-
HHKB bt 总是疯狂重复输入最后一次敲击 at 2020年08月05日
穷...贵了好几百呢,我对静音也没啥需求。
-
HHKB bt 总是疯狂重复输入最后一次敲击 at 2020年08月05日
6.18 买的白色蓝牙有刻,一毛一样的问题。遇上过两次重复删除键,异常蛋疼。
-
人生第一个过 5K Star 的 项目 x-spreadsheet (类似 excel) 感谢各位大佬的支持 at 2019年04月02日
做 spreadsheet,我觉得最难的一点在于解析表达式 (对于没有编译原理基础的人来说),如何避免因为循环依赖导致的栈溢出。比如说 A1 的值是
=A1+A2,A2 的值是=A1+A2。这个库也没解决这个问题: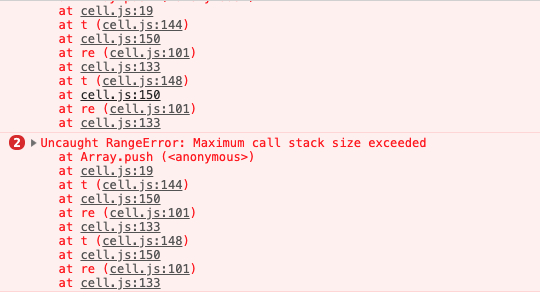
不知道有没有简单的思路,或者轻便的第三方库来解决这个问题。
-
在 Rails 中使用 PostgreSQL 的全文搜索功能搜索百万条记录的表的正确姿势 at 2019年02月27日
@hooopo 好的,谢谢了,我也看到了你发到一篇关于 PostgreSQL 全文搜索的贴子 (https://ruby-china.org/topics/38153),我再研究一下。
-
在 Rails 中使用 PostgreSQL 的全文搜索功能搜索百万条记录的表的正确姿势 at 2019年02月26日
@hooopo 谢谢!以下是 explain: (实际项目中表是 episodes)
- 记录总数:774825
[1] pry(main)> Episode.count (307.6ms) SELECT COUNT(*) FROM "episodes" => 774825- seach_by_title
[1] pry(main)> Episode.search_by_title('adventure').explain Episode Load (85.9ms) SELECT "episodes".* FROM "episodes" INNER JOIN (SELECT "episodes"."id" AS pg_search_id, (ts_rank(("episodes"."tsv_title"), (to_tsquery('simple', ''' ' || 'adventure' || ' ''' || ':*')), 2)) AS rank FROM "episodes" WHERE ((("episodes"."tsv_title") @@ (to_tsquery('simple', ''' ' || 'adventure' || ' ''' || ':*'))))) AS pg_search_a8ace1a76c218f36a59a58 ON "episodes"."id" = pg_search_a8ace1a76c218f36a59a58.pg_search_id ORDER BY pg_search_a8ace1a76c218f36a59a58.rank DESC, "episodes"."id" ASC => EXPLAIN for: SELECT "episodes".* FROM "episodes" INNER JOIN (SELECT "episodes"."id" AS pg_search_id, (ts_rank(("episodes"."tsv_title"), (to_tsquery('simple', ''' ' || 'adventure' || ' ''' || ':*')), 2)) AS rank FROM "episodes" WHERE ((("episodes"."tsv_title") @@ (to_tsquery('simple', ''' ' || 'adventure' || ' ''' || ':*'))))) AS pg_search_a8ace1a76c218f36a59a58 ON "episodes"."id" = pg_search_a8ace1a76c218f36a59a58.pg_search_id ORDER BY pg_search_a8ace1a76c218f36a59a58.rank DESC, "episodes"."id" ASC QUERY PLAN --------------------------------------------------------------------------------------------------------- Sort (cost=4050.16..4051.01 rows=341 width=1513) Sort Key: (ts_rank(episodes_1.tsv_title, '''adventure'':*'::tsquery, 2)) DESC, episodes.id -> Nested Loop (cost=34.96..4035.81 rows=341 width=1513) -> Bitmap Heap Scan on episodes episodes_1 (cost=34.54..1306.26 rows=327 width=103) Recheck Cond: (tsv_title @@ '''adventure'':*'::tsquery) -> Bitmap Index Scan on index_episodes_on_tsv_title (cost=0.00..34.45 rows=327 width=0) Index Cond: (tsv_title @@ '''adventure'':*'::tsquery) -> Index Scan using episodes_pkey on episodes (cost=0.42..8.34 rows=1 width=1509) Index Cond: (id = episodes_1.id) (9 rows)- search_by_desc
[2] pry(main)> Episode.search_by_desc('adventure').explain Episode Load (2663.1ms) SELECT "episodes".* FROM "episodes" INNER JOIN (SELECT "episodes"."id" AS pg_search_id, (ts_rank(("episodes"."tsv_description"), (to_tsquery('simple', ''' ' || 'adventure' || ' ''' || ':*')), 2)) AS rank FROM "episodes" WHERE ((("episodes"."tsv_description") @@ (to_tsquery('simple', ''' ' || 'adventure' || ' ''' || ':*'))))) AS pg_search_a8ace1a76c218f36a59a58 ON "episodes"."id" = pg_search_a8ace1a76c218f36a59a58.pg_search_id ORDER BY pg_search_a8ace1a76c218f36a59a58.rank DESC, "episodes"."id" ASC => EXPLAIN for: SELECT "episodes".* FROM "episodes" INNER JOIN (SELECT "episodes"."id" AS pg_search_id, (ts_rank(("episodes"."tsv_description"), (to_tsquery('simple', ''' ' || 'adventure' || ' ''' || ':*')), 2)) AS rank FROM "episodes" WHERE ((("episodes"."tsv_description") @@ (to_tsquery('simple', ''' ' || 'adventure' || ' ''' || ':*'))))) AS pg_search_a8ace1a76c218f36a59a58 ON "episodes"."id" = pg_search_a8ace1a76c218f36a59a58.pg_search_id ORDER BY pg_search_a8ace1a76c218f36a59a58.rank DESC, "episodes"."id" ASC QUERY PLAN ---------------------------------------------------------------------------------------------------------------------- Gather Merge (cost=24792.34..24997.50 rows=1784 width=1513) Workers Planned: 1 -> Sort (cost=23792.33..23796.79 rows=1784 width=1513) Sort Key: (ts_rank(episodes_1.tsv_description, '''adventure'':*'::tsquery, 2)) DESC, episodes.id -> Nested Loop (cost=78.94..23695.99 rows=1784 width=1513) -> Parallel Bitmap Heap Scan on episodes episodes_1 (cost=78.51..10578.73 rows=1709 width=201) Recheck Cond: (tsv_description @@ '''adventure'':*'::tsquery) -> Bitmap Index Scan on index_episodes_on_tsv_description (cost=0.00..77.79 rows=2905 width=0) Index Cond: (tsv_description @@ '''adventure'':*'::tsquery) -> Index Scan using episodes_pkey on episodes (cost=0.42..7.67 rows=1 width=1509) Index Cond: (id = episodes_1.id) (11 rows)- search_by_title_desc
[3] pry(main)> Episode.search_by_title_desc('adventure').explain Episode Load (10290.7ms) SELECT "episodes".* FROM "episodes" INNER JOIN (SELECT "episodes"."id" AS pg_search_id, (ts_rank(("episodes"."tsv_title" || "episodes"."tsv_description"), (to_tsquery('simple', ''' ' || 'adventure' || ' ''' || ':*')), 2)) AS rank FROM "episodes" WHERE ((("episodes"."tsv_title" || "episodes"."tsv_description") @@ (to_tsquery('simple', ''' ' || 'adventure' || ' ''' || ':*'))))) AS pg_search_a8ace1a76c218f36a59a58 ON "episodes"."id" = pg_search_a8ace1a76c218f36a59a58.pg_search_id ORDER BY pg_search_a8ace1a76c218f36a59a58.rank DESC, "episodes"."id" ASC => EXPLAIN for: SELECT "episodes".* FROM "episodes" INNER JOIN (SELECT "episodes"."id" AS pg_search_id, (ts_rank(("episodes"."tsv_title" || "episodes"."tsv_description"), (to_tsquery('simple', ''' ' || 'adventure' || ' ''' || ':*')), 2)) AS rank FROM "episodes" WHERE ((("episodes"."tsv_title" || "episodes"."tsv_description") @@ (to_tsquery('simple', ''' ' || 'adventure' || ' ''' || ':*'))))) AS pg_search_a8ace1a76c218f36a59a58 ON "episodes"."id" = pg_search_a8ace1a76c218f36a59a58.pg_search_id ORDER BY pg_search_a8ace1a76c218f36a59a58.rank DESC, "episodes"."id" ASC QUERY PLAN ------------------------------------------------------------------------------------------------------------------------------------ Gather Merge (cost=242738.45..244331.76 rows=13656 width=1513) Workers Planned: 2 -> Sort (cost=241738.43..241755.50 rows=6828 width=1513) Sort Key: (ts_rank((episodes_1.tsv_title || episodes_1.tsv_description), '''adventure'':*'::tsquery, 2)) DESC, episodes.id -> Nested Loop (cost=0.42..236799.08 rows=6828 width=1513) -> Parallel Seq Scan on episodes episodes_1 (cost=0.00..198085.56 rows=6542 width=300) Filter: ((tsv_title || tsv_description) @@ '''adventure'':*'::tsquery) -> Index Scan using episodes_pkey on episodes (cost=0.42..5.91 rows=1 width=1509) Index Cond: (id = episodes_1.id) (9 rows) -
gatsby 开一个博客很容易 at 2019年01月25日
之前不了解 GraphQL 的看这部分可能费点劲,如果之前了解过这部分都可以跳过了。
-
各位大神,是我的姿势不正确吗? at 2019年01月23日
涨知识了
-
各位大神,是我的姿势不正确吗? at 2019年01月23日
的确奇芭:
[23] pry(main)> Date.parse("heh") ArgumentError: invalid date from (pry):23:in `parse' [25] pry(main)> Date.parse(" fc03bb56-6c12-48fb-b47e-4c266fe57c43") => Thu, 03 Jan 2019 [28] pry(main)> Date.parse("fc03bb56-6c12-48fb-b47e-4c266fe57c45") => Thu, 03 Jan 2019 [29] pry(main)> Date.parse("ac03bb56-6c12-48fb-b47e-4c266fe57c45") => Thu, 03 Jan 2019 [30] pry(main)> Date.parse("a-b-c-d-e") ArgumentError: invalid date from (pry):29:in `parse' [33] pry(main)> Date.parse("aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee") ArgumentError: invalid date from (pry):32:in `parse' -
各位大神,是我的姿势不正确吗? at 2019年01月23日
没看懂,这是什么用法?
-
gatsby 开一个博客很容易 at 2019年01月18日
前段时间也迁移了一把,从 Jekyll 迁移到了 Gatsby,相比 Jekyll,Gatsby 更灵活,自己可以控制更多细节。https://baurine.netlify.com/2018/12/08/migrate-to-gatsby/
-
《Rust 编程之道》预售开启 at 2019年01月16日

第二批到的。
-
Webpack v5 Alpha - 又来一大堆 Breaking Changes at 2018年12月24日
通篇看下来不是很 breaking 啊,感觉改变的多是内部的实现,最上层的 config 的写法好像没什么变化。
-
react and rails 最佳实践? at 2018年12月21日
谈不上最佳实践,但我们是这样做的:
- 不需要 SSR 的话,用 webpacker + react,rails 实现 API
- 需要 SSR,用 webpacker + react-rails,仅用 react 作为 view,替代原来的 html 模版
-
Awesome Ruby China at 2018年09月06日
-
Rails 开发 SPA 项目 at 2018年08月09日
我是这样做的:
export default class ApiUtil { static apiRequest(method, url, body) { const options = { method, credentials: 'include', headers: { 'X-CSRF-Token': document.querySelector('meta[name="csrf-token"]').getAttribute('content'), 'Accept': 'application/json', 'Content-Type': 'application/json', } } if (body) { options['body'] = JSON.stringify(body) } return fetch(url, options) ... -
Vue + Rails 做前后端分离,请问登录该如何处理呢 (原系统用的 Devise),恳请大佬们提建议 at 2018年07月11日
devise 部分可以保留后端渲染,只对 devise 以外的部分进行了前后端分离。用 devise 登录以后,如果你是用 fetch 进行 API 请求,要在请求的 option 中加上
credentials: 'include',就可以在 API 请求时带上 cookie 和 session 了。 -
在 Rails 中实现拖拽排序功能 at 2018年05月29日
受教了,目前有类似的需求,决定试试 @fan124 的方案。
-
我目前采用的是 React + Rails,关于 UI 组件如何引入? at 2018年05月16日
我的一种实践:https://ruby-china.org/topics/35505
react-rails gem + webpacker
-
在 Rails 中使用 React 并实现 SSR 的一种实践 at 2018年04月25日
@Rei 我之前看到你的评论了,没来得及回复,现在看好像你的内容已经改过了,我印象中你之前的评论中是说了关于前后端分离的情况,不过仔细看文章我话,其实我这个实践是没有做前后分离的,就用了 React 最最简单的一个功能,作为 view,用 react component 替代了原来的 html view 模板。router 也还是 rails 的 router,数据也都是在服务端产生,通过 props 传给 react component。这种用法几乎没有对原来的整体框架产生太大的变化。(即使不需要 SSR 也可以这么用)
一开始这样做我也是觉得有些拧巴的,但后来我体会到了一些好处,我说说我的感受。
- 用 react component (我一直用 jsx 语法) 替代原来的 html view 模板来写 view,表达能力和灵活性都大大加强了 (有待举个例子进行一下对比,但我觉得大家对这一点应该是认可的,毕竟一个是编程语言,一个是标记语言),阅读调试我觉得都更加方便了。在原来的模板中,以 haml 为例,你 include 另一个模板,你都没法直接在编辑器里跳转过去。
- 我觉得用 react 另一个最大的好处在于,组件终于能完全复用了。我把一个组件封装好后,放到 npm 上,别人 install, import 一下基本就能马上用起来了。而如果你用一个基于 jQuery 实现的组件,首先要把 js 引进来,然后你需要在 html 中至少声明一个特定的标签,还有可能必须是指定的类名或 id,然后可能还需要调一下某个 js 方法来进行一下初始化。相比 react 组件的使用就麻烦了不少。
这是 RateYo! 的使用示例:
<-- HTML --> <head> <-- Basic styles of the plugin --> <link rel="stylesheet" href="jquery.rateyo.css"/> </head> <body> <div id="rateYo"></div> <script src="jquery.js"></script> <script src="jquery.rateyo.js"></script> </body> /* Javascript */ //Make sure that the dom is ready $(function () { $("#rateYo").rateYo({ rating: 3.6 }); });这是 React-Stars 的使用:
import ReactStars from 'react-stars' import React from 'react' import { render } from 'react-dom' const ratingChanged = (newRating) => { console.log(newRating) } render(<ReactStars count={5} onChange={ratingChanged} size={24} color2={'#ffd700'} />, document.getElementById('where-to-render') );(代码行数上可能是没更少,但逻辑是集中在一起,没有割裂在不同的地方)
相比传统 html view 模板,我想缺点可能就是性能问题,这个有待 profile 一下到底差多少。但如果对性能需求不是那么高的话,又不喜欢写 html view 模板,那么值得尝试一下这种方式。
而且如果不需要考虑 SEO,那么就不需要为 React 做 SSR,那性能会和传统 html view 模板几乎没有差别。
以上是我的一些拙见。
-
在 Rails 中使用 React 并实现 SSR 的一种实践 at 2018年04月23日
@Littlesqx 是的,但 js 代码是不是由 node 来执行的我还不确定。
react-rails 文档上是这么说的:
Server rendering is powered by ExecJS and subject to some requirements
(https://github.com/reactjs/react-rails#server-side-rendering)
而 ExecJS 是支持多种服务端的运行时的:
ExecJS supports these runtimes:
- therubyracer - Google V8 embedded within Ruby
- therubyrhino - Mozilla Rhino embedded within JRuby
- Duktape.rb - Duktape JavaScript interpreter
- Node.js
- Apple JavaScriptCore - Included with Mac OS X
- Microsoft Windows Script Host (JScript)
- Google V8
- mini_racer - Google V8 embedded within Ruby
-
关于符号 ” 被转义成 " 的解决方法,不使用 raw 和 html_safe 方法!!! at 2018年02月07日
rails 的默认行为是转义,如果你想输出富文本,又想保证安全,用 sanitize !
你可以再看一下这个帖子:https://ruby-china.org/topics/16633 我在后面有追加提问。
-
别用 raw 和 html_safe at 2018年02月07日
@jasl ,有点明白了,是不是可以这样理解。
转义并不能输出富文本,它输出的是原始文本。
如果你想输出富文本,简单粗暴的方法是
<% raw danger_string %>来实现的,但这样会有安全影患,所以要用 sanitize 来将富文本中危险的标签,比如<script>过滤掉。got it! 谢谢!
-
别用 raw 和 html_safe at 2018年02月07日
另外,好奇一下论坛帖子的排序顺序是怎么样的,为什么这个帖子有新的回复,我再回到社区首页,却找不到这个帖子呢?
-
别用 raw 和 html_safe at 2018年02月07日
@Rei @jasl 今天遇到了 HTML 转义和过滤的问题,看了好多资料,没有哪篇文章指出转义和过滤的区别,什么时候该用转义,什么时候该用过滤,还是两者一起用。
我对下面三种表述做了一下对比 (ruby 2.3.3 & rails 5.0)
<%= danger_string %> <%= sanitize danger_string %> <%= raw danger_string %>假设
danger_string原始值是<script>alert("xss");</script>,三者在 HTML 源码中分别是:<script>alert("xss");</script> alert("xss"); <script>alert("xss");</script>可见,第一种表述,即 rails 的默认行为,我觉得并不是过滤,而是转义。在前端界面中你可以看到完整的
<script>alert("xss");</script>内容。第二种表述,sanitize 才是过滤,把
<script>标签去掉了。在前端界面中你只能看到alert("xss");的内容。第三种表述毫无疑问是会执行其中的 JavaScritp 代码的,并在前端页面中看不到内容。
如果
danger_string的原始值是<em>haha</em>,三者在 HTML 源码中分别是:<em>haha</em> <em>haha</em> <em>haha</em>第一种表达,在前端界面中,可以看到完整的
<em>haha</em>内容。第二种和第三种,在前端界面中,看到的都是斜体的 haha。可见,sanitize 默认只对部分标签进行过滤。
回到开头的疑问,想请教一下大家,转义和过滤,它们之间是一种什么关系?什么时候该用转义,什么时候该用过滤。
另外,转义和过滤,可以发生在将数据存入到数据库时,也可以将原始内容原原本本存入数据库,只是在渲染时,将其转义和过滤,哪一种方式是更常采用的?
谢谢!
-
详解 Cookie 和 Session 关系和区别 at 2018年02月03日
以下是我在看《Agile Web Development Rails 5》时所做的笔记,不知道理解得是不是完全正确。
Rails Sessions
session 用来保持状态,不要和 cookie 混淆,它们只是有一点点交集而已。
Session Storage
Session 的存储方式
session_store,在 rails 中多达 6 种::cookie_store:active_record_store:drb_store:mem_cache_store:memory_store:file_store
这 6 种方式,除了第一种
:cookie_store是存储在客户端,其余都是在服务端进行状态的持久化。而第一种也是最常用的方式,这就是为什么我们很容易把它和 cookie 混淆。cookie 是实现 session 的一种手段。我认为,人们常说的 cookie 有广义和狭义之分,广义的 cookie,就是被浏览器客户端持久化的这些对象,会在每次请求时被浏览器自动携带,它包括狭义的 cookie 和 session。狭义的 cookie 就是所有的 cookie 中除去 session 的那部分。
如果采用
:cookie_store方式的 session,数据失效很好处理,关闭浏览器,再打开浏览器,cookie 中的 session 部分就会被自动清空,所以这种方式 session 的有效周期维持在一个浏览器进程时长。这种方式将减轻服务端逻辑。如果采用服务端方式的 session,session 的生命周期是永久的,因此必须借助过期时间来清除过期的 session。另外,要注意,采用服务端方式的 session,并不是说就不需要往客户端存储任何数据了,还是需要的,只是只需要存储一个
session_id,然后通过session_id到服务端再去拿对应的其它数据。 -
请教如何实现一个 Model 的修改需要 Admin 审核通过才能生效? at 2018年01月30日
谢谢 @jasl ,我先看一下这个文档。
-
送几本《Ruby on Rails 教程 (第 4 版)》纸质书 at 2017年10月30日
支持一下,电子版从头到尾看了两遍。
-
求助 Puma + Nginx 跑 Rails 出错 at 2017年08月17日
遇到一样的问题,通过
cap production puma:restart解决。而且如果我没有set :linkd_dirs是没有问题的,一旦set :linkd_dirs后就会在 nginx.error.log 里看和 #30 楼一样的 log,必须每次在cap production deploy后再运行一下cap production puma:restart. -
模型之间的多对多关联 controller 和 model 应该怎么命名 at 2017年05月03日
如果是我,我会将这个表名命名为 student_teacher_relationships (复数), 把 model 命名为 StudentTeacherRelationship (单数),或者表名简化为 relationships (复数),model 简化为 Relationship (单数)。
创建关联:
class Student < ApplicationRecord has_many :releationships, dependent: :destroy has_many :teachers, through: :relationships end -
[北京][可远程] MakeHave 每刻风物程序员需求计划「2015.8.25 更新」 at 2015年07月15日
请问贵司还需要 Android 开发工程师吗?