https://github.com/vfreefly/kimurai
Kimurai is a modern web scraping framework written in Ruby which works out of box with Headless Chromium/Firefox, PhantomJS, or simple HTTP requests and allows to scrape and interact with JavaScript rendered websites
很多地方借鉴 scrapy,但比 scrapy 好的地方:
Scrapy didn't support out of box easy scraping of Javascript rendered websites. It has Splash https://github.com/scrapy-plugins/scrapy-splash (Their own Headless browser, special for Scrapy) but even if so, it's not that easy to interact with Splash browser (click buttons, filling forms, etc.), you have to provide Lua (yes, not Python) script for that.
https://www.reddit.com/r/ruby/comments/95y0ru/kimurai_is_a_modern_web_scraping_framework/e3xnin7/
我没有爬虫需求所以没用过,有需求的人可以试试。

为什么就没人封装一个 jquery 选择器语法的,用 python 做爬虫很大原因就是因为有个 pyquery,ruby 也需要一个 rbquery
Scrapy 用得都是泪,几个痛点:
- 浏览器 (Splash) 和代理一起用就麻烦得一 b, 想要某些用代理某些不用代理,就得用隐藏的 dont_proxy 选项控制
- Web 服务 (Scrapyd) 就只是一个单机服务而已,根本没考虑部署多台机器 (当然一般一台机器就够了不过扩展起来要自己搞很多东西)
- Scrapy 设计的 parse callback 其实很不 flexible, 很难接收 request 的一些参数,如果想用 lambda 会发现有一堆限制 (例如里面不准用 statement), 于是就得切出去多搞一个类...
- Python 处理字符串限制太多,正则的使用极其不方便,urllib 的一些辅助函数在各版本变化很大
基于这些,我觉得 kimurai 相当不错了 (即使用的人不多)
早在 2011 年,我第一次尝试 nokogiri 的时候就感叹:“我擦,这玩意儿用起来感觉和 jQuery 一样……”,结果到今天还能看到你抱怨没人封装一个 jQuery 选择语法的。可见之前我对你的评论并没有任何偏颇。
不是有个 css 选择器就能称为类似 jquery 的,如果这都能算“感觉和 jQuery 一样”只能说你的感官太丰富
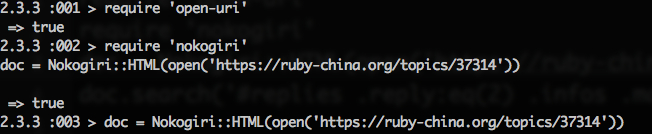

before(), after(), prependTo(), html(), text(), attr(), ... 是没有的,Nokogiri API 是不如 jQuery 那么好记

在这里说的是爬虫,又不是 DOM Manipulation,除了选择器语法之外,你还指望 Nokogiri 哪里要做到和 jQuery 一样呢?
lol...被迫删掉了,项目里借鉴了一些作者半年前给一家公司干 freelancer 活时候写的代码 具体看这吧:https://github.com/vfreefly/kimurai#repository-was-removed
however... 这里很多 forks: https://github.com/vfreefly/kimurai/network/members
作者的最新更新:
Kimurai will be reopen soon
and will keep the same design and features. I have plans to rewrite a few parts of a framework so it will be 100% open source without any doubts. Also, there is work to do to allow run multiple crawlers from inside a single Ruby process (run crawlers using background jobs). And, there will be added "mechanize-only" mode (mechanize engine without Capybara dependency).