本帖已被管理员设置为精华贴
通常开发者会有一个常识,就是关系型数据库很难实现“动态列”之类需求。比如金数据这种,或 leancloud 和 firebase 这种。
最近做了一个实验性的尝试,用 Postgres 实现一个类似 leancloud 这种存储。主要需求大概如下:
- 可以建模和存储动态类型的数据,这个是基本要求
- 支持丰富的数据类型,包括:int、float、array、point、json、string、text、range 等
- 可以关联不同动态表
- 可以高效检索和匹配
- 可以高效排序
- 可以结合流行 BI 工具生成报表
- 可以全文检索
- 可以横向扩展
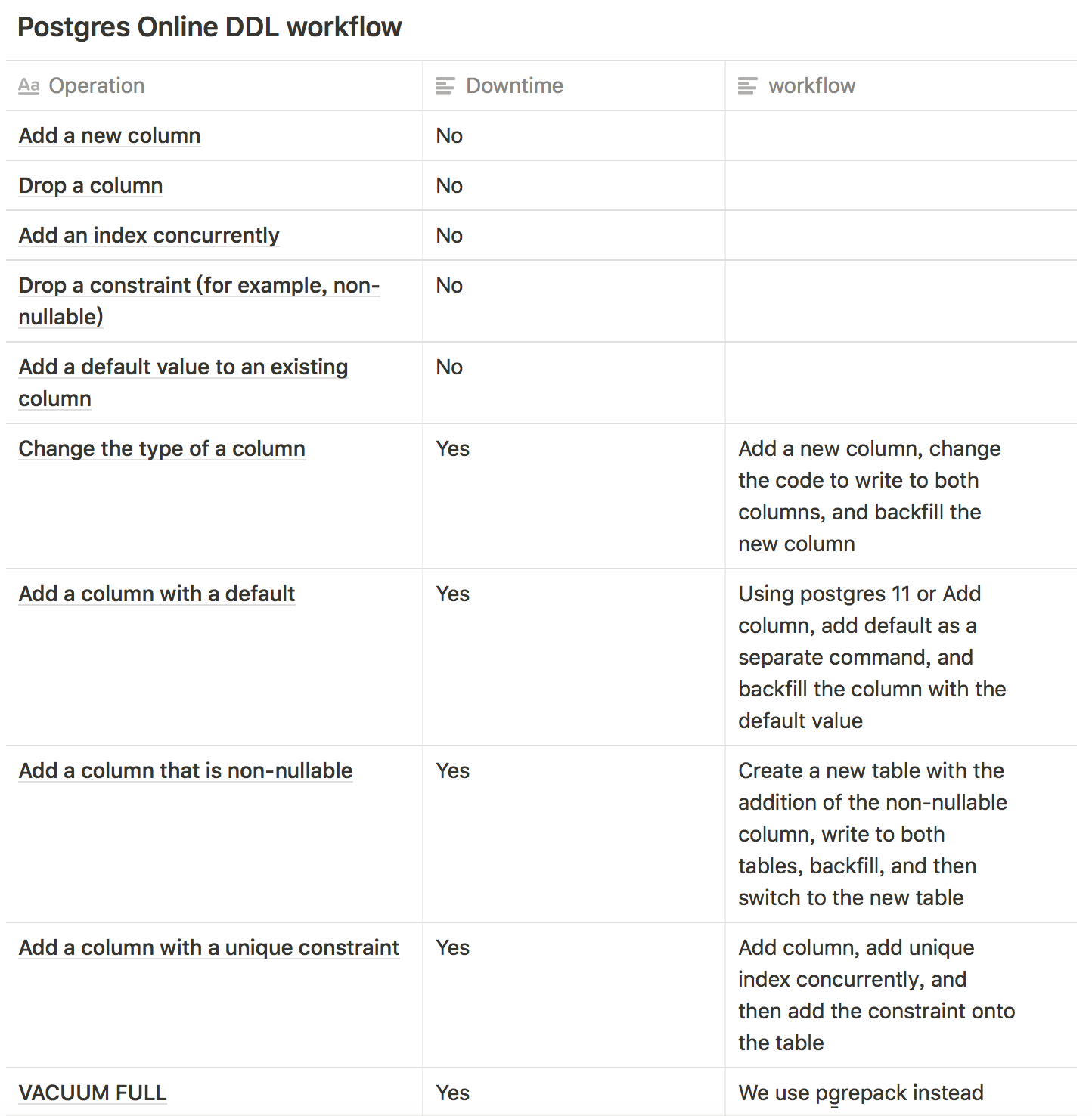
带着上面的需求,下面来一步一步解决。用这个项目把 pg 的表达式索引、局部索引、反向索引都实践了一遍。
演示项目:https://github.com/hooopo/schemaless-pg
结构
表
create_table "sl_tables", comment: "schemaless table", force: :cascade do |t|
t.string "name", comment: "表名"
t.string "desc", comment: "描述"
t.integer "user_id", comment: "创建者"
t.datetime "created_at", null: false
t.datetime "updated_at", null: false
end
列
create_table "sl_columns", comment: "schemaless column", force: :cascade do |t|
t.bigint "sl_table_id"
t.string "name", null: false
t.integer "position", default: 0, comment: "排序位置"
t.string "options", default: [], comment: "预设选项", array: true
t.string "public_type", comment: "外部类型"
t.string "private_type", null: false, comment: "私有类型:int4,int8,varchar, text, int4[], float, money, timestamp, date, int4range, point"
t.datetime "created_at", null: false
t.datetime "updated_at", null: false
t.bigint "ref_sl_table_id", comment: "引用的sl table id,用于schemaless table和schemaless table之间的关联"
t.string "ref_table_name", comment: "引用的外部表名,用于和已存在是实体表之间的关联"
t.index ["sl_table_id", "name"], name: "index_sl_columns_on_sl_table_id_and_name", unique: true
t.index ["sl_table_id", "position"], name: "index_sl_columns_on_sl_table_id_and_position"
end
行
create_table "sl_rows", comment: "schemaless row", force: :cascade do |t|
t.bigint "sl_table_id"
t.jsonb "data", comment: "数据"
t.datetime "created_at", null: false
t.datetime "updated_at", null: false
t.index ["sl_table_id"], name: "index_sl_rows_on_sl_table_id"
end
演示
setup data
t = SlTable.create(name: '订单表')
t.sl_columns.create(name: '客户名', public_type: '文本框', private_type: 'varchar')
t.sl_columns.create(name: '金额', public_type: '浮点数', private_type: 'decimal(10, 2)')
t.sl_columns.create(name: '下单日期', public_type: '日期', private_type: 'date')
t.sl_columns.create(name: '标签', public_type: '标签', private_type: 'varchar[]')
t.sl_rows.create(data: {'1': 'hooopo', '2': 50.88, '3': Date.today, '4': SlRow.pg_array(%w[土豪 电子产品爱好者])})
view postgres
view 专属的 schema 用来隔离和接口统一
schemaless-pg_development=# \dn
List of schemas
Name | Owner
---------+--------
public | hooopo
sl_view | hooopo // view专用schema,这样可以使表名和view名相同,通过设置search path,可以让使用者操作统一的SQL层查询接口
自动生成用户定义的 view
schemaless-pg_development=# set search_path to sl_view;
schemaless-pg_development=# \dv
List of relations
Schema | Name | Type | Owner
---------+--------+------+--------
sl_view | 订单表 | view | hooopo
view 的定义语句
schemaless-pg_development=# \d+ 订单表
View "sl_view.订单表"
Column | Type | Modifiers | Storage | Description
----------+---------------------+-----------+----------+-------------
id | bigint | | plain |
客户名 | character varying | | extended |
金额 | numeric(10,2) | | main |
下单日期 | date | | plain |
印象 | character varying[] | | extended |
View definition:
SELECT sl_rows.id,
(sl_rows.data ->> '1'::text)::character varying AS "客户名",
((sl_rows.data ->> '2'::text))::numeric(10,2) AS "金额",
(sl_rows.data ->> '3'::text)::date AS "下单日期",
(sl_rows.data ->> '4'::text)::character varying[] AS "印象"
FROM public.sl_rows
WHERE sl_rows.sl_table_id = 1;
Ruby 调用
Use MiniSql
schemaless-pg(dev)> ap t.rows_from_view
[
[0] {
"id" => 2,
"客户名" => "hooopo",
"金额" => 50.88,
"下单日期" => Mon, 17 Dec 2018,
"印象" => [
[0] "土豪",
[1] "电子产品爱好者"
]
},
[1] {
"id" => 3,
"客户名" => "hooopo",
"金额" => 50.88,
"下单日期" => Mon, 17 Dec 2018,
"印象" => [
[0] "土豪",
[1] "电子产品爱好者",
[2] "rubyist"
]
},
[2] {
"id" => 4,
"客户名" => "hooopo",
"金额" => 50.88,
"下单日期" => Mon, 17 Dec 2018,
"印象" => [
[0] "土豪",
[1] "电子产品爱好者",
[2] "rubyist",
[3] "100"
]
}
]
Use ActiveRecord
schemaless-pg(dev)> sl_table = SlTable.first
SlTable Load (1.1ms) SELECT "sl_tables".* FROM "sl_tables" ORDER BY "sl_tables"."id" ASC LIMIT $1 [["LIMIT", 1]]
=> #<SlTable id: 1, name: "products", desc: nil, user_id: nil, created_at: "2018-12-20 17:06:00", updated_at: "2018-12-20 17:06:00">
schemaless-pg(dev)> ar_class = sl_table.sl_class
=> #<Class:0x00007f915923d4e8>(id: integer, name: string, desc: text, date: date, price: decimal, category: string)
schemaless-pg(dev)> ar_class.count
(23.3ms) SELECT COUNT(*) FROM "sl_view"."products"
=> 10000
schemaless-pg(dev)> ar_class.first
Load (5.4ms) SELECT "sl_view"."products".* FROM "sl_view"."products" ORDER BY "sl_view"."products"."id" ASC LIMIT $1 [["LIMIT", 1]]
=> #<#<Class:0x00007f915923d4e8> id: 1, name: "320000", desc: "2700", date: "2016-06-14", price: 0.21999e3, category: "420">
schemaless-pg(dev)> ar_class.where("price > 100").first
Load (12.5ms) SELECT "sl_view"."products".* FROM "sl_view"."products" WHERE (price > 100) ORDER BY "sl_view"."products"."id" ASC LIMIT $1 [["LIMIT", 1]]
=> #<#<Class:0x00007f915923d4e8> id: 1, name: "320000", desc: "2700", date: "2016-06-14", price: 0.21999e3, category: "420">
schemaless-pg(dev)> ar_class.where("price > 100").first.name
Load (2.9ms) SELECT "sl_view"."products".* FROM "sl_view"."products" WHERE (price > 100) ORDER BY "sl_view"."products"."id" ASC LIMIT $1 [["LIMIT", 1]]
=> "320000"
表之间的引用
通过 sl_view 引用产生的 view,和两个普通表一样,可以任意 JOIN
schemaless-pg_development=# select o.id from sl_view.orders as o inner join sl_view.products as p on p.id = o.product_id where p.name = '24' limit 1;
id
--------
176068
(1 row)
Time: 0.791 ms
过滤和排序
上面例子已经演示了
搜索
简单,例子待补充
报表
由于暴露的 view,对于大部分流行 BI 工具都可以直接接入,比如 metabase 和 blazer
性能和索引相关
sl_table_id index
默认情况,通过 sl_view 进行查询,会使用到 sl_table_id 这个 index。
schemaless-pg_development=# select count(*) from sl_view.products;
count
--------
100000
(1 row)
Time: 68.302 ms
schemaless-pg_development=# explain analyze select count(*) from sl_view.products;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=5900.08..5900.09 rows=1 width=8) (actual time=149.594..149.595 rows=1 loops=1)
-> Index Only Scan using index_sl_rows_on_sl_table_id on sl_rows (cost=0.42..5640.25 rows=103933 width=0) (actual time=0.465..129.799 rows=100000 loops=1)
Index Cond: (sl_table_id = 7)
Heap Fetches: 100000
Planning time: 0.639 ms
Execution time: 150.509 ms
(6 rows)
Time: 262.017 ms
primary_key index
主键查询可以利用 sl_rows_pkey 这个索引
schemaless-pg_development=# select id from sl_view.products where id = 95085;
id
-------
95085
(1 row)
Time: 17.260 ms
schemaless-pg_development=# explain analyze select id from sl_view.products where id = 95085;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------
Index Scan using sl_rows_pkey on sl_rows (cost=0.42..8.45 rows=1 width=8) (actual time=0.643..0.644 rows=1 loops=1)
Index Cond: (id = 95085)
Filter: (sl_table_id = 7)
Planning time: 0.158 ms
Execution time: 2.491 ms
custom btree index
给 sl_view.orders.age 字段上面加 btree 索引:
t = SlTable.last
c = t.sl_columns.where(name: :age).first
c.create_index!
生成 create index 语句:
(8764.0ms) CREATE INDEX CONCURRENTLY IF NOT EXISTS "8_btree_42_age"
ON sl_rows
USING BTREE (sl_table_id, CAST ((data ->> '42') AS int4))
WHERE sl_table_id = 8
等值过滤:
schemaless-pg_development=# select * from sl_view.orders where age = 40 limit 1;
id | customer_name | total | date | age | tags | product_id
--------+---------------+-------+------------+-----+------------------+------------
914599 | 55555555 | 94.30 | 2018-04-07 | 40 | {电击,电动,电子} | 41757
(1 row)
Time: 13.313 ms
explain analyze select id from sl_view.orders where age = 40 limit 10 ;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=0.42..62.64 rows=10 width=8) (actual time=82.712..82.784 rows=10 loops=1)
-> Index Scan using "8_btree_42_age" on sl_rows (cost=0.42..22752.74 rows=3657 width=8) (actual time=82.710..82.782 rows=10 loops=1)
Index Cond: (((data ->> '42'::text))::integer = 40)
Planning time: 8.856 ms
Execution time: 83.890 ms
(5 rows)
Time: 155.321 ms
比较过滤:
由于测试数据生成的分布太均匀,目前用不到索引... 待填坑
排序:
schemaless-pg_development=# explain analyze select * from sl_view.orders order by age limit 1;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=0.42..0.56 rows=1 width=100) (actual time=0.124..0.125 rows=1 loops=1)
-> Index Scan using "8_btree_42_age" on sl_rows (cost=0.42..103273.76 rows=743546 width=100) (actual time=0.123..0.123 rows=1 loops=1)
Planning time: 0.458 ms
Execution time: 0.163 ms
(4 rows)
Time: 2.640 ms
schemaless-pg_development=# select * from sl_view.orders order by age limit 1;
id | customer_name | total | date | age | tags | product_id
--------+---------------+-------+------------+-----+------------------+------------
926757 | 22222222 | 86.78 | 2018-05-14 | 0 | {产品,电子,电击} | 29457
(1 row)
Time: 3.484 ms
custom gin index
原理同 btree,待填坑
custom fulltext index
原理同 btree,待填坑 pg 有 zhparser 和 pg_jieba 效果还不错,主要是不需要引入 es 了,至少比 mongodb 的效果好太多。
custom multi-column index
待填坑
Sharding
典型的多租系统,citus 完全没问题