新手问题 在 Rails 中使用 PostgreSQL 的全文搜索功能搜索百万条记录的表的正确姿势
请教大家一个问题,我现在的 rails 项目中,使用的是 PostgreSQL,有一张表,有一百万条记录,假设表名叫 movies,有 title 和 description 两列。现在我使用全文搜索功能,通过 title 或 description 搜索得到相应的记录。
第一步我使用 pg_search (https://github.com/Casecommons/pg_search) 这个 gem,给 Movie model 加上相应的 pg_search_scope:
include PgSearch
pg_search_scope :search_by_title,
against: :title,
using: {
tsearch: {
prefix: true,
}
}
pg_search_scope :search_by_desc,
against: :description,
using: {
tsearch: {
prefix: true,
}
}
使用 Movie.search_by_title(search_value) 或 Movie.search_by_desc(search_value),需要几十秒甚至数分钟钟才能得到结果,如下图所示:

我明白这是由于没有建立索引的缘故,于是我按照 pg_search wiki 上的指南 (https://github.com/Casecommons/pg_search/wiki/Building-indexes),为这两列建立全文搜索的列及索引。
def change
add_column :movies, :tsv_title, :tsvector
add_index :movies, :tsv_title, using: 'gin'
say_with_time("Adding trigger function on movies for updating tsv_title column") do
sql = <<-MIGRATION
CREATE TRIGGER tsv_for_ep_title BEFORE INSERT OR UPDATE
ON movies FOR EACH ROW EXECUTE PROCEDURE
tsvector_update_trigger(tsv_title, 'pg_catalog.simple', title);
MIGRATION
execute(sql)
end
add_column :movies, :tsv_description, :tsvector
add_index :movies, :tsv_description, using: 'gin'
say_with_time("Adding trigger function on movies for updating tsv_description column") do
sql = <<-MIGRATION
CREATE TRIGGER tsv_for_ep_description BEFORE INSERT OR UPDATE
ON movies FOR EACH ROW EXECUTE PROCEDURE
tsvector_update_trigger(tsv_description, 'pg_catalog.simple', description);
MIGRATION
execute(sql)
end
end
修改 pg_search_scope:
include PgSearch
pg_search_scope :search_by_title,
against: :title,
using: {
tsearch: {
prefix: true,
tsvector_column: 'tsv_title'
}
}
pg_search_scope :search_by_desc,
against: :description,
using: {
tsearch: {
prefix: true,
tsvector_column: 'tsv_description'
}
}
如此操作之后,搜索速度大为改进,一般情况下几秒钟可以返回结果,好的时候几百毫秒可以返回结果。如下图所示:
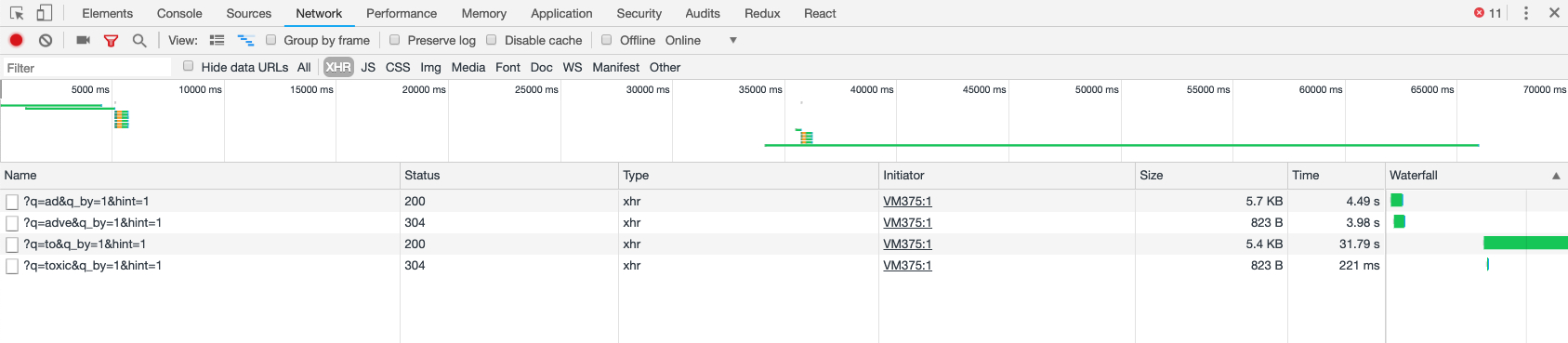
那么问题是什么呢,现在我要同时通过 title 和 description 搜索,按照 pg_search 的文档,pg_search_scope 是这么写的:
pg_search_scope :search_by_title_desc,
against: [:title, :description],
using: {
tsearch: {
prefix: true,
tsvector_column: %w(tsv_title tsv_description)
}
}
特别之处在于 tsvector_column 时要声明 tsv_title 和 tsv_description 两列。
同时通过 title 和 description 搜索后,搜索速度又骤降,需要几十秒才能返回结果。如下图所示。

所以请求一下大家,针对这种百万级别的表,对多列同时进行全文搜索的正确方法是什么?预期是希望在数秒内得到结果。
在上例中,我是需要同时对这两列创建一个新的 tsvector 的列并加索引吗?
谢谢!