-
用 kamal 部署 rails 至阿里云主机总结 at 2026年04月13日
-
没买海外 vps 时如何解决 kamal deploy 的 EOF 问题 at 2026年03月19日
搭了,但是 kamal-local-docker-container 会很神奇的绕过我路由器分配给他的 dns 之后再被墙
-
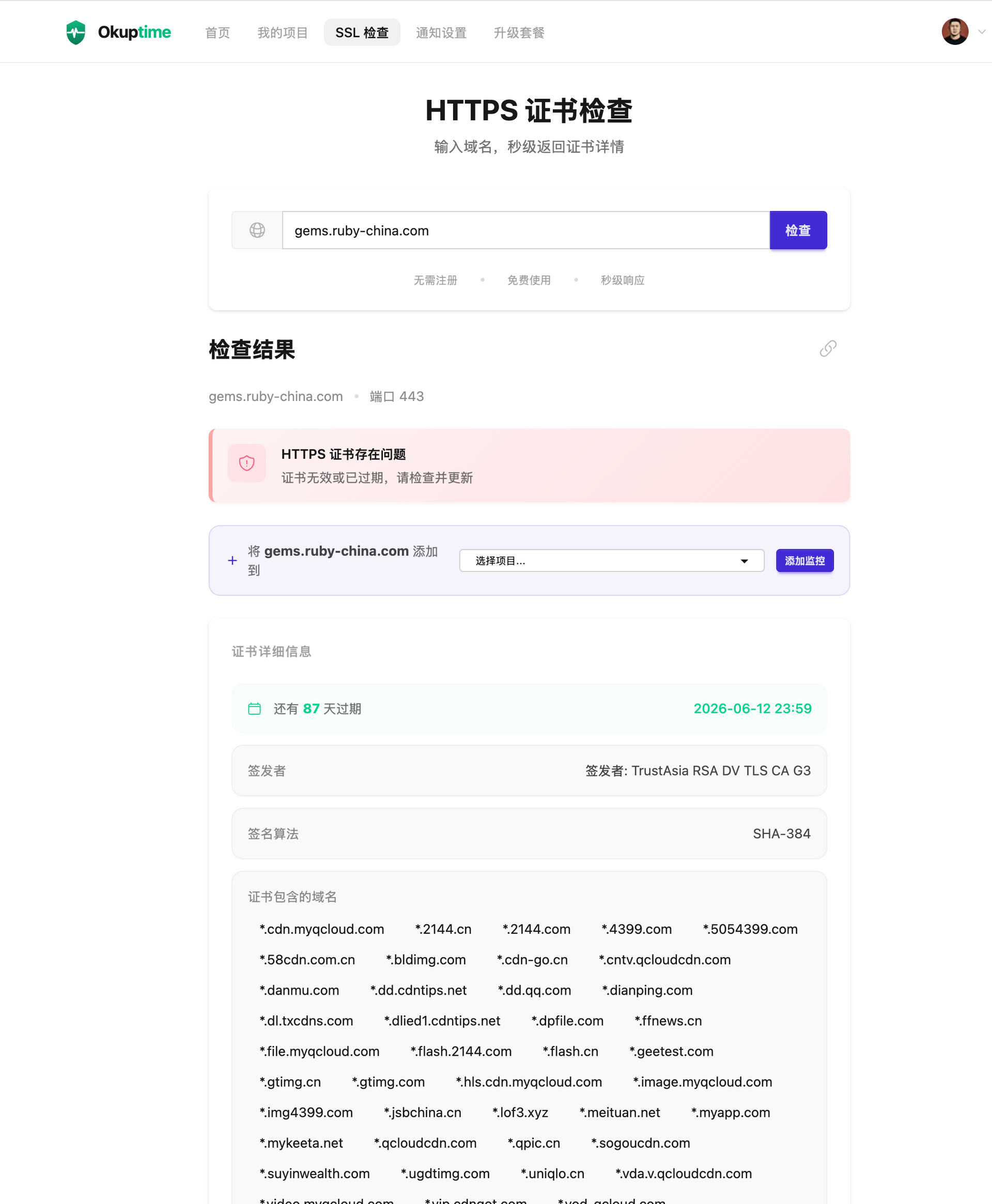
https://gems.ruby-china.com/ 变茶壶了 at 2026年03月18日
要么被抓进去了.... 不至于吧朋友
-
发现 Rails 在 AI 时代好像挺适合做实验性质的项目的 at 2026年03月13日
-
2026 年国内 AI Coding Plan 怎么选?5 大平台横评帮你省钱 at 2026年03月11日
这个时候 我就要推荐 CC switch 了 https://github.com/farion1231/cc-switch
-
https://gems.ruby-china.com/ 变茶壶了 at 2026年02月28日
-
听歌用 铜钟 Tonzhon,写 Ruby 牛逼哄哄! at 2026年01月23日
兄弟 这种比较怕律师函....悠着点
-
Ruby 的 TUI 庫 Ratatui-Ruby at 2026年01月22日
记得 2025 的 rubychina 大会由个研究 cli ui 的大哥 大家都好有创造力
-
🚀 AnyCable + RubyLLM + Sidekiq,一个教学友好的 ChatGPT 聊天室示例 at 2025年06月18日
哈哈 冲他 100 块的 key 够玩很久了
-
有朋友在国内服务器上通过 Kamal 成功部署 Rails 应用吗? at 2025年03月31日
这个我有经验:
一般是两个问题:1. 产物镜像无法拉取 我用阿里云的 私有仓库解决。2 无法拉取 kamal-proxy,我是直接导出 kamal-proxy 镜像再在 server 上安装
-
How SDB Scans the Ruby Stack Without the GVL at 2025年02月11日
哎 人与人之间的差距太大了 看不明白
-
入门 blog 项目点击 destroy 没有反应没有窗口怎么解决? at 2025年01月09日
所以我现在比较喜欢原生
-
什么时候业务逻辑放在 concerns? at 2025年01月09日
我是比较喜欢放 concern 的 我一般是这样 某个 model 的根据功能划分,比如 student 里 关于考试成绩的相关操作,放一个 concern 之后 选课相关的 再放另一个 concern 之后 include 进来
-
入门 blog 项目点击 destroy 没有反应没有窗口怎么解决? at 2025年01月09日
巧了不是 gorails 最近的视频 就是讲如何不用 js 在 form 里面 实现一次 delete 的 another form 的操作
<%= form_with model: product do |form| %> <%# rest of the form ... %> <div> <%= form.submit %> <%= button_tag "Delete", form: :delete_product %> </div> <% end %> <%= form_with model: @product, method: :delete, id: :delete_product, data: { turbo_confirm: "Are you sure?" } do %> <% end %这个实际是 使用的 html 的特性
我解释下,form 里面的 ButtonTag 会生成一个 Button 但是 由于有 form attribute 实际上他会触发另外一个 form(对应 id)的提交 (如果没有 form 这个 attribute 的话 点击按钮后,他会提交自身所在的这个 form )
之后这个另外的 form 你爱写哪里写哪里,只要在这个页面里就好
以上知识均为 html 知识,不涉及到 rails 本身
ps: 由于 form 的 method 是不支持 delete,所以实际上 底下那个 form 会生成一个 method 为 post 的 但是会在 form 里生成一个 hidden 的 input name 为 _method 值为 delete 这样当提交这个 form 的时候 rails 就会将这个 post 请求 等效于 delete 请求
-
现在用 importmap + stimulus 这套技术栈有什么好用的组件库? at 2025年01月07日
-
2024 年了,我还在用薄荷 18 年分享的 10 条最差实践建功立业😂 at 2024年12月12日
其实放到内存里 也有这么一个原因 就是 内存比网络快
读 redis 大概率是要跨网络的,会牺牲一定的性能,特别是你遍历数组的时候,每个 item 都要去缓存去拿一个很无聊的数据的时候,网络 io 就是需要考虑的问题了,包括内网
当然 其实绝大多数程序来说 没啥本质的区别 同时 用 redis 还有额外的收益 原子性
-
2024 年了,我还在用薄荷 18 年分享的 10 条最差实践建功立业😂 at 2024年12月07日
“数据库】发布前一定要检查 migration,大表手动处理”
可以试试 这个 gem https://github.com/ankane/strong_migrations
-
2024 年了,我还在用薄荷 18 年分享的 10 条最差实践建功立业😂 at 2024年12月07日
$local_cache = ActiveSupport::Cache::MemoryStore.new可以划分一块内存,来直接处理
之后默认 cache 是走 redis
但是注意哈,这个内存的缓存 只在 一个 puma 进程种共用
-
[广州][11-30] RubyConf China 2024 售票开始 at 2024年11月20日
买个周边支持一下
-
有没有人在国产操作系统上开发过 rails?数据库也用国产数据库 at 2024年11月18日
polardb?analyticsDB 囧 rz
国产数据库一般都兼容 mysql 或者 postgres driver 的 直接用就是了
-
求问 MAC M2 芯片 ruby on rails 连接 oracle 的办法 at 2024年11月01日
orbstack 装个兼容 amd64 的虚机 之后上面搞
-
为了庆祝【RubyConf China 2024】特意把之前的 Rails 高级程序员的课程做了免费发布 at 2024年10月24日
感谢兄弟的付出,ps,油管上传的话会有一点广告收益 可以考虑一下
-
Rails 开发者应该拥抱 Web Component at 2024年10月23日
-
【新手 Rubyist】聊聊大佬们是如何找到第一份 ruby 工作的 at 2024年10月22日
13 年用 yii 开发程序 听人说 yii 是借鉴的 rails 遂开始自己的项目试着拿 rails 写,接的小业务用 rails 1 个月就收钱了 关键是维护还继续找我
-
37Signals 的 Once#1 - Campfire 发布 at 2024年02月02日
299usd 考虑一下。。。
-
rails 7 我想同时使用 import map 和 jsbuilding,cssbuiding at 2024年01月31日
没有任何问题,可以直接用 jsbuilding 和 cssbuilding 只是一些胶水而已
他们的联系包括 开发时候的启动 以及 precompile 的时候的钩子,其他的都没区别了
-
GitLab CE 为什么需要如此高的配置 at 2023年11月09日
需要考虑到 gitlab 也是要赚钱的 毕竟就指望 saas 了
话说 极狐 今年也不容易 希望能走出来
-
使用 Kamal 部署 Rails7 项目,提示数据库域名无法解析 at 2023年11月07日
其实这也是我费解的地方 在我的想象当中 kamal 是用在多台机器上的部署
但是感觉连数据库都是直接通过公网 ip 连,而不是通过内网 ip
-
Rails 构建时下载 importmap 资源的方法 at 2023年11月07日
其实我倒是觉得 pin 加上--download 将 js 静态的提交到 vendors 没太大问题 下载的代码都是压缩过的
主要是国内现有网络条件下有时候并不能保证部署机能够 ready to download those js files,
不如砍掉这个依赖,在开发的时候就确定好。
-
使用 Kamal 部署 Rails7 项目,提示数据库域名无法解析 at 2023年11月06日
https://ruby-china.org/topics/43396 参见下我这个帖子里的回复 本质问题是 连 docker 里的数据库问题