新手问题 Sidekiq 如何 load balance queue 和 worker
大家好,我还是新手,来询问一个关于 sidekiq 和 redis 相关的问题 我现在遇到一个难题,现在的项目做公司分析 平均一个公司分析大概耗时 40 秒,我们把它放在 sidekiq 里 后台执行。 每一个客户可以有很多公司分析. 问题来了,
第一种情况 : 如果客户 A 开启 1000 个公司分析.,另外客户 B 在 1 分钟后开启一个公司分析.,那么我们不想要客户 B 等客户 A 分析完 1000 个公司,然后再分析客户 B 的单个公司分析。 我的提议的使用两个不同的 queue
queues:
- [normal_client, 20]
- [urgent_client, 40]
这样客户 B 就能先插队
第二种情况 : 如果客户 A 开启 1000 个公司分析,另外客户 B 在 1 分钟后也开启 100 公司分析,这样我们不希望客户 B 的 100 个公司分析要等到客户 A 的 1000 个公司分析 之后,我希望找一个好的解决方案,比如客户 A 和客户 B 交互分析,客户 A 分析一下,然后客户 B 分析一下,这样大概 客户 A 分析完前 100 个客户的时候,客户 B 的 100 也要分析完毕。 这种情况下该如何设计 queue, 或者如何设计如何把 job 放进 worker 里?或者前面再来一层数据结构?
第三张情况: 我希望每个客户都能有大概时间等待现实,现在不止两个客户,我们假设有很多客户,每个客户有不同数量的公司分析,如果 客户 A 开始分析 , 然后 客户 B C D etc.. 开始 插队。那势必导致客户 A 不断延长他的等待时间,这将造成我们刚开始给客户 A 的等待时间不断延长,这将到底客户 A 的不信任感,客户 A 会想,我可是你们的大金主,什么阿猫阿狗都能插我的队! 那这种情况下该有什么好的解决方案?
这个帖子 我想和大家探讨学习。 先提前感谢大家

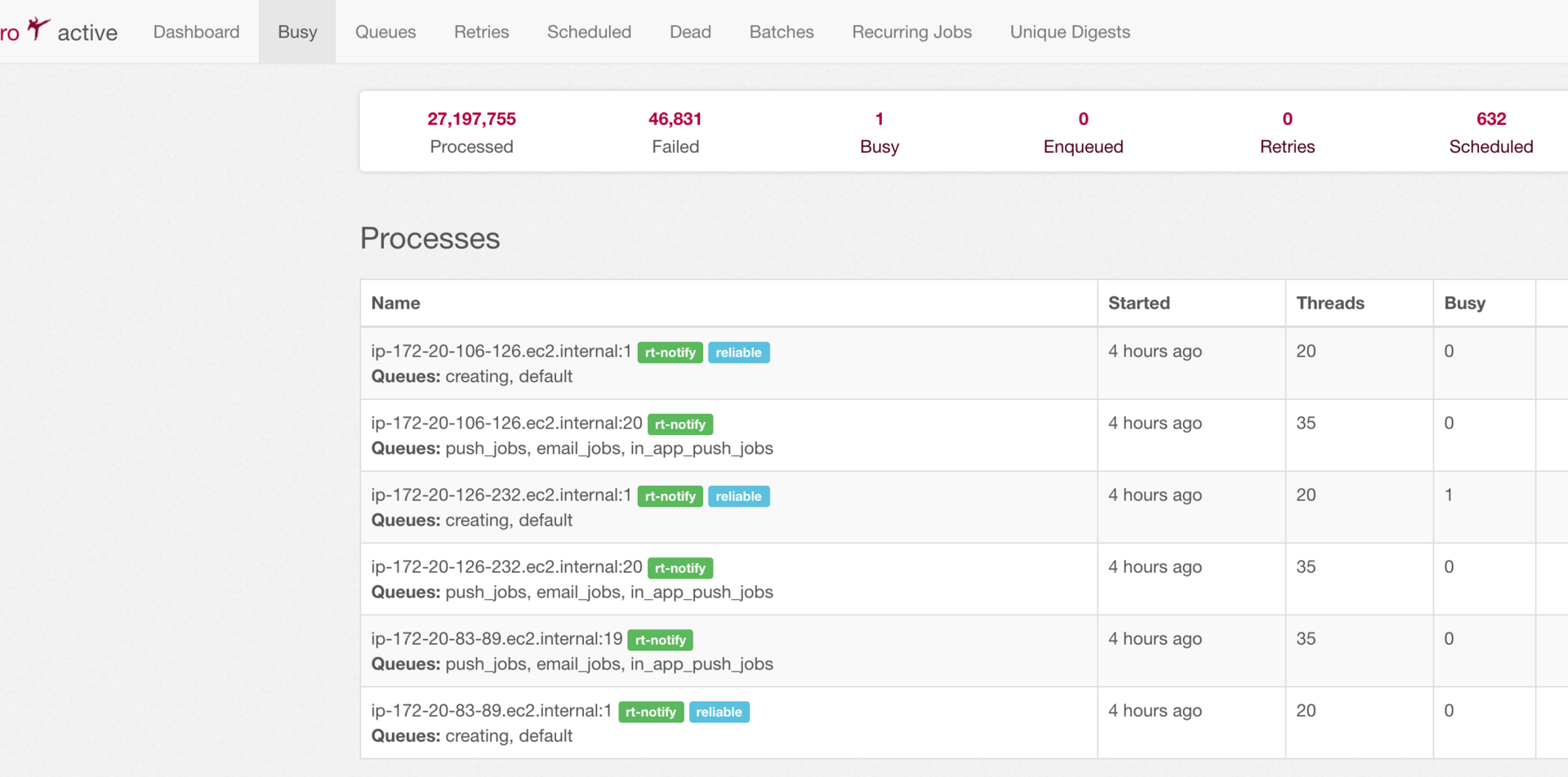 多起几个进程,每个进程可以有不同的配置,我们每个 docker container 起两个 sidekiq 进程,
多起几个进程,每个进程可以有不同的配置,我们每个 docker container 起两个 sidekiq 进程,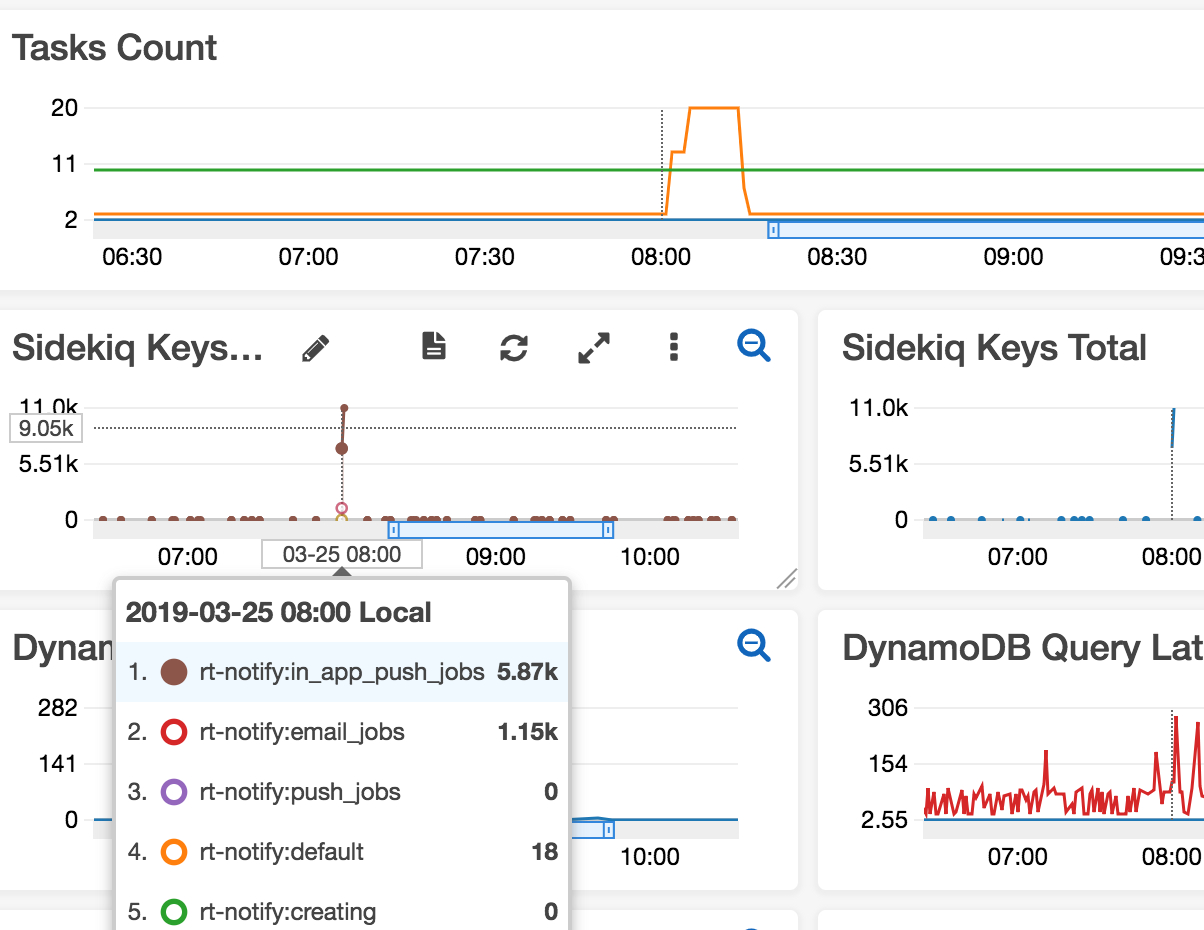 如果你的服务器一下子来了很多任务 你都希望尽快完成,那你就需要考虑 auto scaling,我们有个定时任务 定时去 redis 里查 有多少个 key,如果某个 queue 里的 key 增加到一定数量就会触发 增加服务器,启动更多的 sidekiq 进程。Task Count 就是服务器数量,key 少了就减少服务器。自动扩展需要考虑数据库 max connection,设置个服务器上限和下限。
如果你的服务器一下子来了很多任务 你都希望尽快完成,那你就需要考虑 auto scaling,我们有个定时任务 定时去 redis 里查 有多少个 key,如果某个 queue 里的 key 增加到一定数量就会触发 增加服务器,启动更多的 sidekiq 进程。Task Count 就是服务器数量,key 少了就减少服务器。自动扩展需要考虑数据库 max connection,设置个服务器上限和下限。