-
Rcer,Ruby China 第三方移动客户端 at April 09, 2019
哎呀 露脸了
-
记一次 Ruby 内存泄漏的排查和修复 at March 31, 2019
内存泄漏真的是超级超级难查
楼主辛苦了
-
记一次部署时出现 CSS FingerPrint 不一致的问题 at March 28, 2019
感谢刘老板赐教
-
记一次部署时出现 CSS FingerPrint 不一致的问题 at March 27, 2019
在官网上没找到相关内容呢 这个我还真不是太了解
-
Sidekiq 如何 load balance queue 和 worker at March 27, 2019
不要把分析 N 个公司作为一次原子操作,
建议把分析一个公司,变为一次原子操作
用那种加权方式 比如 A 客户等级是 100 B 客户等级是 10 , 之后 A 客户的一个企业分析权值就是 100, B 的一个企业分析一次分析就是 10
之后一个 true 循环这个大数组,每循环一次,数组里所有权值 + 1 , 之后再把权值最大的任务执行掉,拿出去。
这里的重点,是每检测循环一次,数组所有的权值 +1
这样,具有最高权值的任务就会优先执行,低权值的数据,也会因为遍历次数的增长,而变成高权值的数据,不至于在这个循环里没有执行的机会
-
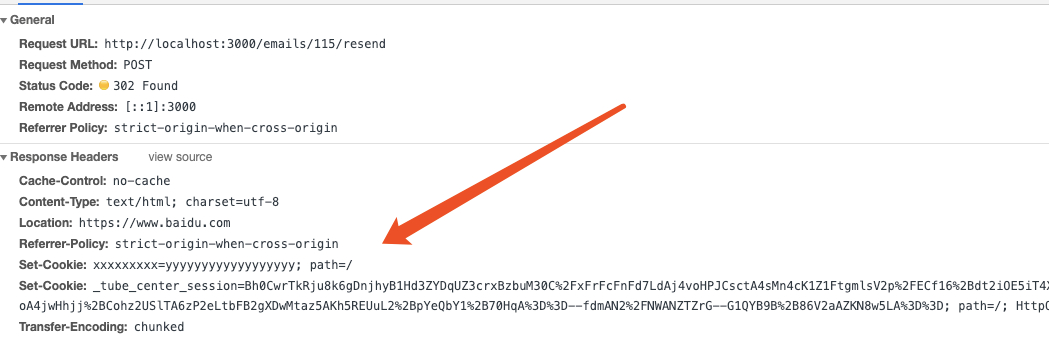
新手教程中 post 请求里 set cookie 为啥失败了 at March 25, 2019
我这刚试了 有呀
-
在搬瓦工 VPS 上个人项目部署后无法正常访问,Rails + Nginx + Passenger at March 25, 2019
bwg 用户路过,好像 bwg 不需要开 80 端口
http://23.105.196.112/ Connecting to 23.105.196.112:80... connected. HTTP request sent, awaiting response... 301 Moved Permanently证明 nginx 上 80 端口已经可以正常访问了
至于 ip 配置 443, 我这没听过给 ip 签名的,理论上证书是给域名签名的,而不是给 ip 地址签名,证书的 CA 那块不会过吧
我个人建议新手可以用 nginx + puma 的方式 至少不用编译 nginx ,免得带来各种麻烦
nginx 的配置你可以参考下 capistrano puma (https://github.com/seuros/capistrano-puma)
里面有一个 nginx 的自动配置
cap production puma:nginx_config要是纯新手,只要使用 ubuntu apt 安装的 nginx, 不需要做其他配置
看到新人学习 rails 真好
-
[CVE-2019-5418] Rails 路径穿越 任意文件读取 at March 20, 2019
只有一个废弃的项目用了 render file
-
关于 机器 TIME_WAIT 过多的问题的请教 at March 19, 2019
有两台机器实际上,A 和 B 都有 Puma, A 有 nginx
A 的 nginx 的 upstream 分别到 A 和 B 的 PUMA 上
我也觉得 2000 多还好,
local_port 不改也有 2w-3w, 目前肯定是够用
主要还是怂
因为这个项目的业务逻辑关系,流量特别不稳定,经常瞬发 10x 平日流量,我怕到瓶颈再想办法就比较麻烦了
其实我觉得开一下 tcp_tw_reuse 应该问题不是太大,就算占满了都有解
总之 感谢 @early @quakewang
-
关于 机器 TIME_WAIT 过多的问题的请教 at March 19, 2019
upstream api_production { server 172.16.0.13:3001 fail_timeout=0; server 172.16.0.12:3001 fail_timeout=0; keepalive 500; } server { listen 80; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "Upgrade"; proxy_set_header X-Forwarded-Proto http; listen 443 ssl; ssl_certificate /root/.acme.sh/fullchain.cer; ssl_certificate_key /root/.acme.sh/key; add_header Strict-Transport-Security "max-age=31536000"; root /var/www/api/current/public; try_files $uri/index.html $uri; location /api { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $host; proxy_redirect off; proxy_pass http://api_production; } location / { rewrite ^/(.*)$ /api/$1 last; proxy_pass http://api_production; } -
关于 机器 TIME_WAIT 过多的问题的请教 at March 19, 2019
这个开过,开过常用的 16 和 500 没有什么明显的效果似乎
-
关于 机器 TIME_WAIT 过多的问题的请教 at March 18, 2019
主要都是 puma 端口上的 TIME_WAIT
tcp 0 0 172.16.0.13:3001 172.16.0.13:58594 TIME_WAIT tcp 0 0 172.16.0.13:3001 172.16.0.13:34790 TIME_WAIT tcp 0 0 172.16.0.13:3001 172.16.0.13:57166 TIME_WAIT tcp 0 0 172.16.0.13:3001 172.16.0.13:34378 TIME_WAIT tcp 0 0 172.16.0.13:46242 172.16.0.12:3000 TIME_WAIT tcp 0 0 172.16.0.13:3001 172.16.0.13:60220 TIME_WAIT tcp 0 0 172.16.0.13:3001 172.16.0.13:32940 TIME_WAIT tcp 0 0 172.16.0.13:3001 172.16.0.13:59416 TIME_WAIT tcp 0 0 172.16.0.13:3001 172.16.0.13:57810 TIME_WAIT tcp 0 0 172.16.0.13:3001 172.16.0.13:35356 TIME_WAIT tcp 0 0 172.16.0.13:33226 172.16.0.13:3001 TIME_WAIT tcp 0 0 172.16.0.13:443 223.104.94.24:53306 TIME_WAIT tcp 0 0 172.16.0.13:3001 172.16.0.13:35066 TIME_WAIT tcp 0 0 172.16.0.13:3001 172.16.0.13:58744 TIME_WAIT tcp 0 0 172.16.0.13:46138 172.16.0.12:3000 TIME_WAIT tcp 0 0 172.16.0.13:3001 172.16.0.13:60702 TIME_WAIT tcp 0 0 172.16.0.13:3001 172.16.0.13:35518 TIME_WAIT tcp 0 0 172.16.0.13:3001 172.16.0.13:60944 TIME_WAIT tcp 0 0 172.16.0.13:3001 172.16.0.13:57132 TIME_WAIT tcp 0 0 172.16.0.13:3001 172.16.0.13:60464 TIME_WAIT tcp 0 0 172.16.0.13:47050 172.16.0.12:3000 TIME_WAIT tcp 0 0 172.16.0.13:443 117.136.63.83:14588 TIME_WAIT tcp 0 0 172.16.0.13:50070 172.16.0.12:3000 TIME_WAIT tcp 0 0 172.16.0.13:3001 172.16.0.13:34458 TIME_WAIT tcp 0 0 172.16.0.13:3001 172.16.0.13:33596 TIME_WAIT tcp 0 0 172.16.0.13:3001 172.16.0.13:35192 TIME_WAIT tcp 0 0 172.16.0.13:3001 172.16.0.13:60730 TIME_WAIT tcp 0 0 172.16.0.13:3001 172.16.0.13:59854 TIME_WAIT tcp 0 0 172.16.0.13:3001 172.16.0.13:59854 TIME_WAIT -
渐进式迁移到现代前端开发模式 — 用 Webpacker 替代 Sprockets 实现前端资源的管理 at March 11, 2019
哈哈 在 medium 也看过一篇 https://medium.com/@coorasse/goodbye-sprockets-welcome-webpacker-3-0-ff877fb8fa79
只不过 rails 6 就默认 webpacker 了
-
Docker 安装 homeland,邮件配置 smtp 后,收不到邮件 at December 12, 2018
阿里云默认不开放 25 端口
-
做个小小的调查,有多少用 Rails 做服务器后端 API 的? at November 26, 2018
rails-api 3 年多
-
Ruby 的好朋友 -- jemalloc at October 31, 2018
使用会带来啥风险呢?
-
MongoDB 日志处理 at August 08, 2018
少年 你需要 logrotate
-
服务器被 CC 攻击一般大家怎么处理 at July 25, 2018
哈哈哈 我最近也被 cc + ddos
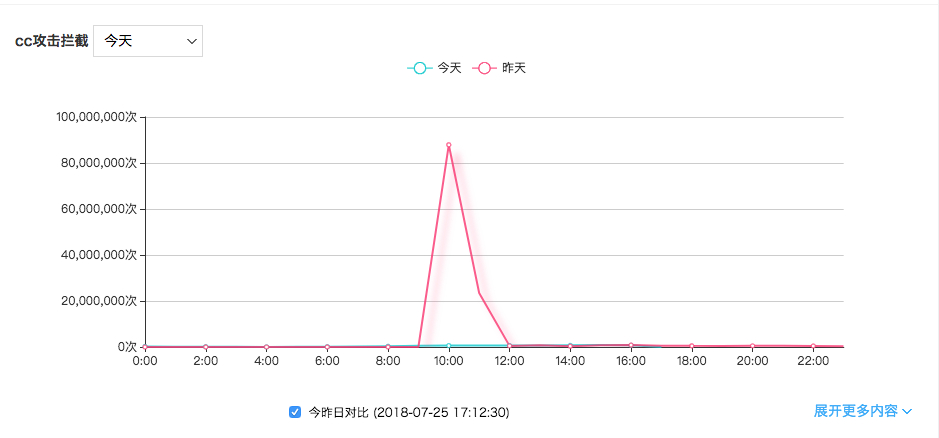 cc 问题都不大 主要是怕 ddos
cc 问题都不大 主要是怕 ddos另外 cc 一般会有大量的是国外的 ip 发过来的
如果是国内业务,可以用智能 dns 把这些国外节点访问弄走
-
[已解决] V2EX 挂了? at July 16, 2018
我就知道会有这个帖子.....
-
招聘困难 at June 20, 2018
这是个炫耀贴
-
capistrano 问题 狗子在这先说声谢谢 麻烦来会的教一下 at May 22, 2018
你需要了解 link_files 和 link_dirs 的意义
他们的意义是在于
你的开发环境和你的部署环境是有不同的 这样的话 如果全都上传到部署环境 (包含配置), 是会出问题的 (比如 database.yml 或者 application.yml 等)
于是 在你部署的时候,部署的版本的这些文件,可以用 link_files 或者 link_dirs (目录) 代替 (使用 ln 软连接的形式)
这些软连的地址,是需要在服务器上的,你需要先 ssh 到你的服务器,建立这些文件 (文件夹) 写上相应的内容
如果你的服务器所用的配置与你的开发完全一致 (不建议) 其实你是可以干掉 link_files 和 link_dirs 的
-
关于一次新部署使用 rails db:schema:load 的问题 at May 21, 2018
Capfile 里可以关闭 migrate
注释掉 require "capistrano/rails/migrations"
-
rails 中的 redis 集群问题。 at May 09, 2018
-
rails 中的 redis 集群问题。 at May 09, 2018
会投票
-
社区里导航的 优质帖子 的筛选逻辑是不是有点问题? at May 06, 2018
嗯呐 已经 提了 pr
https://github.com/ruby-china/homeland/pull/1032 -
Whenever 每 20 秒执行任务 at May 04, 2018
xxx 那里 做一个异步处理 交给 active_job 处理
或者就像 @w7938940 同学说的那样 用 sidekiq-scheduler
-
如何优雅的在 rails 动态的添加表单项目 at April 30, 2018
使用 cocoon 的时候注意下,他是直接在页面显示的时候就把 subform 的信息加载进来了,也意味着,如果你在 subform 上有 after_initialize 的话 它只生效一次 (随机,时间戳 都是在页面生成的时候出现,再添加 sub model 时就只是加载 js 里的信息 )
-
Rails 5.2 中的 Credentials 和 Active Storage at April 29, 2018
凑巧最近两天试了 active_storage. 如果是使用直传的话需要注意一下 cors 的限制,
aws 以及类似的服务 (digitalocean 的 spaces),在设置 bucket 的 cors 的时候 ,需要将域名允许跨域,且其 headers 允许里加入* 后才行.(我是在 digitalocean 测的,他的 cors custom headers 似乎只能配* 而不能配置 aws-*)
ps 我觉得最炫酷的还是提供不同 storage 的同步功能。
-
Rails 静态资源编译 at April 23, 2018
楼上正解
如果是用 capistrano 部署的话 记得在 Capfile 里把 precompile 拿掉
-
[上海] 薄荷科技再招聘 Ruby 小伙伴 at April 19, 2018
哈哈,去上海了呀