Rails 单机数据抓取性能提升总结篇
本帖已被管理员设置为精华贴
写了一段抓据数据的代码,发现速度并不是很快,下面是我做的一些优化, 速度提升了不少,但是还是感觉不够快,你还有更快的方法吗?一起分享一下吧 最终单机测试,4w 左右/1 小时,Ubuntu14 2 核 8G 内存
第一版
Team 有上百万,单次循环太慢 使用 mechanize 抓取数据,并解析,耗时 0.4s 左右 news 虽然使用了单次 transaction 提交,但是还是最耗时的操作
Team.find_each do |team|
begin
team_id = team.id
team_name = team.try(:name)
puts team_name
news = FetchNews.get_touch_news(team_name)
news.each do |params|
TeamNews.transaction do
TeamNews.create(params.merge!(team_id: team_id))
end
end
rescue => e
puts "something woring with team_id #{team_id}: #{e}"
end
end
第二版
使用文件临时存储抓取的数据,当数量超过 1w 的时候,使用 LOAD DATA LOCAL INFILE 一次写入,只需要 0.00xs, 删除临时文件,进行下一次迭代,依次类推,节省了不少数据库 操作,性能上来不少。 使用 LOAD DATA LOCAL INFILE 注意事项:
- 唯一性验证:保证批量导入后不会重复,给标题添加数据库唯一性验证。 ALTER TABLE table_names ADD unique(title);
- 开启上传本地文件到服务器 命令行> mysql -h ip -u user_name -p --local-infile=1 rails: config/database.yml中配置local_infile: true 否则会报错:The used command is not allowed with this MySQL version: LOAD DATA LOCAL INFILE 参考资料: http://dev.mysql.com/doc/refman/5.6/en/load-data.html http://stackoverflow.com/questions/19819206/load-data-infile-error-1064 http://stackoverflow.com/questions/21256641/enabling-local-infile-for-loading-data-into-remote-mysql-from-rails 抓取数据 FetchNews.get_touch_news 的速度提升空间不大,网络传输的时间很难缩减, 这一步暂时不处理 下一步考虑的是把 company 进行分组,同时启动多个进程,使用了 resque, 把 id 分组存入到 resque 中,再从 worker 中读取
file_path = "#{Rails.root}/fetch_news.txt"
Team.find_each do |team|
begin
File.delete(file_path) if File::exists?(file_path)
team_id = team.id
team_name = team.try(:name)
puts team_name
news = FetchNews.get_touch_news(team_name)
File.open(file_path,"a") do |file|
news.each do |a_new|
result = [a_new[:title], a_new[:url], a_new[:date], team_id].join(";").concat("\n")
file.puts(result)
end
end
rescue => e
puts "something woring with team_id #{team_id}: #{e}"
end
ActiveRecord::Base.connection.execute("
LOAD DATA LOCAL INFILE '#{file_path}' INTO TABLE db.team_news
FIELDS TERMINATED BY ';' LINES TERMINATED BY '\n' (title,url,date,team_id);
")
File.delete(file_path) if File::exists?(file_path)
end
第三版
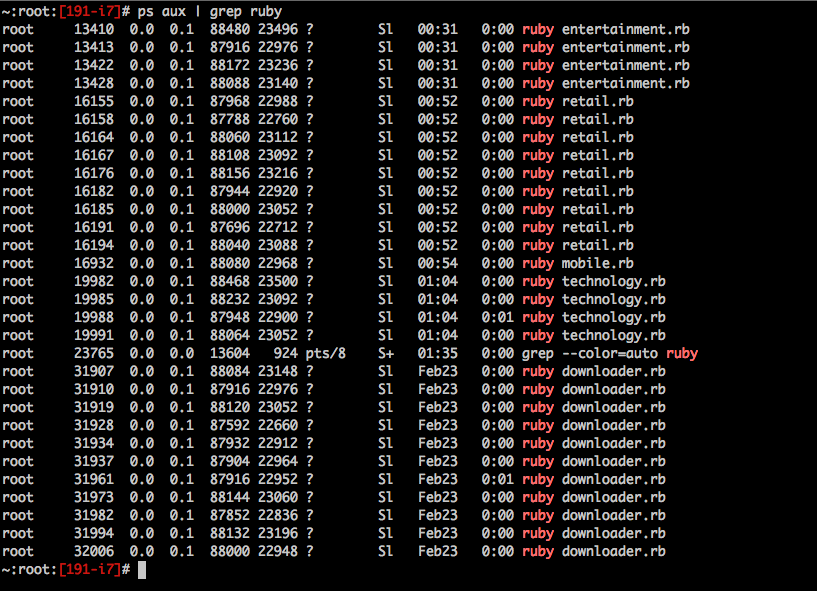
用进程 id 来区分不同的临时文件,其他的跟上面的一样,这样开启 6 个 worker,速度就提升了 6 倍
class TeamFetchNewsWorker
@queue = :team_fetch_news_worker
def self.perform(team_ids)
pid = $$
file_path = "#{Rails.root}/fetch_news_#{pid}.txt"
...
end
end
第四版
使用 ruby 多线程机制,给每个 worker 多开几个线程,试试 那么 resque job 中,这样存 ids, 一共存了 4 组,因为我要开启 4 个线程 (后面测试开了 10 个,数据库链接不够用了,so...) 这样速度又提升了 4 倍!
[[1,2,3,4...],[5,6,7,8...],[9,10,11,12...],..]
class TeamFetchNewsWorker
@queue = :team_fetch_news_worker
def self.perform(team_ids_group)
pid = $$
threads = []
team_ids_group.each_with_index do |ids, index|
file_path = "#{Rails.root}/fetch_news_#{pid}_#{index}.txt"
File.delete(file_path) if File::exists?(file_path)
threads << Thread.new do
Team.find(ids).each_with_index do |team, index|
...
end
end
end
threads.each{|t|t.join}
end
end
第五版
从业务角度出发,第一次跑的时候,根据抓取结果给 Team 打上标签,指定抓取的级别 根据级别指定抓取频率,初始化后的效果还会节省不少时间。性能倒是提升不了,但是目标 达到了,避免了大量的无用的抓取时间
查看更多 博客:http://michael-roshen.iteye.com/blog/2164721 微信:ruby 程序员