-
Ruby 标准库中缺少 rbtree, 严重影响开箱即用,谁能帮忙给核心开发者提议加入 rbtree。 at 2020年07月29日
rbtree 的 patch 当时一个设计是用来优化 SortedSet 的 hash 实现,但是现在 Ruby 的 hash 在 4 年前就改由 Open Addressing 的方法来实现了([Feature #12142])。这就类似于 Java Spark 里面的 OpenHashMap 了,性能远优于闭散列的实现,自然相关的东西就否决了。
如果是实际的算法用途,我记得很早以前 GSoC 有个 Ruby 的算法相关 gem 的实现。但这东西能不能进标准库,我表示怀疑。不过目前线下的算法比赛,不管是 ACM/ICPC 还是 OI 应该都是不能用 Ruby 的吧。如果是 Codeforces 或者 Leetcode,虽然不能用 gem,但 gem 也就是 require 的 ruby 文件,提前展开一下做成模板就是了。
-
Ruby 3 Fiber 变化前瞻 at 2020年07月27日
谢谢,已修复 typo。
-
gems 安装或添加源时卡住 at 2020年05月09日
如果是 IPv6 连接的话,应该会涉及到
DNS4 DNS6 IPv4 DNS4 + IPv4 DNS6 + IPv4 IPv6 DNS4 + IPv6 DNS6 + IPv6 这么一个 2x2 的问题。可以先用 https://ipv6-test.com/ 这网站确认自己 IPv6 是正常工作的。看解析出来的 2409:8c54::/32 确实是中国移动机房的地址,像是一个合理的 CDN 节点,不过我这里 IPv6 肯定是好的的情况下打过去也是 100% 丢包。
-
用 Ruby 学习基本乐理(二):音程 at 2020年05月06日
可以可以,我安排一下。
-
sassc Unable to allocate memory: std::bad_alloc? at 2020年04月23日
std::bad_alloc是 C++ 内存申请失败的异常吧。申请失败的常见原因应该是... 你机器上内存已经被吃爆掉了,分配不出可用内存了? -
用 Ruby 学习基本乐理(一):音高 at 2020年04月12日
乐理还是讲相对关系,标准音高其实是可以变的,调律方式也是可以变的。所以我只是用了其中一种比较常用的来写了,毕竟写代码最好还是确定算法确定数值比较好处理一点。
-
用 Ruby 学习基本乐理(一):音高 at 2020年04月11日
Sonic Pi 我也用过,算是可以很方便用 Ruby 来为合成器进行编程。特别是现在高级的合成器按钮越来越多,真的还不如直接弄个 DSL 来写比较方便。
-
RubyConf China 2020 SSR 讲师征集 at 2020年04月11日
其实本来是想在线下的分会场弄一个小的 workshop 尝试的。但现在搬到线上后,互动性没有那么强了,是有点直播 coding 的味道了。
-
RubyConf China 2020 SSR 讲师征集 at 2020年04月11日
差不多比起 Keynote 演讲的纯介绍性,更多地加入 Live Coding 来演示某一种技术的使用。以练习和 tutorial 为主,内容不一定需要太先进或困难。
-
Petri Net workflow for Rails at 2020年02月14日
促进一下生态,我又花了一天写了个 PetriNet 的可视化编辑器 https://github.com/dsh0416/petri-editor
-
WorkflowCore —— SaaS 快速开发套件之工作流引擎 at 2020年02月14日
花了两天时间简单写了个 DSL https://github.com/dsh0416/petri-dsl/
用法:
require 'petri' network = Petri::Net.new do |net| net.start_place :start, name: 'Start' net.end_place :end, name: 'End' net.transition :leader_evaluate, name: 'Leader Evaluate', consume: :start do |t| t.produce :leader_approved, name: 'Leader Approved', with_guard: :approved t.produce :rejected, name: 'Rejected', with_guard: :rejected end net.transition :hr_evaluate, name: 'HR Evaluate', consume: :leader_approved do |t| t.produce :hr_approved, name: 'HR Approved', with_guard: :approved t.produce :rejected, with_guard: :rejected end net.transition :report_back, name: 'Report Back', consume: :hr_approved, produce: :end net.transition :resend_request, name: 'Resend Request', consume: :rejected do |t| t.produce :start, with_guard: :resend t.produce :end, with_guard: :discard end end puts network.compile # {:places=>[{:label=>:start, :name=>"Start"}, {:label=>:end, :name=>"End"}, {:label=>:leader_approved, :name=>"Leader Approved"}, {:label=>:rejected, :name=>"Rejected"}, {:label=>:hr_approved, :name=>"HR Approved"}], :transitions=>[{:label=>:leader_evaluate, :name=>"Leader Evaluate", :consume=>[:start], :produce=>[{:label=>:leader_approved, :guard=>:approved}, {:label=>:rejected, :guard=>:rejected}]}, {:label=>:hr_evaluate, :name=>"HR Evaluate", :consume=>[:leader_approved], :produce=>[{:label=>:hr_approved, :guard=>:approved}, {:label=>:rejected, :guard=>:rejected}]}, {:label=>:report_back, :name=>"Report Back", :consume=>[:hr_approved], :produce=>[{:label=>:end, :guard=>nil}]}, {:label=>:resend_request, :name=>"Resend Request", :consume=>[:rejected], :produce=>[{:label=>:start, :guard=>:resend}, {:label=>:end, :guard=>:discard}]}], :start_place=>:start, :end_place=>:end}大概可以相对方便地来描述 workflow 了。
-
写 Wrapper 是个很难的活么? at 2020年01月17日
我觉得维护一个 OpenCV 的 wrapper 可能先得维护一个线性代数库,返回一个 Array,甚至是 Array 的 Array 的 Array 还是有点蠢的,而且很难处理。ruby 现在有内建的 Matrix 库,不知道能不能堪此大任。
-
又过了两年半,赌博负债累累,回头走 IT 路 at 2020年01月17日
我比较好奇「帮包装」是个什么流程
-
[分享] 再来一个小 Gem (想偷懒的或许可以用得上) at 2019年12月28日
RubyGems 的下载量会把镜像下载也统计进去,1k 以下的参攷意义不是很大。另外,这让我嗅到了一股 leftpad 的味道。。。
-
Ruby 2.7.0 Released at 2019年12月25日
翻译自 https://www.ruby-lang.org/en/news/2019/12/25/ruby-2-7-0-released/
我们很高兴宣布 Ruby 2.7 已发布。
此版本引入了大量新特性和性能提升,其中最值得注意的是:
- 模式匹配
- REPL 改进
- 紧凑 GC(Compaction GC)
- 位置参数和关键词参数的分离
模式匹配 [实验性]
在函数式编程中非常常用的模式匹配功能,作为实验性功能被加入了。功能 #14912 它可以遍历一个对象,并在其满足某一模式时进行赋值。
case JSON.parse('{...}', symbolize_names: true) in {name: "Alice", children: [{name: "Bob", age: age}]} p age ... end关于更多信息,请查阅 Pattern matching - New feature in Ruby 2.7。
REPL 改进
irb,集成的交互环境 (REPL; Read-Eval-Print-Loop),现已支持多行编辑,由reline(一个readline兼容的库)实现了纯 Ruby 的支持。它还提供 rdoc 集成。在irb中您可以为指定的类、模块或方法的显示引用。功能 #14683、功能 #14787、功能 #14918 此外,Binding.irb中显示的代码和核心类的检查结果现在已经可以彩色呈现。紧凑 GC(Compaction GC)
此版本引入了 Compaction GC,可以对内存空间碎片进行整理。
某些多线程 Ruby 程序会导致内存碎片化,进而导致内存占用率提高和速度降低。
我们引入了
GC.compact方法来压缩堆。此函数能压缩堆中的存活对象,以更少地占用内存分页。并且堆可能会变得对写入时复制(CoW)更友好。 功能 #15626位置参数和关键词参数的分离
关键词参数和位置参数的自动转换被标记为已废弃(deprecated),自动转换将会在 Ruby 3 中被移除。[功能 #14183]
请查看文章 "Separation of positional and keyword arguments in Ruby 3.0" 来了解详情,下面仅叙述变更之处。
- 当方法传入一个 Hash 作为最后一个参数,或者传入的参数没有关键词的时候,会抛出警告。如果需要继续将其视为关键词参数,则需要加入两个星号来避免警告并确保在 Ruby 3 中行为正常。
def foo(key: 42); end; foo({key: 42}) # warned def foo(**kw); end; foo({key: 42}) # warned def foo(key: 42); end; foo(**{key: 42}) # OK def foo(**kw); end; foo(**{key: 42}) # OK- 当方法传入一个 Hash 到一个接受关键词参数的方法中,但是没有传递足够的位置参数,关键词参数会被视为最后一个位置参数,并抛出一个警告。请将参数包装为 Hash 对象来避免警告并确保在 Ruby 3 中行为正常。
def foo(h, **kw); end; foo(key: 42) # warned def foo(h, key: 42); end; foo(key: 42) # warned def foo(h, **kw); end; foo({key: 42}) # OK def foo(h, key: 42); end; foo({key: 42}) # OK- 当方法接受关键词参数传入,但不会进行关键词分割(splat),且传入同时含有 Symbol 和非 Symbol 的 key,那么 Hash 会被分割,但是会抛出警告。你需要在调用时传入两个分开的 Hash 来确保在 Ruby 3 中行为正常。
def foo(h={}, key: 42); end; foo("key" => 43, key: 42) # warned def foo(h={}, key: 42); end; foo({"key" => 43, key: 42}) # warned def foo(h={}, key: 42); end; foo({"key" => 43}, key: 42) # OK- 当一个方法不接受关键词,但是调用时传入了关键词,关键词会被视为位置参数,不会有警告抛出。这一行为将会在 Ruby 3 中继续工作。
def foo(opt={}); end; foo( key: 42 ) # OK- 如果方法支持任意参数传入,那么非 Symbol 也会被允许作为关键词参数传入。[功能 #14183]
def foo(**kw); p kw; end; foo("str" => 1) #=> {"str"=>1}-
**nil被允许使用在方法定义中,用来标记方法不接受关键词参数。以关键词参数调用这些方法会抛出 ArgumentError [功能 #14183]
def foo(h, **nil); end; foo(key: 1) # ArgumentError def foo(h, **nil); end; foo(**{key: 1}) # ArgumentError def foo(h, **nil); end; foo("str" => 1) # ArgumentError def foo(h, **nil); end; foo({key: 1}) # OK def foo(h, **nil); end; foo({"str" => 1}) # OK- 将空的关键词分割(splat)传入一个不接受关键词的方法不会继续被当作空 Hash 处理,除非空哈希被作为一个必要参数,并且这种情况会抛出警告。请移除双星号来将 Hash 作为位置参数传入。[功能 #14183]
h = {}; def foo(*a) a end; foo(**h) # [] h = {}; def foo(a) a end; foo(**h) # {} and warning h = {}; def foo(*a) a end; foo(h) # [{}] h = {}; def foo(a) a end; foo(h) # {}如果你希望禁用废弃警告,请使用命令行参数
-W:no-deprecated,或把Warning[:deprecated] = false加入你的代码。其它值得关注的新特性
ary[..3] # identical to ary[0..3] rel.where(sales: ..100)- 新增了
Enumerable#tally,它会计算每个元素出现的次数。
["a", "b", "c", "b"].tally #=> {"a"=>1, "b"=>2, "c"=>1}- 允许在
self上调用私有方法 [功能 #11297] [功能 #16123]
def foo end private :foo self.foo- 新增
Enumerator::Lazy#eager。它会产生一个非懒惰的迭代器。[功能 #15901]
a = %w(foo bar baz) e = a.lazy.map {|x| x.upcase }.map {|x| x + "!" }.eager p e.class #=> Enumerator p e.map {|x| x + "?" } #=> ["FOO!?", "BAR!?", "BAZ!?"]性能改进
-
JIT [实验性质]
- 当优化假设不成功时,JIT 后的代码可能会被重新编译到优化程度较低的代码。
- 当方法(Method)被认为是纯函数(pure)时,会进行方法内联优化。这种优化方法仍是实验性的,许多方法不被认为是纯函数。
-
--jit-min-calls的默认值从 5 调整到 10,000。 -
--jit-max-cache的默认值从 1,000 调整到 100。
Fiber 的缓存策略发生了改变,从而提升了其创建速度。 GH-2224
Symbol#to_s,Module#name,true.to_s,false.to_s和nil.to_s现在始终返回一个冻结(frozen)字符串。返回的字符串始终和给定的对象相等。 [实验性] [功能 #16150]CGI.escapeHTML的性能被提升了。GH-2226Monitor 和 MonitorMixin 的性能被提升了。[功能 #16255]
1.9 中引入的 Per-call-site 方法缓存的性能提升了。缓存的命中率从 89% 提升到了 94%。详见 GH-2583
RubyVM::InstructionSequence#to_binary 方法会编译出二进制,二进制的尺寸被进一步缩小了。[功能 #16163]
其他自 2.6 版本以來显著的变化
-
一些标准库已被更新
-
下面这些库不再是自带 gem,如需使用请安装他们。
- CMath (cmath gem)
- Scanf (scanf gem)
- Shell (shell gem)
- Synchronizer (sync gem)
- ThreadsWait (thwait gem)
- E2MM (e2mmap gem)
profile.rb从标准库中被移除。-
将下面的标准库提升至默认 gems
- 下述 gems 在 rubygems.org 上已发布。
- benchmark
- cgi
- delegate
- getoptlong
- net-pop
- net-smtp
- open3
- pstore
- singleton
- 下述 gems 只在 ruby-core 中出现,没有发布在 rubygems.org 上。
- monitor
- observer
- timeout
- tracer
- uri
- yaml
在方法调用中使用没有代码块的
Proc.new和proc现在会抛出警告。在有代码块的方法调用中使用没有代码块的
lambda会抛出异常。Unicode 和 Emoji 版本从 11.0.0 更新至 12.0.0。[功能 #15321]
更新 Unicode 至 12.1.0 版本,新增对于新年号「令和」U+32FF 的支持。[功能 #15195]
Date.jisx0301、Date#jisx0301和Date.parse支持新的日本年号。[功能 #15742]编译器需要支持 C99 [杂项 #15347] *关于我们使用方言的具体信息请查阅:https://bugs.ruby-lang.org/projects/ruby-trunk/wiki/C99
圣诞快乐,节日快乐,享受使用 Ruby 2.7 编程吧!
Ruby 是什么
Ruby 是最初由 Matz(Yukihiro Matsumoto)于 1993 年开发,现在作为开源软件开发的语言。它可以在多个平台上运行,并在世界各地使用。尤其适合于网站的开发。
-
Ruby 2.7.0 Released at 2019年12月25日
刚交了简体中文的翻译 PR
-
Ruby 2.6 不开 JIT,会比 Ruby 2.5 快吗? at 2019年02月12日
参攷 2.6.0 Release News 的性能提升章节
- 由于移除了对
$SAFE临时赋值的支持,提升Proc#call的速度。[功能 #14318]
通过
lc_fizzbuzz多次使用Proc#call的 benchmark 我们测量到了 1.4 倍性能提升 [漏洞 #10212]。- 提升了当
block是代码块参数时block.call的性能。[功能 #14330]
通过与 Ruby 2.5 中引入的提升代码块传递的性能的方法结合,Ruby 2.6 进一步提升了传递代码块调用时的性能。通过 micro-benchmark 我们观察到了 2.6 倍性能提升。[功能 #14045]
- 引入了瞬态堆 (theap)。 [漏洞 #14858] [功能 #14989]
瞬态堆是用于管理指向特定类(Array、Hash、Object 和 Struct)短生命周期内存对象的堆。例如,创建小而短生命周期的哈希对象的速度提升到了 2 倍快。根据 rdoc benchmark,我们观察到了 6% 到 7% 的性能提升。
- 协程采用了原生实现(
arm32、arm64、ppc64le、win32、win64、x86、amd64)显著提升了 Fiber 的性能。 [功能 #14739]
Fiber.yield与Fiber#resume方法在 64 位 Linux 上提升了 5 倍性能。对于使用 Fiber 密集的程序,约有最高 5% 的性能提升。这些提升都不是 JIT 带来的,Ruby 2.0 以来的每个大版本都有类似的性能优化。
- 由于移除了对
-
如何在 win2003 或 xp 上安装 ruby (>= 2.3) at 2019年01月25日
装个旧版本的 Virtualbox,再在里面跑 Linux(逃
-
这样递减的 sql 怎么写 at 2018年12月31日
这个基本上和财务数据的逻辑是一致的,是一个类似单向 (qu) 链 (kuai) 表 (lian) 的结构。中间有一个节点变化,至少会引起之后所有的数据都必须要重算。最坏的情况是变更第一个值,就不得不触发全表重建。
-
这样递减的 sql 怎么写 at 2018年12月31日
这样的查询适合单独存一张表吧,否则的话,每次做一定是扫全表,时间复杂度是 O(n+m),放在数据库里做好像没有什么意义啊。
-
这样递减的 sql 怎么写 at 2018年12月31日
还是没懂,你要不要列一下计算过程
-
这样递减的 sql 怎么写 at 2018年12月31日
是说 A 的
id是主键,B 的id是 A 的外键。然后 n 是初始值,m 是每次 action 的消耗。d 返回经过每次消耗后的剩余的集合? -
Ruby 2.6 发布后,你可以在 gem 中使用两步验证了。 at 2018年12月27日
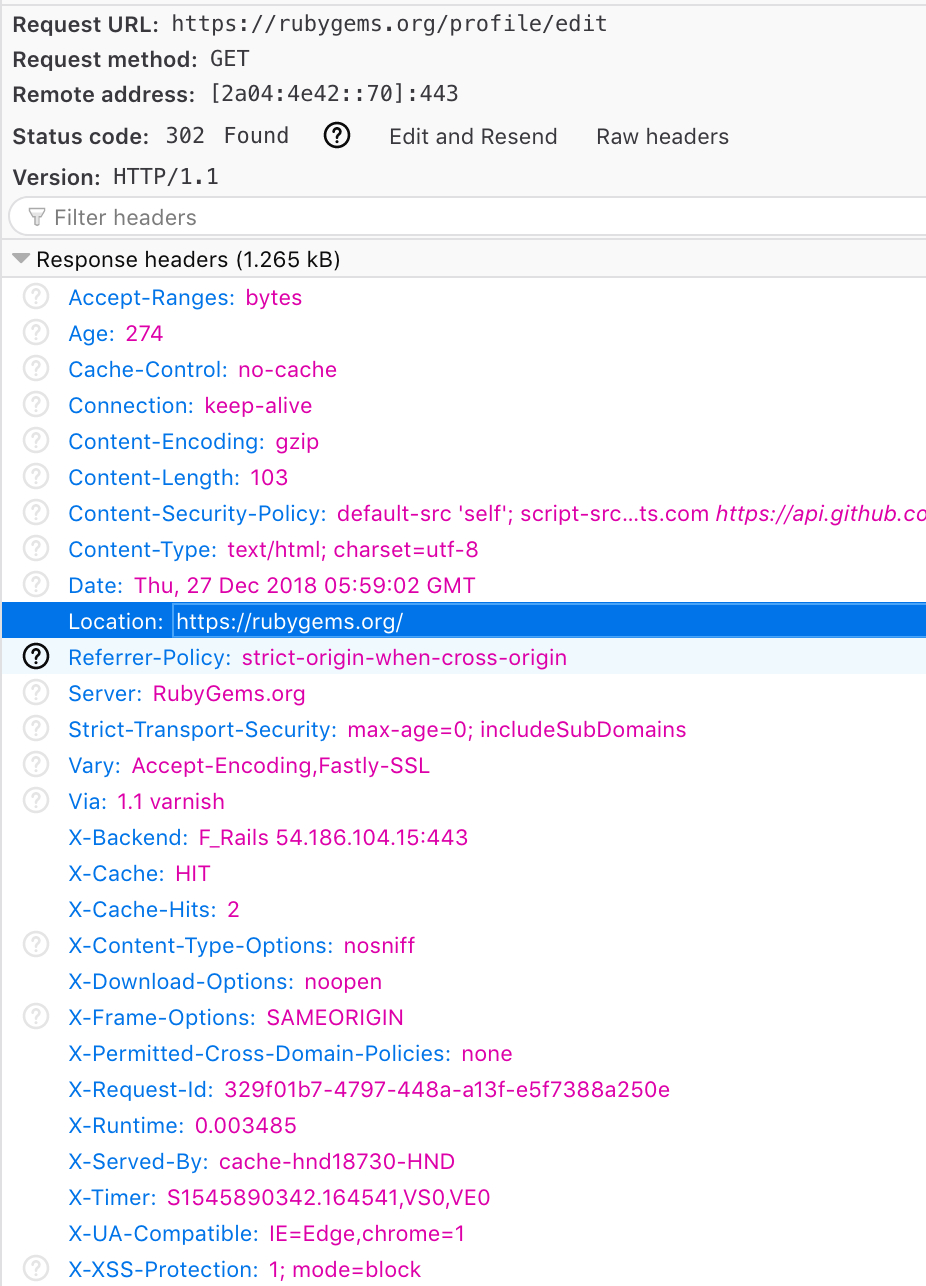
不知道为什么我一访问 Edit Profile 页面就直接 302 回主页了,看来等会要回报 bug。
-
Ruby 2.6.0-rc1 已发布 at 2018年12月19日
在关注 AutoFiber 和 Guild 的发展情况。。。如果 AutoFiber 被实现得很好的话就没什么价值了。如果 AutoFiber 有一些问题,特别是现在可能和 Guild 冲突。而 Midori 可以依赖 Guild 实现更复杂的多核异步模型的话,速度会再快几倍。但现在这俩玩意的状态我也看不太懂,所以也不知道怎么弄了。。。
-
我想问一下,本论坛的帖子已读,未读情况在后台表结构怎么设计? at 2018年12月16日
可以直接看 Homeland 的具体 Schema 实现。
-
关于开源代码的事 at 2018年12月15日
源代码放出来只是让你看,并不能让你用。就像别人放在那里的芒果,你不能寻思是别人不要了吧。
代码是不是开源,需要取决于使用什么授权协议。哪怕是 GPL 的 RedHat 也有卖商业服务的。
如果人家没有设定任何授权协议的话,那就只能默认是 Copyright 私有了。
-
Ruby 2.6.0-rc1 已发布 at 2018年12月15日
中央声称会优化,至于会不会就要看之后有没有相关的 patch 了。
-
关于腾讯 API 拼 URL 的服务 at 2018年12月15日
看了下 Rest Client 的 API,后面还是作为 Hash 参数传进去的,只是因为 Post 前面多了个参数,所以被传错地方了。于是多传一个 nil 进去就好了。
require 'rest-client' require 'json' r = RestClient.post('https://httpbin.org/post', nil, params: {foo: 'bar', baz: 'qux'}) JSON.parse(r.body) # => {"args"=>{"baz"=>"qux", "foo"=>"bar"}, "data"=>"", "files"=>{}, "form"=>{}, "headers"=>{"Accept"=>"*/*", "Accept-Encoding"=>"gzip, deflate", "Connection"=>"close", "Content-Length"=>"0", "Content-Type"=>"application/x-www-form-urlencoded", "Host"=>"httpbin.org", "User-Agent"=>"rest-client/2.0.2 (darwin18.0.0 x86_64) ruby/2.5.3p105"}, "json"=>nil, "origin"=>"0.0.0.0", "url"=>"https://httpbin.org/post?foo=bar&baz=qux"} -
Ruby 2.6.0-rc1 已发布 at 2018年12月15日
Rails 从 JIT 上获益现在所做的还远不够,一方面 Rails 的一个瓶颈是 I/O 模型,这一点不能靠 JIT 来解决。但有一点是可以的,就是 Rails 过深的中间件产生了过深的栈让内存调用非常吃紧。如果我们的 JIT 可以更进一步,在编译过程中对内存进行适当的优化,就可以有效提供其性能。但这一点暂时不是 2.6 的目标,但会是未来 Ruby JIT 的工作重点。
-
Ruby 2.6.0-rc1 已发布 at 2018年12月15日
然而今天要发布 2.6.0-rc2 了。。。