-
nil at 2018年03月20日
直传稍微有点不好的就是没办法做大小限制,再就是有时候云服务商回调的时候有存在回调失败的情况,之后就很难处理这种回调失败的数据
如果单传图片,或者不需要处理的文件,则直连非常好使
-
记录一次排查 Puma 内存占用过高的问题 at 2018年03月19日
哦?那我理解的 puma 的 threads 配置似乎是有问题了 有个 min max 同时我也看到了有些情况数据库连接突然的减少和增多 我还以为是回收和释放了呢
-
记录一次排查 Puma 内存占用过高的问题 at 2018年03月16日
thread 也是会回收的
-
分享__水。。从开发到上线 Rails 项目自动部署 at 2018年03月15日
capistrano 用的多一点
用 docker 也不赖
-
记录一次排查 Puma 内存占用过高的问题 at 2018年03月15日
我曾经也遇到过这个问题,
ruby 的 gc 我是这么理解的
每次内存使用完毕后,会标记为 可释放,但是什么时候释放,就得看 ruby 的 gc 和操作系统的释放条件了 我记得在某篇文章记得 ruby 启动有个参数可以控制 gc 的启动条件,也可以在编译 ruby 的时候写进去
ps 假设一次消耗 100M 按照题主的 puma 配置:4workers, 每个 worker 8~16 核 跑满就需要 4 * 16 * 100M = 6.4G, 但是 puma 我当时选择的是 worker 的工作方式,回收 threads 是要靠主线程的, 当主线程认为压力过大的时候,worker threads 是来不及销毁的,直接拿来处理下一条
如果是 4 cpus / 8G 内存,就刚好够用,但是如果这台机器跑了其他的东西,比如 db, redis 啥的,估计服务就挂了
我遇到的实际情况是
每台机器本身访问量在 1000rpm 之后我们有个黑白名单,名单本身不小,大概 2w 条,这些数据不稳定,易变。 之后写入的数据要过这个名单,过一次加上七七八八的计算,要 2 秒. 一个访问就消耗 20M 左右的内存,,但是这种过滤操作本身量不多 之后 puma 就占了 1.5 G, 2 cpus/4G 运行个 1-2 小时,服务器内存就到 85%, 当时研究了好久,最后发现 puma 开的 threads min 和 max 都设置的 30.
后来一算 觉得 thread 似乎很不合理,网站大部分数据是在 30ms 之内就请求完的, 其实我平均每个访问控制在 100ms,10 个 threads 在每个 worker 下, 这样 2 workers 我就可以承受 6000rpm 的访问, 之后我就修改了 threads 成为 min 5 max 15, killer 设置成 1.5 G 内存,90% 启用,基本很少看到 killer 运行
-
[成都] Abovegem 招聘 Ruby On Rails 工程师 at 2018年03月12日
西南地区的 ruby 都集中在成都啊 重庆好荒凉的感觉
-
调查显示编程语言 Ruby 在缓慢衰落,缺少爆发点 at 2017年12月22日
现在用第三方服务,都是直接看 rest api 之后自己实现成 gem。。。
-
SSL_connect SYSCALL returned=5 errno=0 state=SSLv3 read server hello A (OpenSSL::SSL::SSLError) 错误,求大佬指教! at 2017年11月23日
如果实在不行 但是又非常有必要访问 这招 通吃 但是 ssl 的意义就没了
require 'openssl'
OpenSSL::SSL::VERIFY_PEER = OpenSSL::SSL::VERIFY_NONE
-
SSL_connect SYSCALL returned=5 errno=0 state=SSLv3 read server hello A (OpenSSL::SSL::SSLError) 错误,求大佬指教! at 2017年11月20日
少年 阿里 centos 6.x 吧?升级下你的 openssl
-
已经熟练掌握 Rails,准备进军人工智能、深度学习,感觉到很困难 at 2017年11月18日
我最喜欢在简历上看到“熟练掌握” 、 “精通”
-
SendGrid 配置到怀疑人生 at 2017年09月28日
一般来说 包括发送的数量级 邮件组 规则等
-
Rake Task 突然猝死的原因应该从哪里找起? at 2017年09月28日
哟 爬虫扒视频啊 记得设置 timeout
-
今天上午在 bundle install 时候发生报错 at 2017年07月10日
更新可能是故障了,我也是出这个东西
-
这是一个非常有趣的 Gem at 2017年07月04日
小哥 下次代码仓库可以不用提交 gem 本身的 本地调试的话,直接使用
rake install即可
要推 gem 的时候rake build, 之后在 pkg 文件夹下面找
记得把 pkg 写在 .gitignore 里xx 有你更精彩
-
这个域名 会跟 testin 打官司吧姐姐
-
TextMate 是不是淘汰了? at 2017年06月29日
从 atom 切到 visual studio code 几个月了,atom 太太太太太太太卡了 当然更别提 jb
-
Active Model Serializers 序列化耗时特别长 at 2017年06月29日
哥哥,配个 newrelic 看看你这个访问 调用了多少次数据库就知道了
-
rspec 和 minitest 哪个都 ok 初学无所谓 php 才是最好的语言
微信登录 mock 不好做 web mock 用 webmock 这个 gem
sidekiq 的 work 你就测 work 的逻辑就好了
-
[远程] 彩程知人招募工程师 (15 - 30k) at 2017年06月21日
很好奇 tower 这么大的体量的应用 应该是典型的 monolithic
是靠 Rails Engine 拆业务么
-
[远程] 彩程知人招募工程师 (15 - 30k) at 2017年06月20日
随便打听下 彩程微服务了么
-
使用 Ruby 进行混合云开发的小伙伴,一起来交流一下吧 at 2017年06月11日
写过控制 ali docker 和美团云的 可以交流下
-
在阿里云部署 Rails 时,总是出现:We're sorry, but something went wrong at 2017年06月06日
先检测 passenger 是否正常工作
我隐约记得 passenger 好像和 nginx 搭配要重新编译一下
不嫌弃的话 试试 puma
-
watir-webdriver 安装后,打开浏览器正常,然后再操作就报错了 at 2017年06月05日
这玩意对浏览器版本要求极其高
-
Routes 文件模块太多,想把定义的 admin、account、site 等等模块分别在不同文件里写,有方法吗? at 2017年06月05日
记着一条就行 routes.rb 本身也是 ruby 文件 遵守 ruby 的语法
-
git config credential.helper https://git-scm.com/docs/git-credential-store
-
Rails 编写的 API 能否测试和文档一起做?尝试了几个 swagger 相关 gem 都没成功 at 2017年04月25日
我们最开始使用 github 的 wiki 来写 markdown
但是经常忘记再修改完毕代码之后更新对应的 markdown 最终导致文档失效。我在想,能不能用 vcr 记录下集成测试的 json 值 一旦有变化,自动发钉钉什么的要求开发补完,否则项目状态就是红的,之后前端只使用状态为绿的的 api
-
使用 Subscriber 来管理 Model Callbacks [北京 Rubyists 活动分享] at 2017年04月01日
这是我上次说的 wisper 的方式
class Job ###... after_save :send_finished_info def send_finished_info if status_changed? && self.class.finished_statuses.include?(status) WisperBroadcast.new.broad_cast(:job_finished, self) end end # init 里 module RegisterObserver class << self def init Wisper.subscribe(QueueObserver.new) Wisper.subscribe(AgentObserver.new) Wisper.subscribe(MonitorQueueObserver.new) # ... Wisper.subscribe(MixpanelObserver.new) Wisper.subscribe(StarBranchesObserver.new) Wisper.subscribe(DingTalkMessageObserver.new) end end end RegisterObserver.init之后就可以全局看到多少人受到 job_finished 的影响了
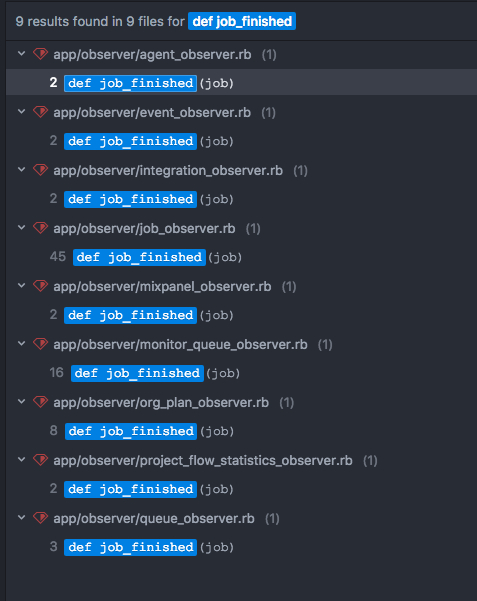
当然这种写法你最好不要在一个 observer 里再次 broadcast,如果你那样做,就跟 after_create 这种回调链没有区别了
-
想改变一点 at 2017年04月01日
淡定,我注册了 N 年,至今还开小号发新手问题

-
团队聊天工具,大家都用什么?Hipchat? 企业微信?还是 QQ? at 2017年03月23日
叮叮 自打机器人上线了之后 就忘记 slack 了
-
为 Rails 项目搭建 Jenkins CI 服务器 at 2017年03月23日
不闲付费的话可以试用我司 flow.ci 一键 ci 无需提供机器 push 自动跑测试