-
Let's clone a Message Queue at March 25, 2019

-
Let's clone a Message Queue at March 25, 2019
- 实现机制不一样,que 使用的是 advisory locks,pgmq 使用的是 PostgreSQL 9.5's SKIP LOCKED feature.
- que 的实现是有问题的,参考:https://brandur.org/postgres-queues
- 其实 pgmq 的目标不止是做 background job,上面列表里的功能有一些只有 sidekiq pro 才提供,但其实对于一些应用非常有必要
- 还有就是 pgmq 可以其他语言使用的,不局限在 Ruby 上
-
Sidekiq 如何 load balance queue 和 worker at March 23, 2019
-
Sidekiq 如何 load balance queue 和 worker at March 22, 2019
urgent_client 单独启一个 worker 咯
-
Simple fuzzywuzzy with plsql at February 28, 2019
fuzzystrmatch 是 default,但和这个还是有点差异
-
Postgres Fulltext Search (一) at February 27, 2019
fixed.
-
Simple fuzzywuzzy with plsql at February 27, 2019
release as a pg extension: https://github.com/hooopo/pg-fuzzywuzzy
-
在 Rails 中使用 PostgreSQL 的全文搜索功能搜索百万条记录的表的正确姿势 at February 26, 2019
后面两个没利用到 idx 啊
在上例中,我是需要同时对这两列创建一个新的 tsvector 的列并加索引吗?
你的过滤条件是什么,就在上面加表达式索引就好了,其实没必要加一个 tsv 列,还需要去同步。
继续使用 pg_search 的话,其实你完全可以冗余一个列叫 title_and_desc,然后和单字段一样的做法。
-
在 Rails 中使用 PostgreSQL 的全文搜索功能搜索百万条记录的表的正确姿势 at February 26, 2019
你要把 sql log 和 explain 发上来,web 请求的截图没用啊
你的需求其实直接搜
title || desc就可以了 -
为什么很多 Ruby Gem 命名都已 Active 开头? at February 04, 2019
acts as xx
-
Let's clone a Leancloud at February 01, 2019
不会很大,可以 sharding 的
-
我自己的一个帖子不知为何打不开了 at February 01, 2019
你可以拼出 edit 链接的
-
Let's clone a Leancloud at February 01, 2019
都重要,baas 主要就三点,schemaless 存储,云服务需要,但私有部署的不需要,比如 husura,serverless 其实是用来实现复杂业务需求的,另一个就是 ACL or RLS.SDK 或文档任何云服务都需要的
-
我自己的一个帖子不知为何打不开了 at January 31, 2019
遇到神奇 bug 了
-
关于使用 Postgres 的疑问 at January 23, 2019
from twitter:
Me 5 years ago: Use services oriented architecture for all your code!
Me 3 years ago: Use CQRS/ES for all your code!
Me now: Just use PostgreSQL
https://twitter.com/hubertlepicki/status/1073229975254392832
-
关于使用 Postgres 的疑问 at January 23, 2019
pg 是用了就回不去的存在
-
推荐一个简单有效的减肥方法:生酮饮食 at January 22, 2019
为什么可以吃西红柿却不可以吃水果
-
It's never too late to learn Postgres at January 11, 2019
😂
-
PostgreSQL 构建通用标签系统 at January 11, 2019
这个就要写长文批判了
-
PostgreSQL 构建通用标签系统 at January 11, 2019
搜索替代不了标签吧,多肽确实反模式,但 Rails 里方便…
-
It's never too late to learn Postgres at January 11, 2019
比不上 es 是肯定的 但也够用
-
It's never too late to learn Postgres at January 10, 2019
负载是什么
-
[Japanese Not Needed] Android and/or iOS developer in Shibuya, Tokyo at January 10, 2019
English needed?
-
如何生产唯一数据可以混淆后得到 Int 小于 4294967295 ? at January 08, 2019
搜 scatter_swap obfuscate_id
-
如何生产唯一数据可以混淆后得到 Int 小于 4294967295 ? at January 08, 2019
最近用 Pg 实现了一个 Instagram Style ID,可供参考,32 位的 integer 也差不多,只不过碰撞几率就大了:
bigint 范围 -9223372036854775808 到 9223372036854775807,9223372036854775807 也就是:
select 9223372036854775807::bit(64); bit ------------------------------------------------------------------ 0111111111111111111111111111111111111111111111111111111111111111把 64 位的 bigint 分三段,第一段是 41 位 bit 的时间(可存 69 年),第二段是 13 位的 shard_id(可存 8191 个),第三段是 10 个 bit 的自增序列(可存 1024 个)
time | shard | seq -------------------------------------------+---------------+------------ 11111111111111111111111111111111111111111 | 1111111111111 | 1111111111一年的毫秒数:31556952000,所以,41 位的 bit 可以存 69 年。
select b'11111111111111111111111111111111111111111'::bigint / 31556952000; ?column? ---------- 6913 位 bit 的 shard_id:
select b'1111111111111'::bigint; int8 ------ 819110 位的自增 seq:
select b'1111111111'::bigint; int8 ------ 1023所以,每毫秒每个 shard 可以产生 1023 个唯一 ID。
代码:
def change execute("create schema id_pool") execute("create sequence id_pool.table_id_seq") execute(<<~SQL) CREATE OR REPLACE FUNCTION id_pool.next_id(OUT result bigint) AS $$ DECLARE our_epoch bigint := 1546300800000; /* 2019-01-01 单位ms */ seq_id bigint; now_millis bigint; shard_id int := 1; BEGIN SELECT nextval('id_pool.table_id_seq') % 1024 INTO seq_id; SELECT FLOOR(EXTRACT(EPOCH FROM clock_timestamp()) * 1000) INTO now_millis; result := (now_millis - our_epoch) << 23; result := result | (shard_id << 10); result := result | (seq_id); END; $$ LANGUAGE PLPGSQL; SQL endinstagram article: http://instagram-engineering.tumblr.com/post/10853187575/sharding-ids-at-instagram
-
关于 ElasticSearch 排序的问题 at January 04, 2019
用 pg 还真能实现,es 嘛就算了,得引 groovy script
-
关于 ElasticSearch 排序的问题 at January 04, 2019
PM 是实习生吗
-
Let's clone a Leancloud at January 02, 2019
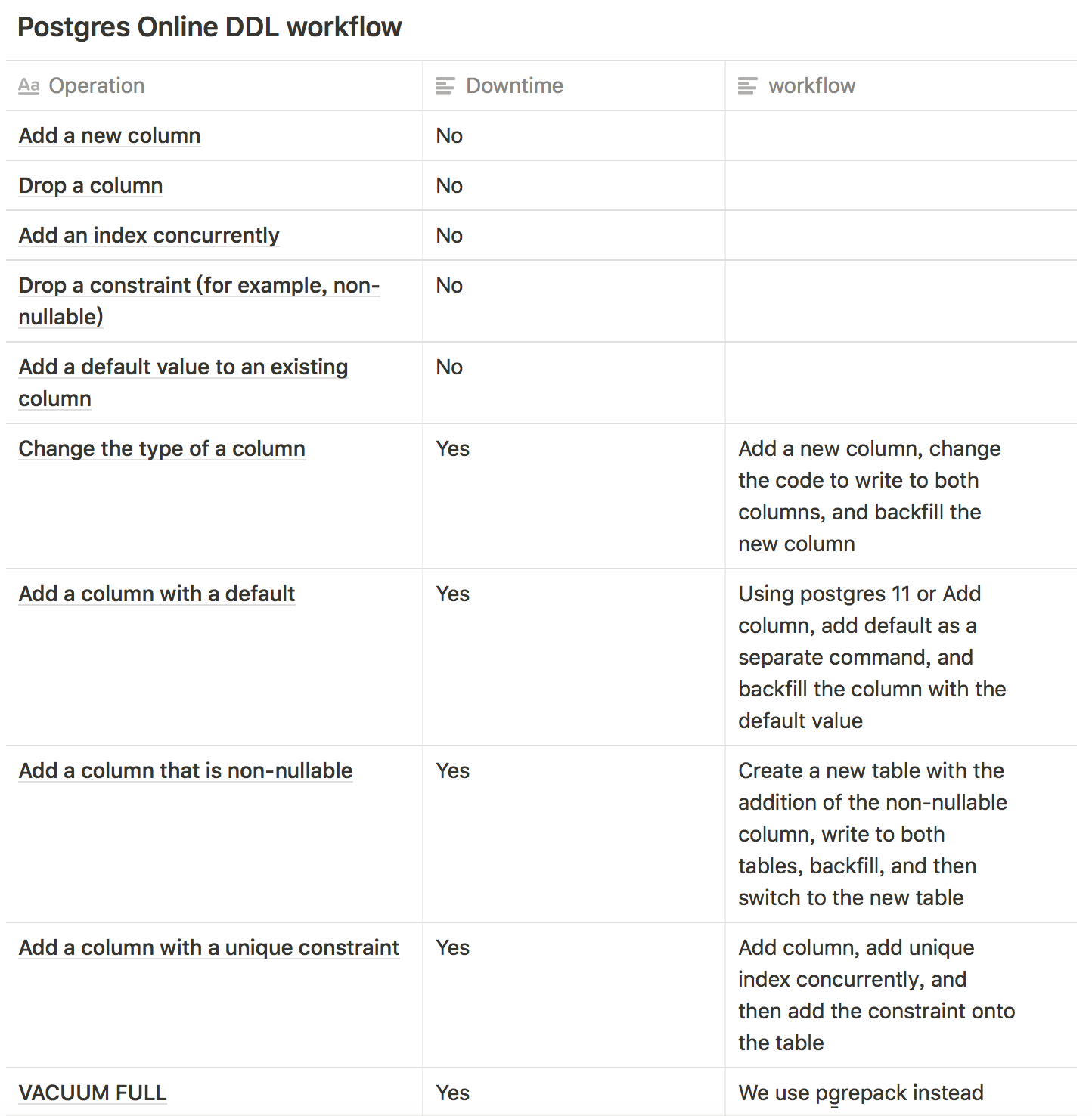
感觉可以不用 view 了,jsonb 也不需要了,直接动态创建一个 table,反正 pg 的增加和删除 column 是不锁表的,限制 alter column type 之类就行...
-
[东南亚] 招聘 Ruby 工程师 at December 30, 2018
公司名称是什么