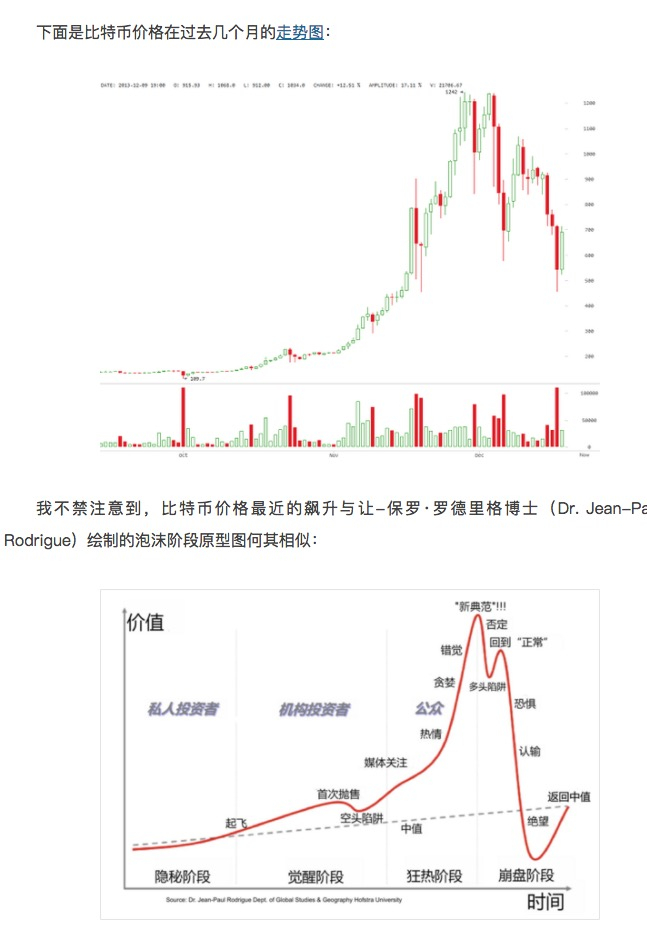
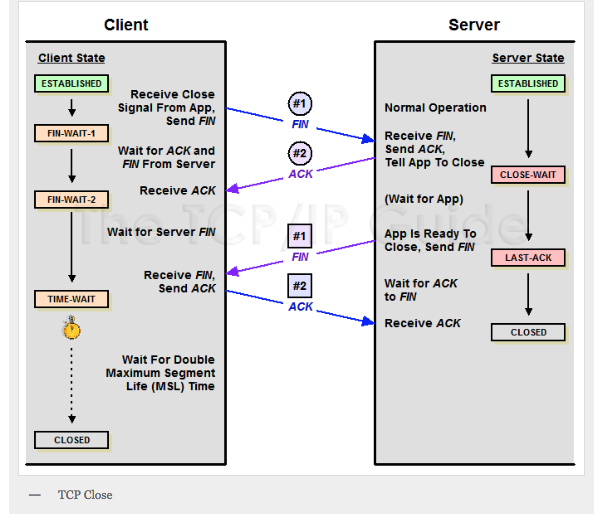
-
新手贴 ,程序员换语言了,努力学习 ruby on rails at 2018年08月03日
业余时间尝试用 rails 重构自己公司的项目
-
ApplicationRecord 对象之间是如何关联的?临时修改保存在哪里?谁能讲解一下 at 2018年07月31日
accepts_nested_attributes_for :payments # 将动态创建 payments_attributes= 方法 # 假设order_params如下 order_params = { payments_attributes: { id: 1, actual_amount: 88 } } # assign_attributes 将触发 payments_attributes= 方法,找到相应payments,并修改。 @order.assign_attributes(order_params)具体的源码看 accepts_nested_attributes_for 是如何动态创建 payments_attributes= 方法
按顺序查看这三个关键方法就明白了
https://github.com/rails/rails/blob/master/activerecord/lib/active_record/nested_attributes.rb#L333
accepts_nested_attributes_for(*attr_names)
https://github.com/rails/rails/blob/master/activerecord/lib/active_record/nested_attributes.rb#L369
generate_association_writer(association_name, type)
https://github.com/rails/rails/blob/master/activerecord/lib/active_record/nested_attributes.rb#L466
assign_nested_attributes_for_collection_association(association_name, attributes_collection)
-
通过 URL 来查数据? at 2018年07月07日
activeadmin 有类似的功能 (基于 ransack 的)。
activeadmin 的 demo: http://demo.activeadmin.info/admin/products?utf8=%E2%9C%93&q%5Btitle_contains%5D=ruby&commit=Filter&order=id_desc
-
求助各位大神。 at 2018年07月06日
Date.strptime Date.parse这两个方法了解一下
-
Rails Server 大量 CLOST_WAIT,进程卡死,服务器无响应 at 2018年06月15日
谢谢回复。学习了。
-
Rails Server 大量 CLOST_WAIT,进程卡死,服务器无响应 at 2018年06月15日
-
Rails Server 大量 CLOST_WAIT,进程卡死,服务器无响应 at 2018年06月15日
用了 nginx。也可以 ip 加端口访问呀
-
Rails Server 大量 CLOST_WAIT,进程卡死,服务器无响应 at 2018年06月15日
有进程或者线程卡住了。导致后面的请求一直在等待。
请问 rails s 是用 puma 吗?
如果你配上 nginx,可以设置 nginx 超时。
-
Awesome Ruby China at 2018年05月24日
很有意义!! 感谢分享!!
-
想问下 ruby 有 word 的模板引擎吗 at 2018年05月17日
$ pandoc --extract-media ./doc ./test.docx -o ./test.html
$ pandoc --extract-media ./doc ./test.pdf -o ./test.html
ruby 中也有相应的 gem: pandoc-ruby
-
Redis 能否存储 non persistent data? at 2018年05月10日
redis.flushdb
-
Rails 的欢迎页面改了 :laughing: at 2018年04月27日
原来狗狗才是重点
-
我觉得可以加一个匿名功能 at 2018年04月25日
匿名干坏事呀

-
关于数据库部份表做中英版本的探讨 at 2018年04月25日
谢谢回复。 我去学习下该 gem
-
在 Rails 中实现拖拽排序功能 at 2018年04月23日
回复是为了上下文的对应关系
这个做法的要点有
- decimal 的长度适当长一点,有时会因长度不够,而造成多个 position 都为 0.00。
- 对移动到第一位,或者最后一位做 if 处理
补上 ruby 代码:
def reposition task = Task.find(params[:id]) next_task = params[:next_id] && Task.find(params[:next_id]) prev_task = params[:prev_id] && Task.find(params[:prev_id]) position = if params[:prev_id].blank? next_task.position / 2 elsif params[:next_id].blank? prev_task.position + 100000 else (prev_task.position + next_task.position) / 2 end task.update(position: position) end -
关于数据库部份表做中英版本的探讨 at 2018年04月23日
我这样理解对吗?
业务需求比较简单的情况下。使用元数据隔离 (维护多一个字段) 比表隔离 (维护两张表) 要更方便些。
具体的解决思路改成:
- 一个数据库,资讯类的表加一个标记字段 (lang)。
- 部署两个 rails 服务 (中英各一个),在 initialization 中使 model 的 default_scope 对应中英文版本
- 通过 Nginx 根据自定义的 http 头识别中英版本的请求,转发到相应的 rails 服务。
-
新版本的感觉没有之前的 UI 好看一些啊 at 2018年04月20日
在 PC 端中,感觉还可以。
-
active admin 编辑的时候刷新缓慢 at 2018年04月02日
切换成 production,更不方便了。需要自己不断的重启。 你有没有用 rubymine 中的 debug 模式。如果有的话,这是慢的重要原因之一。
-
active admin 编辑的时候刷新缓慢 at 2018年04月02日
active admin 是动态生成 controllers,routes 等,dev 模式下修改代码或者间隔一断时间,就会造成再次动态生成。而 production 模式下就有缓存的策略。
-
active admin 编辑的时候刷新缓慢 at 2018年03月30日
使用 production 模式就不会了。
-
开源 Tower 的编辑器 Simditor at 2018年03月27日
-
Puma 的线程数量与数据库连接池的关系 at 2018年03月15日
指你回复中的 查看逻辑 CPU 的个数
总逻辑 CPU 数 = 物理 CPU 个数 × 每颗物理 CPU 的核数 × 超线程数
如果你的服务器中,还有其它的耗费资源多的服务 (例如:mysql)。你可以根据实际情况,减少 woker 数量。
-
Puma 的线程数量与数据库连接池的关系 at 2018年03月15日
设置的连接池数是指一个进程中最大拥有的数量。所以你的 hreads 设置成 2 16,连接池最大设置成 16 就行了。
woker 是根据你的 cpu 核数设置的。threads 数可以根据你的系统情况设置 (如果平均请求速度比较快,threads 可以设高一点,否则反之)。
设置 worker 为 2 和 threads 为 2,你这是问进程和线程的区别吗?
-
使用 Newrelic 与 ab 工具 尝试了解项目的性能 at 2018年03月09日
如果你是 mac 系统,ab 是自带的。这个东西很简单,你 google 就好了。
newrelic 我是看这位前辈的帖子学习的。性能监控的好工具 - NewRelic 简介
-
Puma 的线程数量与数据库连接池的关系 at 2018年03月09日
嗯,明白你的意思了。之前是我理解错了。

-
Puma 的线程数量与数据库连接池的关系 at 2018年03月08日
配置的连接池是指定一个进程里有多少连接池。rails c 那是额外打开一个进程。
-
Ruby on Rails 开发的 API,能支撑多大的日请求量? at 2018年03月08日
你配置 4 个 worker 加每个 worker 一个线程,给你带来 cpu 使用率下降,request 处理变快了的原因是在:
你的 puma 现在只能同时处理 4 个请求。其它的请求在排队进入 puma。所以实际上并发高的时候只是在 puma 处理请求这块变快了 (同时处理 4 个,与同时处理 4*8 个,显然前者的速度更快),而有更多的请求因为在排队,导致用户从发送请求到响应花了更多的时间。
-
Puma 的线程数量与数据库连接池的关系 at 2018年03月08日
我现在可以修改标题

-
服务器负载过高怎样优化? at 2018年03月07日
希望该帖子对你有帮助。puma 的线程数量 与 数据库连接池的关系
-
为什么说绝大多数人都没搞懂区块链接,区块链的实质创新是什么 at 2018年02月11日
数量有限的电子货币,我是认可有一定价值的,和黄金的属性差不多。
但现在各种各样的币,价格贵的要死。已经太疯狂了。
我选择看戏。