-
怎么让 AI 写出更有 Rails 味的代码? at July 06, 2026
其实我现在研究 rails 只是类似弹吉他一样的兴趣爱好了。说实话,如果只是为了干活儿上生产,我何必用 rails 呢……反正都是 AI 一把梭。现在 AI 写 go、node、py 这些写的最好了。
-
OpenClacky 1.0 正式发布 —— Ruby 圈第一个通用 Agent 来了 at May 27, 2026
py 的 agent 其实不太多吧,看目前的几个主流 pi、openclaw、claude code、opencode 全是 ts 写的,就一个 Hermes 是 py 的、codex 是 rs
-
AI 开发 Rails,如果遇到 bug 看不懂咋办? at March 15, 2026
你看看 openclaw 现在的代码量,我觉得人类已经很难维护了……
-
2026 年国内 AI Coding Plan 怎么选?5 大平台横评帮你省钱 at March 10, 2026
还真可以,好吧,眼拙了,藏稍微有点深
 别的 coding plan 一般写的很显眼
别的 coding plan 一般写的很显眼 -
2026 年国内 AI Coding Plan 怎么选?5 大平台横评帮你省钱 at March 10, 2026
打错了,其实我的意思是只能用 kimi code 这个官方 agent,不能接 claude code 或者 opencode
-
2026 年国内 AI Coding Plan 怎么选?5 大平台横评帮你省钱 at March 08, 2026
kimi 这个主要问题是只能用 kimi coding,比较局限
-
2026 年国内 AI Coding Plan 怎么选?5 大平台横评帮你省钱 at March 05, 2026
- 智谱根本买不到……
- 字节没有 glm-5 只有 4.7
- 阿里的除了 qwen,glm 和 kimi 都很慢,估计限速了,而且经我体验,有突然假死的现象出现,比较频繁
- minimax 写代码实在是搞不定,干点别的低智能的任务还是挺划算的
试了一圈最后还是滚回去用官方 codex 了,最近两个月付费账户额度翻倍,免费账户也能有一定额度用 5.3 codex 模型
-
稍微复杂点的后端项目除了 Rails 还能选什么? at January 04, 2026
试试 drizzle,typescript 加持的 sql builder 挺爽的,直接不用 orm 了
-
请教。怎么推广一个 gem 呢?我的一个 gem s_matix 是有什么硬伤让其不容易被收录和推荐呢? at May 09, 2025
我感觉可能只是单纯需求比较少,大部分 ruby 的场景可能用不太到
-
大家一般线上环境的 migration 在什么时候执行? at April 18, 2025
不行吧,看源码抢锁失败会直接报错,如果把默认的 -e 删了,那不是其他机器 migrate 还在进行,这台机器的新代码就跑起来了。
-
大家一般线上环境的 migration 在什么时候执行? at April 17, 2025
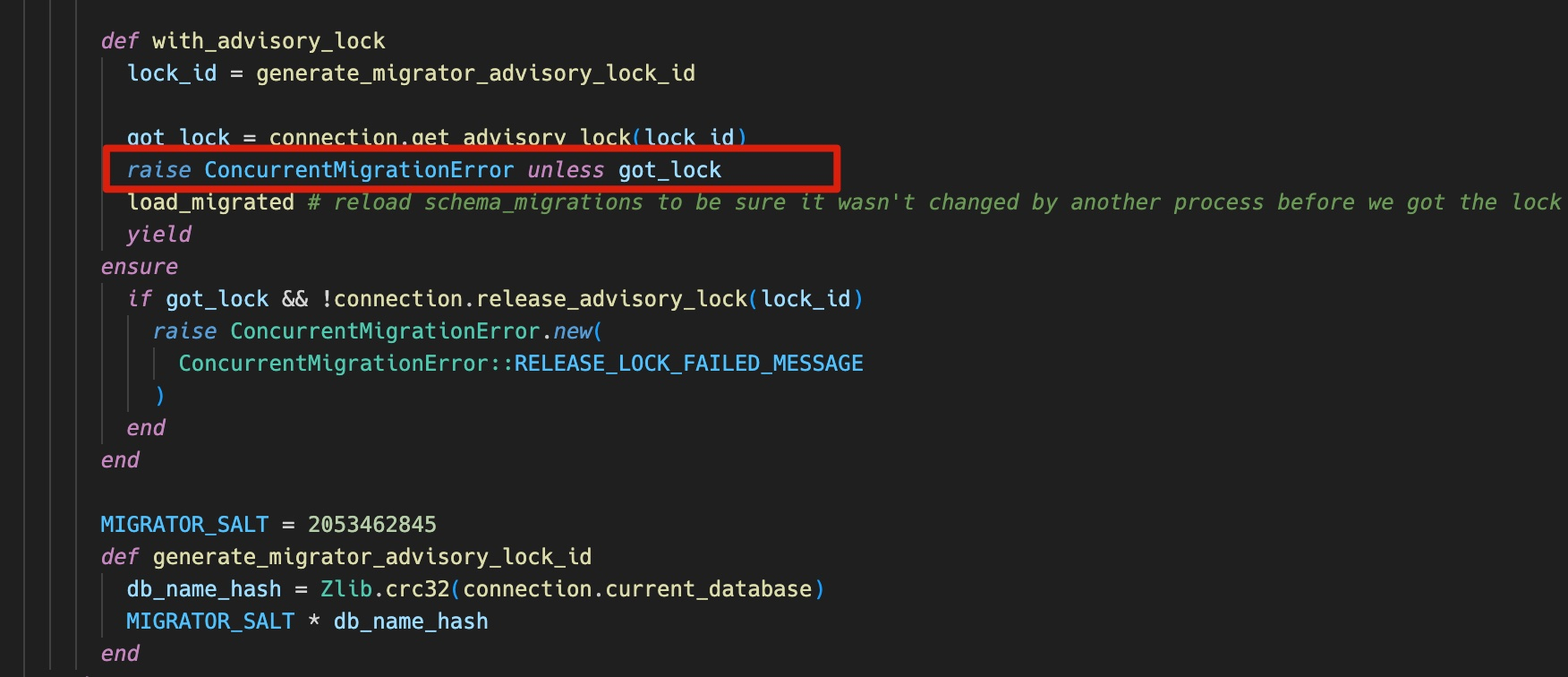
rails/activerecord/lib/active_record/migration.rb看源码这里如果强锁失败会报错的,不会影响容器启动吗?
-
大家一般线上环境的 migration 在什么时候执行? at April 17, 2025
改了一下描述,不是说这个时间,而是说部署的时候,rails 默认是启动容器的时候运行 migrate,分布式部署多台机器就会运行多次,如果凑巧同时运行了是不是存在风险的
-
大家一般线上环境的 migration 在什么时候执行? at April 17, 2025
但是分布式部署上多台机器会执行多次吧,可能会出问题
-
homeland 源码中 list_actions.rb 中的 current_user 在哪里定义的? at January 08, 2025
应该是 rubymine
-
现在用 importmap + stimulus 这套技术栈有什么好用的组件库? at January 06, 2025
请教一下是用的 SPA 吗?因为目前 rails 这套 esbuild/webpack/rollup 想做到给不同的页面加载不同的 JS 文件(懒加载)好麻烦,得一个个文件路径手写到 js 编译工具的配置里面。
还是说所有 js 都放一起,不做懒加载。
-
现在用 importmap + stimulus 这套技术栈有什么好用的组件库? at January 04, 2025
现在难受的点是,用了 stimulus-components,stimulus 配合 importmap 的自动懒加载就没了
-
PostgreSQL 数据库删除外键约束引发的死锁问题 at December 15, 2024
仔细想了一下,确实除了自己的项目,在工作中从来没用过外键约束,数据库层面最多用一个 uniq 索引,甚至 null false 都很少用,很久之前还觉得这样不优雅,现在看确实能避免很多不好发现的问题
当然另外一个原因是微服务都拆成零碎了,业务最核心的四五张表分别在三个部门的三个数据库里,根本没办法 join -
rails 的很多用法感觉是部落知识(Tribal knowledge),有什么权威的查询途径呢? at November 19, 2024
这个有点太简略了
一个方法还好说,有时候根本不知道用什么,只知道需要某种行为,比如我需要在 controller 里面调用 dom_id,我是不知道 controller 里面就有 helpers 这个方法,跟别说去查询了 -
Rails 8.0: No PaaS Required at November 11, 2024
某互联网大厂,当然技术栈并不是 ruby,只是讨论一下用 db 做缓存这个做法
-
Rails 8.0: No PaaS Required at November 11, 2024
我目前的业务不能让任何 C 端流量打 DB,峰值几十万的 QPS 打到 DB 就完蛋了,感觉 QPS 不高的项目可以用这个
-
Rails 8.0: No PaaS Required at November 09, 2024
哦哦,他的意思是是 db 用的是磁盘,redis 用的是 ram,我还以为他会在本机再做一层基于文件的缓存,和 db 组成多级缓存
-
Rails 8.0: No PaaS Required at November 09, 2024
SolidCache 是多级缓存吗?试了一下会存到 DB 里面去,但我看文章里说的又是磁盘缓存
-
rails7 之后怎么加载页面特定的 css? at October 16, 2024
试了一下 propshaft,js 代码的相对路径引用挂掉了,得换成 import map 的
pin_all_from 'app/javascript/src', under: 'src', to: 'src',不过改造之后所有的代码提示都没了,得整个 jsconfig 让 ide 识别 import map 的这个 alias{ "compilerOptions": { "baseUrl": "./app/javascript", "paths": { "src/*": ["src/*"] } } } -
国内个人备案到底可以做什么功能? at October 15, 2024
听说违规被查到要罚好几万
-
当你完成了一个很复杂的、包含大几千行代码的功能时,有人 CR 评论跟你纠结代码风格问题,该怎么回复他? at August 18, 2024
其实我是想喷他,并不想去改……改了助长这种人的风气,lint 检查都通过了,这种人纯属找存在感。
-
Go 语言在国内发展的不行了吗?怎么没有看到像样的中文官方社区? at August 13, 2024
Go 一般没什么骚操作,就那几个普通用法,强调简洁(简陋),所以没什么太多关于语言本身的讨论。反而你看现在很多新的开源软件,一翻 Github 都是 Go 写的。
-
我是新人,请教大佬一个问题~请教工作中的问题~ at July 06, 2024
大概率是 mac,互联网基本都是发 mac
-
Ruby 有没有类似 Java Jackson 那种将 class 和 json 互转的库? at July 05, 2024
很多库都只能 class 转 json,但 json 转 class 的能力都缺失
-
国内的 Docker 镜像好像都没了,听说后续 npm 之类的镜像也要干掉,gem 会不会受到影响 at June 09, 2024
主要太大了,梯子有流量限制的,到时候下点依赖就炸裂了,特别是 node_modules
-
行锁在日常开发中用的真的不多吗?Prisma 居然没有提供行锁的 API at June 02, 2024
还行吧,基础功能都有,不要依赖一些骚操作一般没啥问题,作者好几年前确实说自己没精力维护了