数据库 [你还不用 pg?] 坑爹的 MySQL 事务
mysql 的事务隔离级别 repeatable read 并不能阻止常见的并发更新。
下面代码中 c 和 c2 就是两个并发的 session, c2 在事务中给字段 accounts.money 做了 +1 操作,但 c 在 c2 的事务进行了一半时修改了 accounts.money 的值,结果就是没发生任何事务错误,把 c 的更新给丢了,用户神秘损失 1 块钱。
require "mysql2"
c = Mysql2::Client.new(:host => "localhost", :username => "root")
c.query 'use dummy'
c.query 'set autocommit=1'
c.query 'delete from accounts'
c.query 'insert into accounts (money) values (1)'
puts "at first money = 1"
id = c.query('select * from accounts').first['id']
t = Thread.new do
c2 = Mysql2::Client.new(:host => "localhost", :username => "root")
c2.query 'use dummy'
c2.query 'set autocommit=1'
c2.query 'set transaction isolation level repeatable read'
c2.query 'start transaction'
puts "c2 starts transaction"
money = c2.query("select * from accounts where id = #{id}").first['money']
puts "c2 selected money = #{money}"
sleep 2 # to let c change money
c2.query "update accounts set money = #{money + 1} where id=#{id}"
puts "c2 set money = #{money + 1}"
c2.query 'commit'
end
sleep 1 # to let c2 select money
puts "c set money = 2"
c.query "update accounts set money = 2 where id = #{id}"
t.join
注意这个是 mysql 的问题,上面的代码写成 sql 存储过程也一样存在。解决的方法只有读数据时改成 select ... for lock in share mode, 或者直接改用 pg:
require "pg"
c = PGconn.open dbname: 'dummy'
c.exec "set autocommit to on" # NOTE, if off, it will require transaction wrapping single statement updates
c.exec 'delete from accounts'
puts "at first money = 1"
c.exec 'insert into accounts (money) values (1)'
id = c.exec('select * from accounts').to_a.first['id']
t = Thread.new do
c2 = PGconn.open dbname: 'dummy'
c2.exec "set autocommit to on"
c2.exec 'start transaction isolation level repeatable read'
money = c2.exec("select * from accounts where id = #{id}").to_a.first['money'].to_i
puts "c2 selected money = #{money}"
sleep 2
c2.exec "update accounts set money = #{money + 1} where id = #{id}"
puts "c2 set money = #{money + 1}"
c2.exec 'commit'
end
sleep 1
puts "c set money = 2"
c.exec "update accounts set money = 2 where id = #{id}"
t.join
5-24 更正:一开始我的理解不对,确切的说是 mysql repeatable read 隔离等级的问题而与 phantom read 无关,为免误解已经把幻读部分去掉。
mysql 的 repeatable read 真的会禁止 phantom read, 也就是事务内两次查询得到的 id 集合是一致并且正确的,但是记录的内容不保证正确。
mysql 的解决办法是对读到的记录加锁,或者用 read committed + 乐观锁也可以。
@Tony612 @saiga @bhuztez 晚上做了实验,发现 mysql 用 repeatable read + 乐观锁依然可以防止错误的并发更新。原因是 rails 的乐观锁使用了这样的更新语句:where id = ? and lock_version = ?, 如果别的事务更新 lock_version, 这个查询得到的记录集合就是空的,就 phantom read 了,而 mysql 对 phantom read 的处理是正确的,然后就会产生事务错误,防止了并发更新的数据丢失。
以下代码,mysql 可以在默认的隔离等级中识别乐观锁
require "active_record"
require "mysql2"
require "logger"
ActiveRecord::Base.logger = Logger.new($stdout)
ActiveRecord::Base.logger.level = Logger::DEBUG
def connect
ActiveRecord::Base.establish_connection \
adapter: 'mysql2',
database: 'dummy',
username: 'root',
host: 'localhost',
pool: 5
end
def init
Article.delete_all
ar = Article.new
ar.n = 1
ar.save!
end
# columns: id serial, n integer, lock_version integer
class Article < ActiveRecord::Base
end
fork do
connect
init
Article.transaction do
a = Article.first
puts "t1: #{a.n}"
sleep 2
a.n += 1
a.save!
puts "t1 updated"
end
end
fork do
connect
sleep 0.3
Article.transaction do
a = Article.first
puts "t2: #{a.n}"
sleep 1
a.n += 1
a.save!
puts "t2 updated"
end
end
sleep 3
puts '-' * 50
connect
puts Article.first.n

试了一下,还真的是,虽然我没怎么在多线程环境下搞过,不过这样的话,多线程下岂不是很有问题?
特别是用 ActiveRecord 的话,会加 select ... for lock in share mode么?
#4 楼 @Tony612 AR 在表里加上 lock_version 字段可以自己解决这个问题 虽然解决方式很 low... http://api.rubyonrails.org/classes/ActiveRecord/Locking/Optimistic.html
借 LZ 的地方想问问,不知道哪里有比较好的 PG 方面的论坛或较为深入&高效的学习/实践资料?中国公开的技术论坛在这一块资料太少了,ITPUB 甚至连 PG 的板块都没有。

我感觉 MySQL 的说法在这里是对的,也就是那里没有出现 Phantom Read。
Phantom Read 是说一个事务里,第一次读出来值为 X 的话,你读第二次读出来值可能是 Y,因为另外一个事务在你两次读之间提交了,并改了这个值。
因为 MySQL 没有 Phantom Read,所以update accounts set money = money + 1时是根据当前事务上一次读到的值来算的。而 PostgreSQL 有 Phantom Read,所以此时是根据最新?commit 的值来算的。
你那样的说法,把这个概念给完全搞反了
#17 楼 @bhuztez 首先 phantom read 是指查询的结果集合变化了,是事务进行过程中删除了或者又插入了记录造成的。
其次 repeatable read 隔离等级首先要做的是对已经查询的记录加上 lock 机制禁止更改,而不是字面上的"可以重复读到一样的值" --- 否则我要你这个事务有何用?我干嘛读第二次?
再说 SQL-92 标准是允许 repeatable read 中出现 phantom read 的,但不允许读取过的记录被别的事务更改。标准规定的 repeatable read 会自动对读出来的记录加锁但不加 range lock (range lock 类似于锁表,但只锁定满足 where 语句的部分), serializable 是有 range lock 的。
不过 pg 实现的 repeatable read 也是没有 phantom read 的 (见 http://www.postgresql.org/docs/9.1/static/transaction-iso.html) , 事务开始后,别的事务如果做插入或者删除记录操作,其中一个会回滚而不是读取新的 commit 的值。对同一记录,pg 的 repeatable read 不会第一次读出 X 第二次读出一个 Y 来,只会读出 X (没更改) 或者是回滚 (被更改).
#18 楼 @luikore 例子没仔细看,也懒得运行,你还是顺手贴个结果吧。上面我说的确实不对。
phantom read 是指查询的 结果集合 变化了,是事务进行过程中删除了或者又插入了记录造成的。
所以,这里应该不是 phantom read 的问题
其次 repeatable read 隔离等级首先要做的是对已经查询的记录加上 lock 机制禁止更改,而不是字面上的"两次读到的值一致" --- 否则我要你这个事务有何用?我干嘛读第二次? 再说 SQL-92 标准是允许 repeatable read 中出现 phantom read 的,但不允许读取过的记录被别的事务更改。
应该是允许更改的。只是别的事务的更改不会影响到这个事务第二次读取的结果而已。MySQL 的方式应该是没问题的。
不可重复读:一个事务对同一行数据重复读取两次,但是却得到了不同的结果。
mysql 说,我实现了Repeatable reads,但我
不能保证你会读到正确的结果
对于标准的理解不同?对于这个问题,我也认为 mysql 是在敷衍
#3 楼 @luikore 抱歉,之前没有完整看帖就草草回复。 但 mysql 和 postgres 都是没有问题的,都符合标准定义。 区别在于 postgres 在 Repeatable reads 级别,默认的实现了乐观锁,防止并发 update 时的覆盖写问题。 这并不能说明 mysql 不好,因为乐观锁在某些情况下(较大量命中锁机制时)会导致性能问题。所以 mysql 选择了把选择权交给用户(当然也把工作量留给了用户)。
接下来就是我写在二楼的话了:没什么坑爹不坑爹的,侧重点不同而已。mysql 的优势从来都不在事务处理方面,而 postgres 一直都是致力于出色的事务处理。
最后,关于 count 那部分是我想当然了,抱歉。 同时希望楼主可以把标题改一下,从回复来看,已经有朋友被误导到了。
标题完全不用改,要改的话,把幻读部分的内容去掉就行了。Repeatable read还分级别吗?MySQL 是字面级别的Repeatable read?
如果要保证我举的例子的并发更新的正确性,在 mysql 中能选择
- serializable
- repeatable read + 悲观锁
- read committed + 乐观锁
在 pg 中能选择
- serializable
- repeated read
- read committed + 乐观锁
没见得用 mysql 就有很多选择权吧... 如果要的是并发插入记录的速度,在 PG 中还能选择 UUID 主键呢
mysql 的默认隔离级别是repeatable read,pg 默认的是read committed. 所以默认级别下,都需要加锁。
@luikore 你们在生产环境下把 pg 的隔离级别改为repeatable read? 产生了什么影响?

@baibaluo +1
我觉得 mysql 的实现没有什么问题,基于 multiversion concurrency control 实现的 isolation level, 和锁没有必然联系。
pg 的 isolation level 实现本来就是强于 sql 标准的 (见 pg 自己的文档),不能当作标准说事。
@luikore 既然这么推崇 pg. 那来推荐一款可以媲美 Sequel Pro 的 GUI 吧!昨天找到一个 valentina studio free 但是感觉还是不如 Sequel Pro。。
1)只要能避免不可重复读取和脏读取,就是对 SQL 标准中 repeatable read 的恰当实现,mysql 没有任何问题。 2)楼主对事务隔离级别的认识不够,恐怕也没了解过 MVCC 的实现方法 3)PG 对 repeatable read 的实现是以 SQL 标准中的 Serializable 来实现的,也就是说避免了不可重复读取和脏读取的同时,还阻止了幻读,这是过度实现,因为标准只禁止了不可出现的情况,并没有规定必须允许出现幻读。文档中明确写出:
...and phantom reads are not possible in the PostgreSQL implementation of Repeatable Read, so the actual isolation level might be stricter than what you select. This is permitted by the SQL standard: the four isolation levels only define which phenomena must not happen, they do not define which phenomena must happen.
参见:http://www.postgresql.org/docs/9.3/static/transaction-iso.html
我不理解本文的加精的理由是什么?
1) SQL-92 标准里定义的不明确已经被无数人吐槽过了,而且标准里是用锁来做定义的标杆的,那时还没有 MVCC 呢. 2) 我是认识不够,mysql 这么做的逻辑我是弄不懂,反正我也不用 mysql 了不用踩坑了... 但你认识充足肯定有大量的解决 mysql 事务坑的经验吧?
在一个 repeatable read 事务里,mysql 可以产生这样的现象:
-
select * from articles where id=1 and n=1返回 1 条记录 -
update articles set n=2 where id=1 and n=1影响 0 条记录
这对不对?
3) 自己看清楚自己给的链接吧,里面都给了 PG 的 repeatable read 和 serializable 的行为区别的例子
其他问题,我不想扯太远,我只看你主楼的例子,这里面你自己跳到坑里了,跟 mysql 对这个事务隔离级别的实现没关系(我再强调一遍,mysql 对事务隔离级别的实现完全符合 SQL92 标准,你对 SQL92 标准吐槽是你自己的事,但你不该对 mysql 吐槽(再说了,就这个标准你也没有吐槽的理由,主楼的例子是你自己挖的坑))
你主楼的例子无非是: 1)数据本身是 1 2)事务 1:a.读取记录,b.然后加 1 3)事务 2:加 1
如果事务 2 在 a 与 b 之间执行,会导致事务 2 的 +1 丢失。你认为这是 mysql 的实现有问题。
真正的问题是: 事务 1 的意义是什么?你读取出来是 1,然后改成 2,数据库并不知道你的用意是 +1,数据库只知道你的目的是把他改成 2。数字从 1 到 2,我们可以看出来你的意思是 +1,如果换个例子,你把“姚明”改成“刘翔”,那你的意思又是在做什么运算呢?你如果要实现的就是 +1,你就不该这么写,你应该直接写 update accounts set money = money + 1
换句话来说,你的例子还有另外一个版本: 1)数据本身是姚明 2)事务 1:a.读取记录,b.然后变成刘翔 select * from users where id = n update users set name = '刘翔' where id = n 3)事务 2:改为易建联 update users set name = '易建联' where id = n 这两个事务都是改名,他们没有递进关系,谁后执行,谁就起效(当然是后面改的名字覆盖前面的了),如果这个时候,刘翔改慢了一步,得到了保存,你总不能说”易建联"丢失了吧?
而真正反应你本意的例子也有另外一个版本: 1)数据本身是 1 2)事务 1:加 1 update accounts set money = money + 1 where id = n 3)事务 2:加 1 update accounts set money = money + 1 where id = n
这个例子,还会丢失吗?
#49 楼 @Rei 学习了,谢谢,下次知道了。恢复的内容如下:
1)SQL 标准有缺陷,但不代表对于事务隔离级别的定义有问题,它的定义是明确的,而且 mysql、oracle、pg 都基本支持这个标准;标准是规范,MVCC 是实现,出现的前后代表什么?你想表达什么?
2)你举的这个例子很莫名,你想说 mysql 有 bug 吗?这个语句的上下文是什么?
3)我看的很清楚,我给的例子证明了 PG 对 repeatable read 的实现,已经实现了 SQL 标准中的 serializable,属于过度实现,至于实现细节,我并不 care。
最后,回到本文,你主楼的例子,就是一个明显的逻辑混乱。我可以举个例子:
一个用户本来有 100 块钱,现在有两个事务,一个事务是给这个用户加 10 块钱,另外一个事务是把这个用户的钱改成 500。
如果用户先改成 500,然后加 10 块,这样就是 510;如果这个用户先读取数据是 100,然后一个事务加 10 块提交,另外一个事务改成了 500,就丢失了 10 块,你不就是这个意思吗?
出现这个问题的根本原因在于,改成 500 的这个事务的目的你没搞清楚,他的目的是改成 500,还是加 400?这个是关键。如果你这个事务的目的是加 400,就不是先读取出来 100,然后加 400,而是直接 update uesrs set money = money + 400,这样无论什么事务的顺序都没问题了,你所谓赋值为 500,事务的本身含义就是把他改为 500。懂了吗?
#53 楼 @luikore 首先,你必须承认,你主楼中读取出来 1,然后赋值为 2 的操作,数据库的理解是恰当的,隔离级别的实现也完全符合标准,并不是你所谓的坑。数据库只知道你的最终结果要求是 2,并不知道你的本事是 +1.
其次,对于你的问题,跟隔离级别无关,是你自己不加锁。就拿你的主楼例子好了: select * from accounts where id = n for update # 读取出来是 300,然后你进行各种复杂的运算,结果是 92 update accounts set money = 92 where id = n
你的意思难道数据隔离级别是万能的,如果不是万能的,就是坑?你可以不用锁,反正随便写写,数据库就知道你想干嘛?(还推测你从 1 到 2 的变化是 +1 还是只是想把它的户头变成 2?也拿这个例子来说,从 300 到 92,数据库又该怎么理解?)。其实要解决你所谓的坑,数据库无脑加锁就可以了,它之所以用 MVCC,然后把加锁的选择留给你,就是从性能考虑的,否则为什么自己找麻烦?
然后你举得利息的例子,一样: select * from accounts where id = n for update # 读取是 300,利息 15 update accounts set money = 315 where id = n update banks set money = money - 15 where id = bank_n
你主楼的例子,可以提醒大家正确理解数据库隔离级别,不要以为有了 repeatable read,就可以无脑更新记录了,要跳过自己思维里的坑,给大家提个醒还差不多。而拿这个来说 mysql 有坑,就完全搞错了。
我用的是 PG,对数据库不持立场。
#55 楼 @luikore 楼主你最后所说的话,明显与你之前回复的内容不一致啊。。。
一、你所说的默认加锁还不影响性能 1)你所说的不影响性能,有依据吗? 2)如果真的不影响性能,奥妙在哪里?(因为我们知道不必要的锁显然会降低性能的)
二、mysql 的做法是错的,让人以为它的隔离级别可以解决数据完整性问题但它事实上没有. ” mysql 怎么误导你让你以为可以了?是它的文档,还是你想当然?
三、其次 repeatable read 隔离等级首先要做的是对已经查询的记录加上 lock 机制禁止更改, 而不是字面上的"可以重复读到一样的值" --- 否则我要你这个事务有何用?我干嘛读第二次?
再说 SQL-92 标准是允许 repeatable read 中出现 phantom read 的,但不允许读取过的记录被别的事务更改。
你这几句还是暴漏了你对 SQL92 标准中的“repeatable read”的理解有误呀
#61 楼 @sefier 建议你读一读对 sql-92 标准中的隔离等级的批评 http://www.cs.umb.edu/~poneil/iso.pdf 其中对数据库事务隔离等级做了更细致的定义,并加上了和 repeatable reads 很接近,但有细微区别的 cursor stability 和 snapshot 等级。mysql 的 repeatable reads 接近于里面描述的 cursor stability 等级 (因为它允许 read skew, write skew 和 lost update 的发生)
既然你用的 PG, 很多手动加锁的地方还是再思考一下的好,因为隔离等级和 mysql 的行为有微妙的不同,如果是自己多加的锁影响了性能就不要怪 PG 的事务慢了...
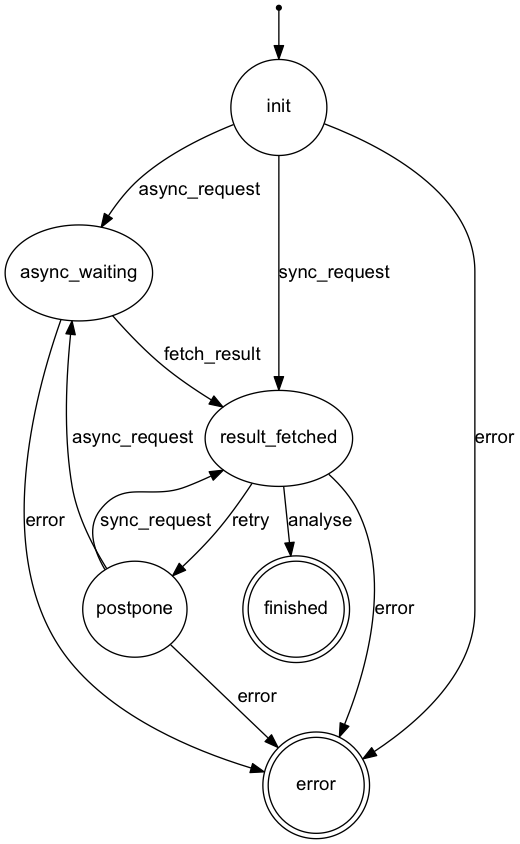
很有帮助的讨论,我最近写的东西是用异步队列 (sidekiq) 实现一个有依赖关系的任务序列 (即单个任务可能会依赖前置任务完成才能开始), 并且每个任务内部还有一个状态机,调用外部的异步服务。因为状态机的状态转移和外部服务调用没办法做成原子操作,所以最后还是要人为的给行加锁,用 with_lock(&block) 才解决了竞争问题。
所以结论是:在用数据库做强状态机的情况下,必须要先抢锁再运算。楼主的例子举的很不合适,如果真做金融相关的系统,性能和数据一致比起来,肯定是倾向于数据一致性的。
顺便 show 下状态机.... 感觉状态机相关的资料比较少,特别是很难找到状态机的设计最佳实践之类的东西,这个状态机设计成这样也是两个月里反复修改直到现在才成型的。