-
[线上][2021年2月9日] RubyTuesday@Clubhouse at 2021年02月09日
把晚上 RubyTuesday 的架构搭出来了,用苹果自带的功能把 iOS 输出作为 macOS 的 Audio Input,再用 Audio Hijack 做劫持,就能同时在 Clubhouse 和其它平台同步播出了。避免了有人没有邀请码或者 iOS 设备的尴尬。
-
用 Ruby 实现飞机自动驾驶仪 at 2021年01月12日
刚发现,这游戏的空气动力学没有模拟地面效应,飞机不会被地面气流推起来,所以我 Retard 后油门一收就直接掉下去了...... 不能完全照着真实飞机写......
-
用 Ruby 实现飞机自动驾驶仪 at 2021年01月12日
更新了一个版本,现在可以自动捕获 3 度下滑道和自动降落了。可以实现完整的起飞、五边飞行、进近和降落流程了。
-
用 Ruby 实现飞机自动驾驶仪 at 2021年01月08日
火箭发射还稍微简单一点,几乎所有控制的 ref_frame 都是轨道;而飞船对接所有 ref_frame 是对接口。而且推重比 > 1,靠推力一定能推上去... 但飞机要靠空气动力,KSP 的空气动力实现的小问题特别多... 不过好像前段时间 MechJeb 也支持飞机控制了,确实是个刚需...
-
Ruby 生态对 Windows 不友好的根本原因 at 2021年01月03日
别说假定 posix 了,windows 上提供了的 posix 操作也和 posix 不完全兼容。
select以及全套WaitFor...()函数的 API 都只能针对 socket 使用,具名和匿名管道都会直接堵塞。就算上了 IOCP 也只能解决具名管道堵塞的问题,还必须把本身的 Reactor 代码写成 Preactor,要大改一大堆逻辑。 -
一篇很详细的 Ruby 3.0 新特性介绍 at 2020年12月26日
确实和官方那篇...很像...
-
生活中的苹果 at 2020年12月25日
如果苹果的软件质量能配得上这工业设计就好了... kqueue 一跑,和 poll 差不多快,还比 poll bug 多是真的让 BSD 党吐血。
-
为 Ruby 3 Fiber 调度器设计事件库 Evt at 2020年12月24日
Sidekiq 有点复杂,要想把默认的线程模型拆掉不容易。
-
为 Ruby 3 Fiber 调度器设计事件库 Evt at 2020年12月24日
这个 io read 有 bug,我尝试用了 prep_read 和 prep_readv 这两种不同的函数,都没法确保直接读到,还在研究为什么。
-
为 Ruby 3 Fiber 调度器设计事件库 Evt at 2020年12月23日
MySQL gem 默认有异步支持,但是现在的比如 ActiveRecord 没有正确调用,因为这个接口还没正式上。
-
为 Ruby 3 Fiber 调度器设计事件库 Evt at 2020年12月23日
现在很多 C 插件没有这个加成可能比纯 Ruby 跑得还慢。但我自己那几个是在 C 里写了调度器的兼容支持,所以还能更快一点。
-
为 Ruby 3 Fiber 调度器设计事件库 Evt at 2020年12月23日
重新实现了符合 Ruby 3 接口的 Redis 异步。
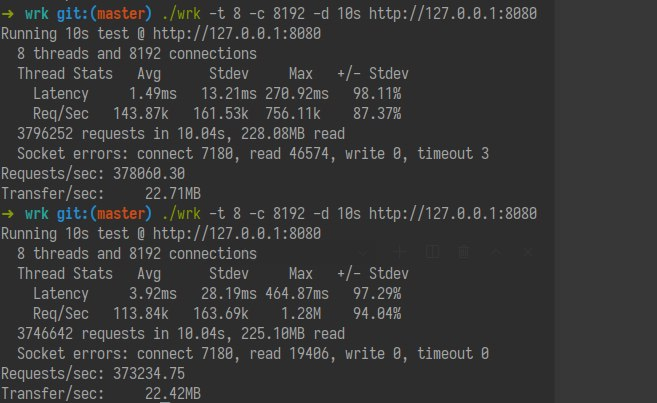
Ruby 3 + Evt Scheduler + midori + midori-contrib patched Redis

378060 QPS Single Thread
由于 Redis 拖慢了我们 Ruby 程序,连 CPU 占用都跑不到 100% 了。也不会因为堆越来越大而忽然快忽然慢了。
-
为 Ruby 3 Fiber 调度器设计事件库 Evt at 2020年12月23日
修复了一些问题,更新了新的 benchmark
OS CPU Memory Backend req/s Linux Ryzen 2700x 64GB epoll 2035742.59 Linux Ryzen 2700x 64GB io_uring require fixes Linux Ryzen 2700x 64GB IO.select (using poll) 1837640.54 macOS i7-6820HQ 16GB kqueue 257821.78 macOS i7-6820HQ 16GB IO.select (using poll) 338392.12 -
为 Ruby 3 Fiber 调度器设计事件库 Evt at 2020年12月23日
Windows 上的 select 不能同时监听超过 1024 个文件描述符。只能保证基本能用,压力上去还是顶不住的。然后这个 bug 我单独做了一些额外处理。刚刚更新。
-
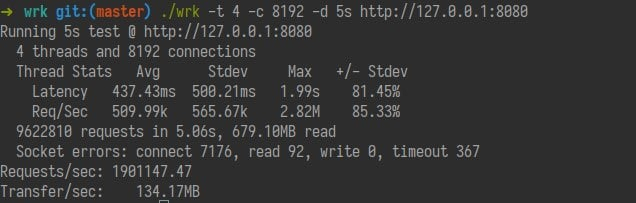
为 Ruby 3 Fiber 调度器设计事件库 Evt at 2020年12月23日
最终跑出了 1,900,000k req/s 在 Linux 上。 10s 后我 64GB 内存用光开始爆 "Fiber unable to allocate memory" 错误了。
-
为 Ruby 3 Fiber 调度器设计事件库 Evt at 2020年12月23日
19 日:跑了 6k req/s
21 日:跑了 60k req/s
22 日:跑了 627k req/s
一天多一个零可还行...
-
为 Ruby 3 Fiber 调度器设计事件库 Evt at 2020年12月22日
这个只跑到 50k 的一大原因是这个 parser 有问题,导致错误很多,而 wrk 对错误非常敏感。我花了几个小时把我的 midori 重新改造成使用 Ruby 3 Scheduler 的项目。https://github.com/midori-rb/midori.rb
结果这性能更恐怖了:
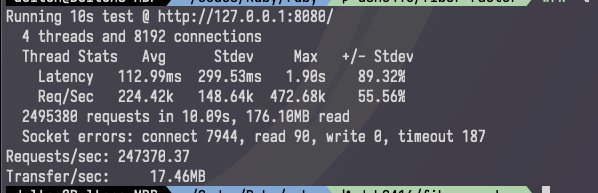
这已经能逼近 Crystal 了... 如果算上多进程可以直接逼平 Go...
-
为 Ruby 3 Fiber 调度器设计事件库 Evt at 2020年12月22日
好得惊人,我之前估计大概能跑过 10k 大关就谢天谢地了,结果一跑跑出 41k/s,第二天优化了一下突破 50k/s 了
-
Install Ruby on Apple Silicon at 2020年11月28日
之前说 Ruby 3 JIT 性能不好的一个主要问题是 x64 上 L1i 命中很低。感觉上来说 M1 同时加大了 L1i 的大小和分页大小,可能 JIT 的提升会更大一点,但实际上好像带来的提升很小,甚至没有。一种可能是因为 RISC 生成的指令数量也比较多两者抵消了,还有一种可能就是这点大小增加效果不明显。
但反过来来看这个堆 ALU 单元,堆发射数量带来的单核 IPC 提升堆解释型语言的提升还是比较明显的。
但最好还是跑个 Sinatra 的测试,因为 Sinatra L1i 命中问题比 optcarrot JIT 严重很多,需要研究看看这个问题在 M1 上是表现得差不多还是变得更严重了。
-
M1 芯片 Mac 可以开发 Rails 吗? at 2020年11月24日
ffi 的那个问题已经有个 PR 了,原先没有 arm64-darwin 的 type 描述,实在不行可以上那个 fork 过的版本。
msgpack 这个怪怪的,因为 msgpack 有给瘦 gem,按道理 bundle 应该是本机打出来的,不知道怎么会缺 arch。感觉是苹果编译的解释器有点问题。
-
M1 芯片 Mac 可以开发 Rails 吗? at 2020年11月23日
我没有 M1 的机器。
但是 ARM Linux 上编译 ruby 是没有问题的,M1 上的 macOS 的 LLVM 应该也是没有问题的。而且 macOS 还有自带的 ruby 解释器,四舍五入一下我倾向于认为没有什么问题。
-
.NET 5 速度太快了,MVC 编译速度比 Golang 的还快 at 2020年11月20日
我对 .NET 5 最期待的是 Unity 什么时候能有意愿从 Mono 上迁移到 CoreCLR 了,可以有效改善一下那个烂 GC 在很多游戏中造成的奇怪卡顿。然后 Web 开发可能得看看 Blazor 框架的发展情况。
-
Ractor 下多线程 Ruby 程序指南 at 2020年11月17日
会有这个现象,而且实际情况非常复杂。通常情况下每个核心有自己的 L1 L2 缓存,同一个 CCX/NUMA 节点会共享 L3 缓存。一个线程被操作系统从一个核调度到另外一个核心执行的时候,可能更容易遇到缓存失效的问题。但操作系统会优先调度到同一个 NUMA 节点上,同时当这种计算密集场景出现的时候,线程的 nice 值会被降低,系统会让线程多执行一会再去执行别的东西。手动绑定会不会得到改善,其实是有疑问的。
-
Ruby 3 Fiber 变化前瞻 at 2020年11月17日
mysql2 的 C 实现提供阻塞和非阻塞两种模式,后者可以在 Ruby 上进一步接入 Fiber。但通常 Ruby 上用的是前者。而我们可以用 Fiber 和非阻塞模式封装出一个 I/O 性能更好的,但是使用方法和前者一样的 API。要看 wrapper 的实现社区具体想怎么跟进了。
-
Ruby 3 Fiber 变化前瞻 at 2020年11月16日
Promise / async / await 根本就是 Fiber Scheduler 语义的等价写法。Fiber Scheduler 要做的就是自动 consume 和 transfer。只有在脱离 Fiber Scheduler 裸写 Fiber 的 Ruby 2.x 里才需要手动 consume 和 transfer。
Promise 在 JavaScript 里只是为了解决的 callback hell 的替代,如果要用 Promise 只需要加个类就行。这步甚至和调度没有任何关系:
class Promise def initialize(&callback) @callback = callback end def then(&resolve) @callback.call(resolve) end end而如果要有全局的 async await 关键字支持,在有 fiber scheduler 的情况下,transfer 也已经自动完成了,只要把 fiber chain 起来就行了:
## # Meta-programming Kernel for Syntactic Sugars module Kernel # Make fiber as async chain # @param [Fiber] fiber root of async chain def async_fiber(fiber) chain = proc do |result| next unless result.is_a? Promise result.then do |val| chain.call(fiber.resume(val)) end end chain.call(fiber.resume) end # Define an async method # @param [Symbol] method method name # @yield async method # @example # async :hello do # puts 'Hello' # end def async(method) define_singleton_method method do |*args| async_fiber(Fiber.new {yield(*args)}) end end # Block the I/O to wait for async method response # @param [Promise] promise promise method # @example # result = await SQL.query('SELECT * FROM hello') def await(promise) result = Fiber.yield promise if result.is_a? PromiseException raise result.payload end result end end这点上根本不需要 Ruby MRI 解释器做额外的支持。
-
Ruby MRI 没有走 Rubinius 的 VM 路线是核心团队技术能力有限导致的吗 at 2020年10月30日
没懂,现在的 MRI VM 确实是 Ruby -> ByteCode -> C Runtime 这样的解释过程。这和 JVM/JavaScript 的 VM 架构不是差不多吗?相比之下 JavaScript JIT 介入的位置还更早,感觉更不纯 VM 一点才对吧(?)
-
尝试使用 Ruby 3 调度器 at 2020年10月18日
Goroutine 的 newm 和 new 是不一样的。newm 是启用系统的 Thread,而 new 是 (newproc) 对于 Fiber (Continuation) 的封装。new (newproc) 会在一些情况下触发 newm。这就是「Fiber 的内部协作式调度,再和整体的 Thread 一起做出来的封装」而不单纯是系统 Thread。
随便看个 https://golang.org/src/runtime/asm_amd64.s 252 行,就是内部 gosave,和 Fiber 实现完全一样。如果直接调用系统 Thread 自然就不用这东西了。
-
尝试使用 Ruby 3 调度器 at 2020年09月27日
你把 parallelism 并行性和 concurrency 并发性的概念搞混了。这是两个完全不同的概念。GIL 能不能 Parallel,和能不能做到 Concurrent 是两个完全不同的概念。
如果一个应用是 I/O boundary,靠多核来解决问题是非常不恰当的。因为多核依赖操作系统的 Threading 线程调度,比在程序内进行上下文切换反而是更慢的。Windows 3.0、Mac OS 9 后操作系统摒弃协作式调度的本质是为了优化使用上的体验,单从性能角度出发实际上是在变得更低的。
至于你说“还不如学 go 封装一下 thread”,事实上 Goroutine 的 Thread 并不是真正的 Thread 的封装并不能因为看起来暴露了一个类似 Thread 的接口,就认为这是 Thread。只要你熟悉一下 Goroutine 的实现就会发现,其也是如 Fiber 的内部协作式调度,再和整体的 Thread 一起做出来的封装,是多线程多协程切换的实现。
协作式调度之所以快的原因也很简单,如果你检查 Linux 线程实现的汇编的话你就会知道抢占调度有多复杂,不但需要一个 syscall 本身的开销,还需要计算前一个线程使用的 cpu time,还需要处理其提前返回的原因,维护 fair 值的红黑树,设置 CPU 中断,然后才能切换。而协作调度单纯只要找到下一个可用的协程,然后切换几个 CPU 上的寄存器即可。与其说是和线程抢 cpu time,不如说从操作系统的复杂调度机制中解放了更多的 cpu time。
不止是 Goroutine,任何高效的 Web 服务器实现,比如 nginx 之类都有内置的上下文切换来提高 I/O 效率,其和 Fiber 是完全一样的原理。然后 nginx 将其再和多线程的模型进行结合,这也是可以在之后引入 Guild 后操作的。调度非阻塞连接是非常复杂的,如果单纯一个 nonblocking 关键字就能做到 nonblocking 的话,又何来不同的操作系统 API 的异步性能差异呢?如果你觉得加入 nonblocking 后只要遍历所有的请求,不但会导致 cpu 性能的极大浪费,最终也只能实现和图中 IO.select 差不多的性能。当然,如果你用 C 语言简单写一个基于 select 的 nonblock 服务器,也可以轻松跑个 10k qps,这是因为其内存占用非常小和简单,操作系统切换代价更小,从而让你觉得调度本身不会影响 qps 的错觉。而如果你正确在 C 语言上实现一个 epoll 的最简单的代码,那可就是十万甚至百万级别的并发了。这也是为什么我们在做性能分析的时候,要控制变量。使用不科学的条件设计出来的实验,其结果必然也是不科学的。
在 Linux 最新版本上,甚至进一步引入一个 io_uring 来进一步优化这一问题。因为这不光会涉及对 nonblocking 请求监听的性能,甚至连操作系统内部对 I/O 缓冲区的处理,甚至用户态内存拷贝的效率都会影响这个过程的性能。
至于一个 I/O 往 另一个 I/O write 1GB 的数据,既不涉及并发也不涉及并行,当然是阻塞操作的开销更小,因为非阻塞操作引入了额外的 overhead。但实际上的 workload 都是同一个程序内多个 I/O 的调度。只有涉及了“调度”,我们才需要“调度器”,而单纯基于操作系统线程的调度太慢了,这就是我们要自己进一步实现的原因。
Ruby 3 Fiber Scheduler 确实是一个魔术。基于手写也是可以实现类似的效果的。而且需要特别注意的是,如果我们的直接场景是 Web 服务器,我们完全可以认为 API 之间的状态是隔离的,状态是由数据库来维护的。所以我们可以在 Fiber 外面再套一层 fork 就可以进一步利用上多核。这么做的有比如 socketry/falcon,qps 可以轻松上十万。puma 的多进程模型已经不受 GIL 影响了,只要内存够,想把 cpu time 跑满也是很轻轻松松的事情,那么为什么 falcon 又会比多核多进程模型的 puma 更是快上了十几倍呢?因为 Fiber 调度比操作系统调度 Thread 更节省 cpu time。同样的 cpu time,Fiber 调度做的有用工作比较多,而 puma 只是在浪费它占用的那么多 cpu time 而已。
-
一个前端为啥对 Ruby 很亲和,我突然明白了 at 2020年09月20日
WeakMap是围绕 GC 的设计,Object#freeze是动态类型语言对final关键字的补偿设计。 这个要追溯的话,应该还是要追溯到 Lisp。无论是 Ruby 还是 JavaScript 都是深受 Lisp 启发的语言。 而且 Lisp + OOP 的话第一反应就是 CLOS 了。确实 Lisp 衍生语言的特性大同小异的。 -
拯救老婆 —— MacBook Pro 维修计划 at 2020年08月12日
夸张。。。夸张手法。。。