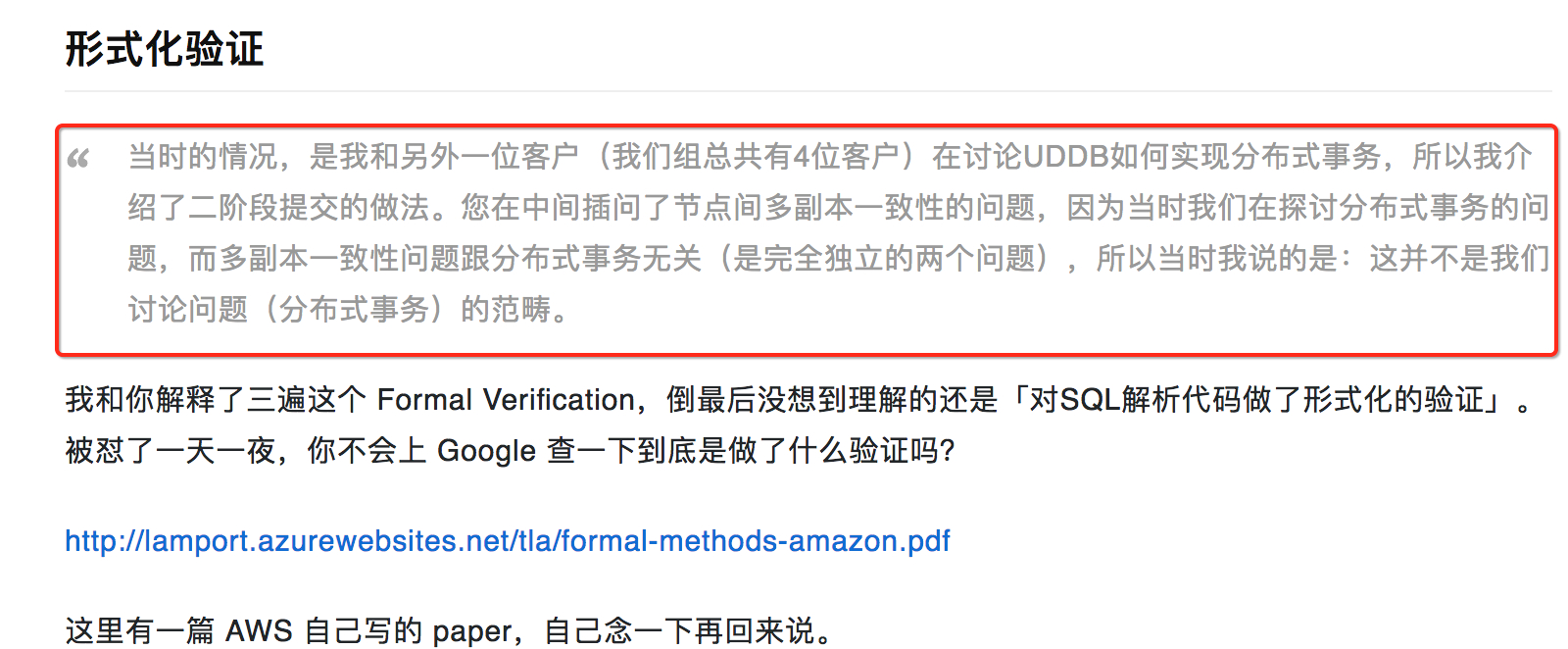
云服务 UCloud 已经不是 UCloud,而你大爷还是你大爷 [2017/12/25 更新]
引
距离我最早开始用 UCloud,已经过去了 3 年多了。如果算上知道 UCloud 那就更早了。像这样起步早期的云厂商,不得不说是非常艰辛的,特别是在那个 OpenStack 还是非常不成熟的年代,要么选择大幅改动二次开发 OpenStack,否则就要选择自研。如果是阿里这样资金允许其投入的公司,从一上来就目标定在对标 Amazon Web Services 上是可能的。而像 UCloud 这样的公司,通过自研走出的道路可以说是非常艰辛的。
让 UCloud 在当时留在公众视野中最深刻的一件事就是其优质的客户服务。当中小手游厂商的工单在阿里云被放置 play 的时候,UCloud 良好的售后抢夺了大量市场,最终站稳了脚跟。然而在今天,公有云的开荒期已过。公有云厂商一方面提供私有云部署,另一方面开始提供进一步的服务以丰富产品开拓新市场。例如托管的云数据库、消息队列、缓存等等,并且在这些问题上进行进一步的开发,使其在云平台上拥有更大的竞争力。
这一步 Amazon 的步子迈得很大,阿里云也紧随其后。前几天的时候,接到一个 UCloud 的电话,问我有没有兴趣参加他们的用户开放日「数据库专场」。这不去不知道,一去吓一跳。我现在甚至怀疑,UCloud 良好的售后甚至不一定是好事,他们对客户的重视,已经远超过了对产品本身的重视。这已经落入了一个做企业服务的公司常常遇到的问题。
为什么要这么说,我一定要说一下今天这个 UCloud 的开放日。
UDDB
今天 UCloud 开发日的主题是数据库,主角是 UCloud 自研的分布式数据库 UDDB,UDDB 的架构相当简单,其原理就是 MySQL Shard,每一个 Shard 单独做 Replication,通过 Stateless 的 Middleware Cluster 进行 reduce 操作并作为入口。这个产品的完成度非常低,Sharding 需要手动设计,跨表查询目前支持性有问题。
但无论如何,开发一个分布式系统是相当难的,要解决的问题有很多。我问了一些问题,得到的答案只能用匪夷所思来形容:
我:Sharding 需要手动指定,是不是基于 ORM 做 schema-migration 的需要额外开发插件?
讲师:Migration 是什么?
我:Migration 就是 ......
讲师:我们没听到过客户用这种东西的。
(好家伙,原来 UCloud 根本就没把 Ruby China 当回事。)
我:怎么保证分布式一致性?
讲师:我们在中间件上做了二阶段提交,需要确认单个机器返回了成功才行。
我:二阶段提交并不能完全解决你的问题,你的单个实例本身是一个 MySQL Replication,如果返回成功的瞬间主机宕机,不能保证备机成功了。
讲师:MySQL 自己会解决这一问题。
(蛤?如果你的 MySQL 没有用 sync 模式,显然是不能解决这一问题的。)
我:你们如何测试你们的系统和 MySQL 的兼容性?
讲师:我们做了一些自动化测试。
我:你们是说通过了 MySQL 自己的测试集还是怎么?
讲师:是的。
我:MySQL 自己的测试集并不能保证分布式本身的测试。比如 AWS 和 TiDB 他们做了……的测试,发现了原先没有发现到的一致性上的……的问题。
讲师:TiDB 那是追求新鲜事物,我们还是比较踏实的。
(分布式测试都不完备还叫踏实,你牛逼)
NewSQL
稍作休息后进入了第二个阶段,这个阶段彻底点燃了我的怒点。在这一阶段,讲师开始介绍数据库的发展历史,当讲到 NewSQL 的时候,用的说法是,因为发现了 NoSQL 的各种事务性和业务上的问题,数据库的发展又回到了 SQL。
如果这一点单指 SQL 的接口,那我也就认了。但 NewSQL 和过去 SQL 的引擎差异巨大,以此来标榜自己 Sharding 一下的 MySQL 也能和 NewSQL 媲美,那完全就是鬼扯。当我还没缓过神来的时候,讲师说:
像 TiDB 现在也号称自己要做 HTAP 而不是 OLTP,所以其确实是不满足大家常见电商或者金融的 OLTP 需求的。我勒个去,听到这里我是彻底听不下去了,然后发生了一下一段对话。
我:等一下,你老实告诉我,你到底是技术人员还是销售,不要装。
讲师:我…我当然是做技术的。
我:那你现在说 HTAP 不满足 OLTP 需求,你知道 HTAP OLTP OLAP 的关系是什么吗?
讲师:是什么?
(还能把问题扔回给我)
我:HTAP 的目的是要做 OLTP 和 OLAP 的超集,同时满足这两者的需求。
讲师:同时做这两者,肯定不能同时满足这两者,肯定是有侧重的嘛?
我:...... OLTP 和 OLAP 本来就不是水火不容的东西,他们两者的区别才是侧重,HTAP 要还是侧重这不是自相矛盾吗?
讲师:那你说说什么电商系统用 TiDB 的?
(我就举了几个大公司在用 TiDB 的例子)
讲师:你也不能只从这个角度来谈 NewSQL。
我:但你现在说的完全都是在泛泛而谈,或者你给我举一个例子说这个 TiDB 相对 MySQL Replication 的系统在 OLTP 上到底有什么「技术问题」。
讲师:TiDB 的问题是 …… 用户少。
(你是想说你 UDDB 用户多吗?)
道德问题
听完这个「用户少」是「技术问题」后,我一个字都没再听下去就摔门走了。第一次参加技术会议能弄得那么生气的。名不副实你在商务上行得通,在技术上是行不通的这不是个常识吗?
如果说你要卖 UDDB,我自然不拦着你。UDDB 确实可以解决一些用户的问题。如果你今天开一个产品分享会,邀请一些传统企业的技术来,讲一下你们的技术,忽悠一下卖出去两份很合理,我一百个支持。但今天非要把产品吹牛上升到技术分享,弄几个销售冒充数据库专家,肆意地诋毁其他产品,这已经不是我能忍耐的地步了。
这个题目如果放在容灾和扩容上吹吹牛,也许还行。放在分布式那么大的一个题目下讨论,自然要通过胡编乱造才能突出自己的产品。还能讲出「用户少」是「技术问题」这种幹话,这世界上恐怕我也就认识 UCloud 这一家了。
公有云的开荒期已过,厂商都在丰富自己的服务。如果 AWS 能做一个 90 分的产品,那么阿里云能做一个 85 分的产品,夸成 90 分。
面对竞争对手一如既往的强势,今天的 UCloud 已经完全不是我以前认识的那个 UCloud。今天 UCloud 做一个 60 分刚及格的产品就来用这种销售的方法吹成 100 分,这不是技术问题。
这是道德问题。
结
UCloud 在圣诞卡里写了:
希望你在活动中有所收获。
我今天最大的收获就是:
不要 浪费你任何一分钟去听一个销售驱动的公司讲技术。
圣诞更新
今天这圣诞夜过得非常有意思,我中午刚睡醒就连着来了两通 UCloud 客户服务的电话来给我解释和道歉这事情。又收到了很多微博私信,咨询我 TiDB 的问题。莫名其妙地兼职了一回 PingCAP 员工。这一波还是同时 PR 两个公司我也是没想到。之后又发现这文章在不少 IaaS 公司里都在传阅,那我有必要来更新一下之后的情况。
删帖
今天还被问了几次删帖的问题。删帖的问题不是不能删,而是删帖其实在造成更大的危害。造成一个事实性的伤害,一个问题,不来解决,而是来解决提出的问题,甚至是解决提出问题的人。如果 UCloud 必须要用这种方法,我相信这也和某些不宜点名的流氓大厂不远了。而且帖子可以被删,但帖子给人们脑中留下的印象永远不会删。如果问题不被解释,连这种文章都要被「公关」,那么今天读过文章的用户和友商们对于 UCloud 只会留下不好的印象,而且互联网是无法被赶尽杀绝的,明天友商上 Web Archive 把文章找出来给客户看,绝对不是好事。既然这件事 UCloud 选择来解释这个问题,那么解释清问题,自然是一个更好的选择。
一些建议
这个问题如果跳到一个更长远的角度来考虑,我确实想对 UCloud,或者国内一些技术公司做类似的事情提一些建议。希望这样的事情不要重演。
首先,就是闭门会。闭门会的意义和面对大量用户的技术分享是有明显区别的。闭门会的形式无外乎两种,做传销式的洗脑,或者针对用户需求解决具体问题。UCloud 试图想做后面那种,于是把它分成五人一个小组的闭门小会。但问题是,定的题目「分布式数据库」绝对不是一个针对用户需求解决具体问题的小问题,甚至是一个非常复杂而抽象的大问题。用户的需求区别可能极大,是讲师无法讲述的,这毫无例外地引发了我认为这个闭门会实际上是想做成传销式的洗脑的会议,更引发另一个问题。也就是对讲师水平的控制的重要性。
在一个公司里找出几个实力绝对过硬的人开多个小会来应付客户各种提问是非常难的,如果被追问,很可能就会引发这样的悲剧。像今天的讲师,对于他所要谈论的「分布式数据库」这样的大题目,只懂一二,甚至连 UDDB 自己可能遇到的一些问题都不自知,这是非常可怕的。UDDB 这个产品能不能用,当然还是什么样类型的需求用什么样的产品。如果对于 NewSQL 这样的新鲜事物还持保守态度,且单实例的 MySQL 无法满足需求,过渡性地作为一个选项也未尝不可,至少在某些公司里确实是这么实践的。做一个 60 分的产品是因为觉得 60 分就足够了是一回事,但如果是只做得出一个 60 分的产品就是问题了。把这样的产品放在公开场合谈论,被 challenge 是分内的事情,如果找个台阶下自然也是合理的。但如果认识不到自己考了 60 分,还要把班级里的学霸批判一番,说他们是追求新鲜事物,自己考 60 分是比较踏实。那就是真的引爆炸药桶的事情。
这样的事既是偶然,也是对演讲品质控制不够重视的必然。
回归问题
据我所知,我当时遇到的讲师在 UCloud 工作的时间也不算短,但有一个非常矛盾的地方在于,PingCAP 本身也是 UCloud 的合作商,TiDB 也在 UCloud 上销售。如果说肆意地诋毁 NewSQL 以及 NewSQL 产品,确实也不太可能是公司授权进行的行为。
如果回归问题的本身,暴露出至少这位 UDDB 的开发对于数据库发展,特别是数据库新技术的认识非常有限。一方面也有护短的思考存在,毕竟是自己做的产品,在被 challenge 到一个非常危险的地步的时候,讲幹话,可能是一种本能行为。但事实上,员工对外 PR 代表了公司的形象,因此造成了对 UCloud 的负面影响,对于公司确实是一个非常倒霉的一个行为,当然我也相信这也不是 UCloud 组织这次活动想要达到的目的。
既然 UCloud 愿意对上述的这些问题作出道歉和保证,我想有这样态度处理这个问题的,至少从骨子里,不是主动希望把自己公司做向一个纯销售烂产品的公司的。当然,承诺是一回事,至于到底只是用户公关的权宜之策,还是 UCloud 以后能贯彻这个承诺,那就要看 UCloud 之后到底做出来的行为和他们说的是不是一致了。