页、第三页的未读没有看吧。。。
-
笑而不语 at 2017年11月09日
 Tweet from PikkamanV
Tweet from PikkamanV