Rails 记录一次排查 Puma 内存占用过高的问题
这几天上线一个 Rails 系统 ( 采用 rails-template 标准配置 ), 每分钟访问量在 500 ~ 1500 之间,但经常 puma 内存就上到 8G 以上,导致系统无法响应。
经过这两天的排查处理,现将思路整理如下,分享出来。
现象
ruby 版本:2.3.1
puma 版本:3.10.0
puma 配置:4workers, 每个 worker 8~16 核,数据库连接池 50
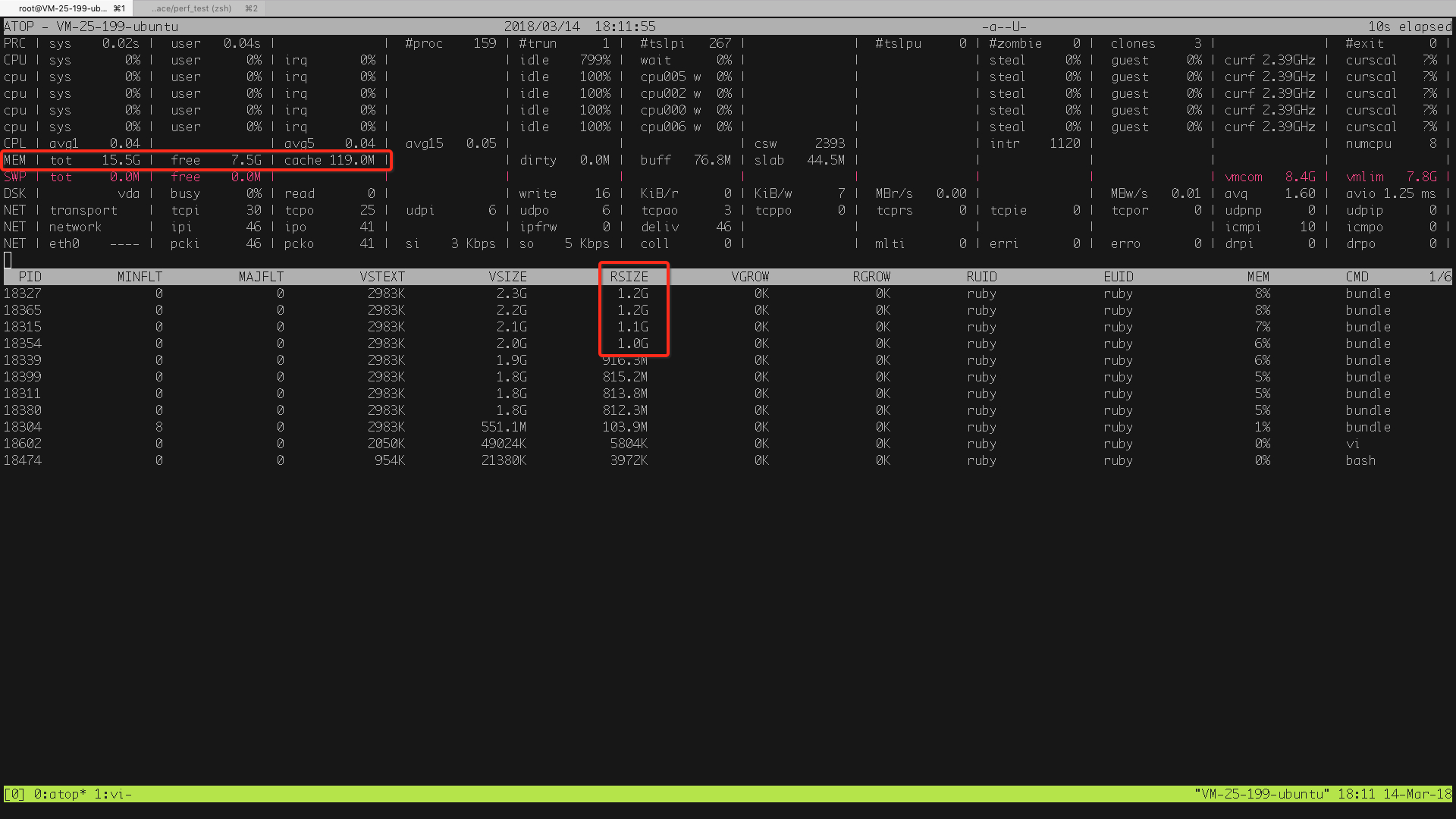
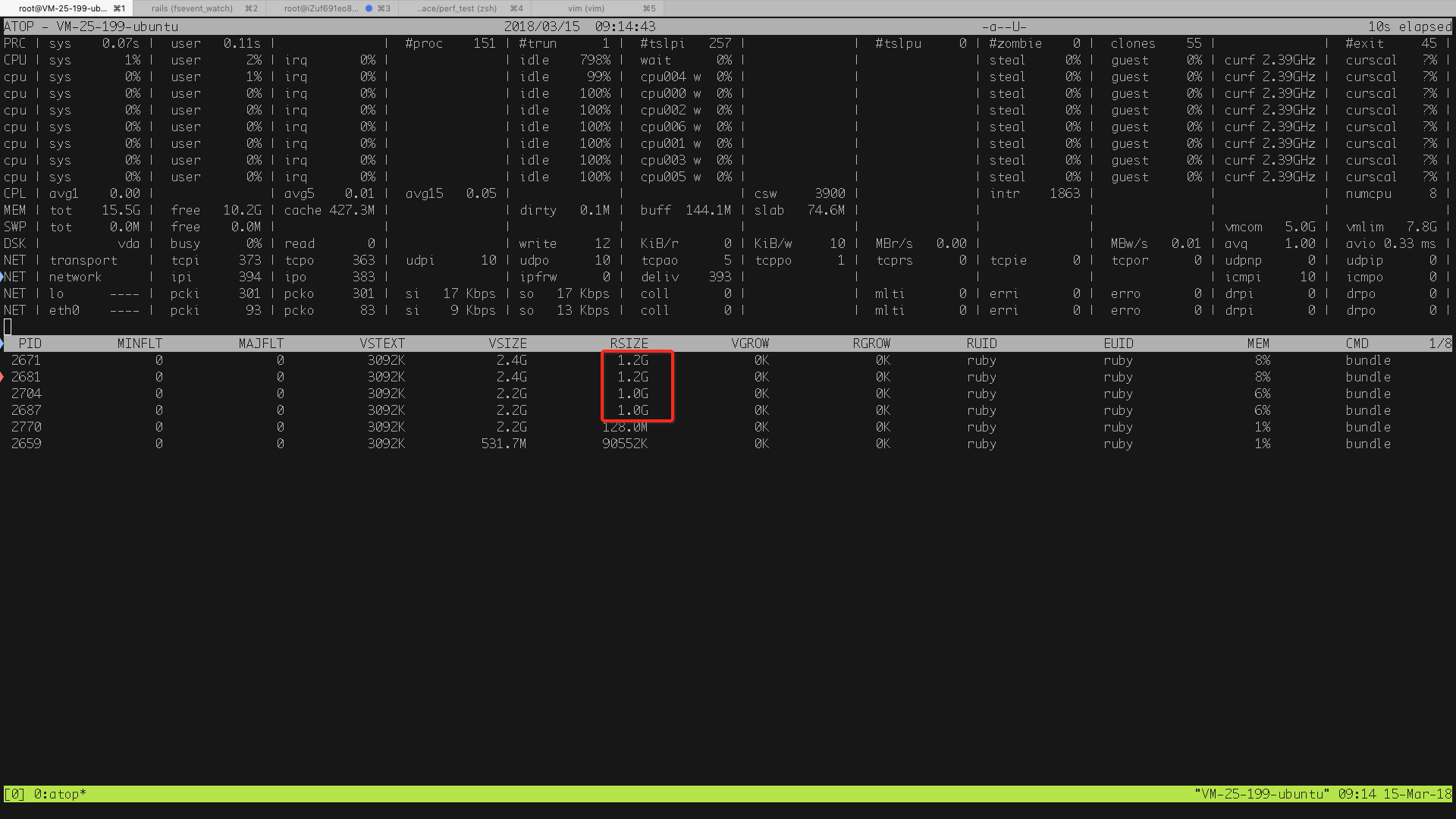
刚启动每个 puma worker 会申请 VSIZE 1.5G 左右,实际占用内存 (RSS) 100M, 然后在每分钟 500 用户访问下,占用内存会迅速到 1G 以上。
22:30 分

23:10 分

第二天下午 13:30 分

现象一:就算用户量下来,内存占用也不会下降。
现象二:更多的每分钟用户访问,例如提高到 1000, 占用内存会继续提高到 2G, 还会不断上涨至 3G. 这样,内存就会爆掉,导致系统无响应。
现象三:postgres 连接数会有 40 个左右,占用 5G 左右。
目标
为什么内存占用这么高,是否有内存泄漏。
每分钟用户数与内存占用之间的关系,是否可以优化 puma 的配置参数。
处理说明
思路一:代码是否有内存泄漏
通读所有控制器与模型逻辑,排查所有引用关系,并无发现引用变量不断开的情况。
思路二:是否与 puma 和 ruby 版本有关 ( 由于稳定性考虑的关系,并未更新至最新版本 )
考虑以下控制器代码
class HomeController < ApplicationController
def index
@a = '0' * 1024 * 1024 * 1000
end
end
每次请求占用 100m 内存,但正常来说,响应后应该释放。
测试一:使用 puma3.10.0 和 ruby2.3.1, 进行 wrk 的压测。
wrk -c 100 -d 30 -t 5 http://perf.80percent.io/ 导致 puma 吃满内存
测试二:使用 puma3.13.1(目前最新版) 和 ruby2.3.1, 进行 wrk 的压测。
wrk -c 100 -d 30 -t 5 http://perf.80percent.io/ 导致 puma 吃满内存
测试三:使用 puma3.13.1 和 ruby2.4.3, 进行 wrk 的压测。
wrk -c 100 -d 30 -t 5 http://perf.80percent.io/ 导致 puma 吃满内存
结果:与版本无关
思路三:是否是由 puma 本身导致的内存占用问题吗?
研读 puma 官方指导,调整 puma 的相关参数,尤其是 workers 与 threads 配置,并进行 wrk 与 siege 性能压测。
模拟实现一个请求时长 200ms, 消耗内存 100m 的接口,同时对其进行压测。
再切换至 unicorn( 另一个 rails 生态下成熟的 web 容器 ) 进行对照测试。
结果发现就算给到 16G 内存的机器,这样的接口也会让并发测试将内存吃满,不需要泄漏就有问题。puma 也不会主动释放其已经占用的系统内存.( unicorn 也类似 )
Running 30s test @ http://perf.80percent.io/
5 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 349.22ms 416.64ms 2.00s 85.27%
Req/Sec 52.77 42.76 370.00 68.15%
7081 requests in 30.06s, 47.07MB read
Socket errors: connect 0, read 10, write 0, timeout 247
Requests/sec: 235.56
Transfer/sec: 1.57MB
结论
最后,将 api 占用过高内存的问题解决后,整个 puma 内存占用问题就不存在了.
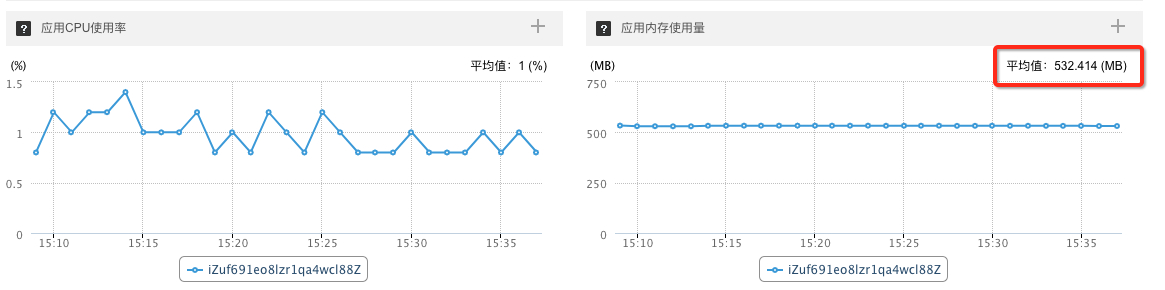
puma 和 unicorn 都不会主动降低操作系统内存占用,但会复用已经申请过的内存。所以会随着每分钟请求量的增加导致内存不断上升。如果超出某个极限,则有可能导致内存爆掉。可以考虑使用 puma_worker_killer 进行控制。
并发能力与每次处理用户请求所消耗的内存和响应时间成强正关系。本次的调查根因在于单次响应消耗内存过高导致内存不足。
额外发现,puma 的并发能力比 unicorn 强约 5 倍以上能力,而内存消耗两者相差无几。
经测试,puma 的配置建议是 N 核 N workers, 线程配置为 8~16, 测试的性能已经比较满意。
希望本文对大家有所帮助。有好的建议也欢迎提出交流。