原文:
http://www.jstorimer.com/blogs/workingwithcode/8085491-nobody-understands-the-gil
Part I
我的大半生都是在 Ruby 社区中度过的,然而 MRI 中臭名昭著的 GIL 对我而言却一直是个叵测的家伙。这是一个关于线程安全的故事,最终我们会真相大白,
最初听人提及 GIL 时,我不知道它是如何工作的,它做了什么事,甚至也不知道它为什么会存在。我只知道这是个蠢主意,因为它限制了并行,换句话说就是"曾经辉煌",因为它让我的代码线程安全。后来,我总算学会了如何去爱多线程,也意识到了现实远比我设想的复杂。
我要知其然,更要知其所以然,GIL 到底是怎么工作的?但是,GIL 没有规程 (specification) 可循,亦没有文档可看。本质上说它就是一个未知行为;一个 MRI 的实现细节。Ruby 核心组没有对它将如何工作予以承诺或担保。
也许我有点儿超前了。
如果你对 GIL 一无所知,花 30 秒钟读读下面这个简介吧:
MRI 里有个东西叫全局解释器锁 (global interpreter lock)。这个锁环绕着 Ruby 代码的执行。即是说在一个多线程的上下文中,在任何时候只有一个线程可以执行 Ruby 代码。
因此,假如一台 8 核机器上跑着 8 个线程,在特定的时间点上也只有一个线程和一个核心在忙碌。GIL 一直保护着 Ruby 内核,以免竞争条件造成数据混乱。把警告和优化放一边,这就是它的主旨了。
问题
回到 2008,Ilya Grigorik 的 《Ruby 里的并行神话》给了我对 GIL 的高层次理解。即使我学确实学到了更多的 Ruby 多线程技术,但是这个高层次认识只是对我的单方灌输。真见鬼,我最近还写了一本关于Ruby 里多线的书呢,但是对于 GIL 我就理解了这么点儿?
问题是用些"微言大义"的认识,我没法回答有深度的技术问题。特别是,我想知道 GIL 是否提供了关于线程安全的任何保障。让我来示范一下。
数组附加是非线程安全的
几乎没什么事在 Ruby 里是隐式线程安全的。以附加数组为例:
array = []
5.times.map do
Thread.new do
1000.times do
array << nil
end
end
end.each(&:join)
puts array.size
这里有 5 个线程共享一个数组对象。每个线程将 nil 放入数组 1000 次。因此,数组里应该有 5000 个元素,对吧?
$ ruby pushing_nil.rb
5000
$ jruby pushing_nil.rb
4446
$ rbx pushing_nil.rb
3088
:(
即使这个微不足道的例子,也足以揭示 Ruby 里的一个操作并非隐式线程安全的。或许是?实际上发生什么了呢?
请注意 MRI 的结果是正确的,5000。但是 JRuby 和 Rubinius 都错了。如果你再跑一遍,你很可能会看到 MRI 依然正确,但是 JRuby 和 Rubinius 给出了不同的错误结果。
这些不同的结果是 GIL 造成的。因为 MRI 有 GIL,即使同时有 5 个线程在跑,在一个时间点上也只有一个线程是活动的。JRuby 和 Rubinius 没有 GIL,所以当你有 5 个线程在跑,你就真的有 5 个线程通过获取核心在并行地跑。
在并行的 Ruby 实现中,这 5 个线程逐句通过代码,而这是非线程安全的。它们最终互相干扰,最终腐化底层数据。
多线程如何腐化数据
这怎么可能?我还以为 Ruby 会罩着我们呢,对吧?相对于通过高层次的解释来阐述技术细节,我更倾向于向你展示这在技术上的可能性。
无论你是用 MRI,JRuby 或是 Rubinius,Ruby 语言是用其他语言实现的。MRI 是用 C 实现的,JRuby 用 Java,Rubinius 是 Ruby 和 C++ 的混合体。于是当你有这样一个 Ruby 操作时:
array <<< nil
实际上在底层实现上会扩展为一大堆代码。例如,下面是 Array#<<在 MRI 中的实现:
VALUE
rb_ary_push(VALUE ary, VALUE iterm)
{
long idx = RARRAY_LEN(ary);
ary_ensure_room_for_push(ary, 1);
RARRAY_ASET(ary, idx, item);
ARY_SET_LEN(ary, idx + 1);
return ary;
}
注意至少 4 个不同的底层操作。
- 获取数组的当前长度
- 检查数组里是否有空间容纳其他元素。
- 将元素附件到数组
- 将数组的长度属性置为原值 +1。
每个操作还回调用别的函数或者宏。我提到这些是为了向你们展示多线程是如何能够破坏数据的。在但线程环境中,你可以观察并简单地跟踪这个短代码的轨迹。
话句话说,我们已经习惯了以线性的方式逐句执行代码并推断"真实世界"的状态。我们通常就是这么写代码的。
当多线程乱入,这就不可行了。这很像物理变化的规则。当有两个线程,每个线程维护这个自己的代码轨迹。由于线程共享同一个内存空间,而这些线程可以同时改变"真实世界"中的状态。
一个线程可能会打扰另一个线程,从此改变事物的状态,之后原先的线程完全不知状态已经被改变了。
这里是我的小系统的基本状态:

有两个活跃线程,同时进入这个函数 (C 语言中的)。将 1-4 步看做 MRI 中 Array#<<的伪代码实现,之前你见过的。一旦两个线程进入这个函数,就可能出现一系列事件,假设从线程 A 开始:

这看着更复杂了,但是只要跟着箭头的方向,你就可以穿过这个流程。我还加了在每个步骤上一些标签从每个线程的角度来显示各种状态。
这只是其中一种可能性。
于是线程 A 沿着函数的常规路径执行,但当执行到步骤 3 时,发生了上下文切换!线程 A 被暂停在当前位置。之后线程 B 接管了进程并运行整个函数,附加它自己的元素并增加length属性。
一旦线程 B 完事了,线程 A 就恢复执行。A 会在其中断的位置走起。记住,线程 A 是在增加length属性前被暂停的,自然会从往下增加length属性。只不过,A 并不知道线程 B 已经改变了事物的状态。
于是线程 B 设置length为 1,之后线程 A 又把length设为 1,尽管它们格子的元素都已经被附加到了 Array 上。数据已经被玩坏了。看到图中的小闪电了吗,就这这个意思。
但是我想 Ruby 会罩着我吧?
如图中例子所示,JRuby 和 Rubinius 中的这一系列的事件会带来错误的结果。
除此之外,在 JRuby 和 Rubinius 里,事情要更为复杂,因为线程实际可以平行跑。在该图中,一个线程被暂停,另一个在运行,而在真正并行的环境里,多个线程可以同时运行。
要是你真的运行可前面的那个例子,可能会看到它总是能得到不同的错误结果。这里的上下文切换是不确定的,无法预知。它可能发生在函数运行前期,后期,或者就根本没发生。下一小节关这个我们会谈更多。
所以,为什么 Ruby 不保护我们远离这些? 出于同样的原因,其他一些编程语言内核也不提供线程安全保护:它成本太高。对所有的 Ruby 实现提供线程安全的数据结构不是不可能,但这需要额外的开销,拖了单线程代码的后腿。
权衡之下,你,开发者就有责任在需要的时候提供线程安全的保证。
对我而言,这提出了两个悬而未决的问题,并且我们并未潜入 GIL 的技术细节中。
如果下上文切换是可能的,为什么 MRI 还能给出正确答案呢?
上下文切换到底是什么鬼?
问题 1 是我写这篇文正的动机。对 GIL 高层次的认识无法回答这个问题。高层次的认识只说清了只有一个时间点上只有一个线程可以被执行。但是 Ruby 之下,上下文切换是不是还能在函数的中间发生呢?
但是首先.....
都是调度程序的错!
上下文切换源于操作系统的线程调度程序。在所有我展示过的 Ruby 语言实现中,一个 Ruby 线程依托于一个原生的操作系统线程。操作系统必须保证没有一个线程可以独霸所有可用资源,如 CPU 时间,于是它实现了调度算法,使得雨露均沾。
这表现为一系列的暂停会恢复。每个线程都有机会消耗资源,之后它暂停在其轨道上,以便其他线程可以有机可乘。随着时间推移,这个线程经会被不断被恢复。
这一做法提高了操作系统的效率,但也引入和一定程度的不确定性和程序正确性的难度。例如,Array#<<操作现在需要考虑到它可以随时暂停,另一个线程可以并行地执行相同的操作,改变脚下"世界"的状态。
则何如?让关键操作具有原子性
如果想确保这样的线程间中断不发生,就应该使操作具有原子性。通过原子性操作,可以保证线程在完成动作前不会被打断,这就防止了我们例子中的,在步骤 3 被打断,并最终在步骤 4 时恢复导致的数据误。
是操作具有原子性的最简方案是使用锁。下面的代码会确保结果的正确,不论是在 MRI,JRuby 还是 Rubinius 里。
array = []
mutex = Mutex.new
5.times.map do
Thread.new do
mutex.synchronize do
1000.times do
array << nil
end
end
end
end.each(&:join)
puts array.size
它确保正确是因为使用了一个共享的互斥或者说锁。一旦一个线程进入mutex.synchronize内的代码块时,所有其他线程必须在进入同一代码前等待,直到这个线程执行完毕。如果你回想前面,我说过这个操作下是多行 C 代码,并且线程调度上下文切换可以发生在任意两行代码间。
通过原子性操作,你可以保证如果一个上下文切换在这个代码块里发生了,其他线程将无法执行相同的代码。线程调度器会观察这一点,并再切换另一个线程。这同样也保证了没有线程可以一同进入代码块并各自改变"世界"的状态。这个例子现在就是线程安全的。
GIL 也是个锁
我刚才已经展示乐怎样可以使用锁得到原子性并提供好线程安全保证。GIL 也是一个锁,所以它也能保证你代码的线程安全吗?
GIL 会使 array << nil 变成原子性操作吗?
这篇文章已经够长的了。就让我们在下一部门深入 MRI 的 GIL 来回答这些问题吧
Part II 实现
上文书说到,我想带你深潜到 MRI 里去看看 GIL 是怎么实现的。但是首先,我想确认一下我提出了正确的问题。Part I 中的疑问,但是今天我们将在 MRI 内找寻答案。我们将会追寻这条见首不见尾的神龙,他们管它叫 GIL。
在本文的初稿中,我真的很强调 GIL 底层的 C 代码,尽可能展示它们。但过了一段时间,一些重要的信息被细节淹没了。我重头来过了,你现在看到的这一版去掉了一些 C 代码,多了一些解释和图示,但是对于代码水鬼们,我至少会提到 C 的函数名,所以你可以自己去一探究竟。
书接上文...
Part I 留下了两个问题:
- GIL 会使 array << nil 变成原子性操作吗?
- GIL 能保证你的 Ruby 代码线程安全吗?
第一个问题的答案在实现中找,那就让我们开始吧。
下面的片段是我们上次见过了:
array = []
mutex = Mutex.new
5.times.map do
Thread.new do
mutex.synchronize do
1000.times do
array << nil
end
end
end
end.each(&:join)
puts array.size
如果你假设 Array 是线程安全的,预计的结果是数组会有 5000 个元素。因为数组不是线程安全的,在 JRUby 和 Rubinius 的实现中产生了不期的结果;比 5000 少。这是多线程间交互切换造成的底层数据错误。
MRI 产生了预期结果,这是侥幸还是必然呢? 让我们用这个 Ruby 代码片段来进行技术深潜。
Thread.new do
array << nil
end
自顶而下
为了学习这个片段中到底发生了什么,我们需要 MRI 内部是如何衍生线程的。我们主要看thread*.c文件中的那些函数。这些文件中有不少迂回之处,来同时支持 Windows 和 Posix 的线程 APIs,但是这个些函数都是从这些源码文件中看来的。
第一个Thread.now底层操作是衍生一个新的原生线程来支持 Ruby 线程。成为新线程主体的 C 函数称为thread_start_func_2。让我们从高层次一看这个函数。
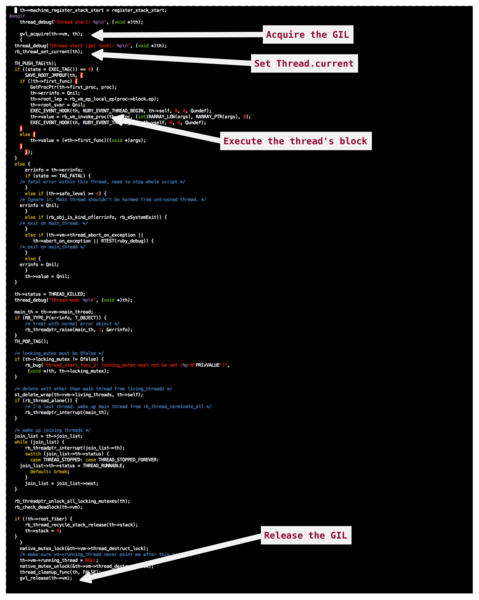
这里有很多样板代码,不值得一看。我标出了值得我们关注的部分。在接近顶部的地方,新线程获取 GIL。注意,这个线程会保持空闲,直到它确实获得了 GIL。在函数中部,它调用你穿给Thread.new的那个代码块。包装事物后,它释放乐 GIL 并退出原生线程。
在我们的片段中,这个新线程衍生于主线程。有鉴于此,我们可以假设主线程当前正持有 GIL。新线程将必须等待,直到主线程释放 GIL,它才能继续。
让我们看一下当新线程尝试获取 GIL 时发生了什么吧。
static void
gvl_acquire_common(rb_vm_t *vm)
{
if (vm->gvl.acquired) {
vm->gvl.waiting++;
if (vm->gvl.waiting == 1) {
rb_thread_wakeup_timer_thread_low();
}
while (vm->gvl.acquired) {
native_cond_wait(&vm->gvl.cond, &vm->gvl.lock);
}
这段代码来自gvl_acquire_common函数。此函数在我们的新线程尝试获取 GIL 时被调用。
首先,它会检查 GIL 当前是否被占有了,之后它增加 GIL 的waiting属性。同我们的片段,这个值应该现在为 1。紧接着的一行检查看wating是否是 1。它正是 1,于是下一行触发唤醒了个计时器线程。
计时器线程是 MRI 中线程系统能一路高歌的秘密武器,并避免任意线程独霸 GIL。但在我们跳得太远之前,先让我们阐述一个 GIL 相关事物的状态,然后再来介绍计时器线程。
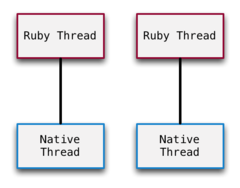
我前面说了几次,MRI 线程依靠的是原生的操作系统线程。这是真的,但是如图中所示,每个 MRI 线程并行运行在各自的原生线程中。GIL 阻止这样。我们需要画出 GIL 来让其更为接近事实。
当一个 Ruby 线程希望在它自己的原生线程中执行代码时,必须先获得 GIL。GIL 在 Ruby 线程和它们各自的原生进程之间周旋,极力消减并发! 上张图里,Ruby 线程在其原生线程里可以并行执行。而第二张更接近 MRI 事实真相的图里,在特定时间点上只有一个线程可以获取 GIL,于是代码的执行是完全不能并行的。
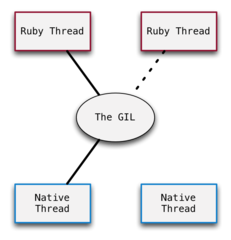
对 MRI 核心组而言,GIL 保卫着系统的内部状态。使用 GIL,他们不需要在数据结构周围使用任何锁或者同步机制。如果两个线程不能够同时改变内部状态,也就不会有竞争条件发生了。
对你,开发者而言,这会大大限制你从 MRI Ruby 代码中获得的并发能力。

计时器线程
我前面提到计时器线程是用来避免一个线程独霸 GIL 的。计时器线程只是一个存在于 MRI 内部的原生线程;它没有相应的 Ruby 线程。计时器线程在 MRI 启动时以rb_thread_create_timer_thread函数启动。
当 MRI 启动并只有主线程运行时,计时器线程沉睡。但请记住,一旦有一个线程在等待 GIL,它即会唤醒计时器线程。
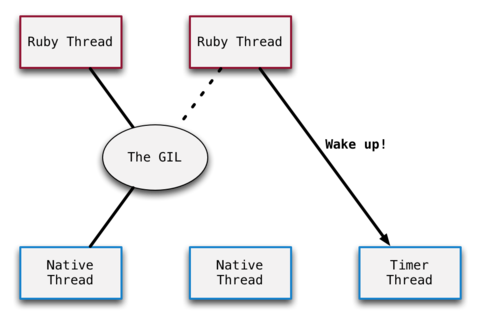
这张图更近乎于 MRI 中 GIL 的实现。回想之前的片段,我刚刚衍生出最右边的线程。因为它是唯一在等待 GIL 的,就是它唤醒计时器线程的。
计时器线程是用来避免一个线程独霸 GIL 的。每 100 毫秒,计时器线程在当前持有 GIL 的线程上设置一个中断标志,使用 RUBY_VM_SET_TIMER_INTERRUPT 宏。这里的细节需要注意,因为这会给array << nil 是否是原子性操作这个问题提供线索。
如果你熟悉时间片的概念,与此很相似。
每 100 毫秒计时器线程会在当前持有 GIL 的线程上设置中断标记。设置中断标记并不实际中断线程的执行。如果是这样的话,我们可以肯定array << nil不是一个原子性操作。
控制中断标志
深入名为vm_eval.c的文件,包含了控制 Ruby 方法调用的代码。它有负责创建方法调用的上下文,并调用正确的方法。在方法结束时调用vm_call0_body,正当它返回当前方法的返回值之前,这些中断会被检查。
如果这个线程已经被设置了中断标志,则在返回其值前当场停止执行。在执行更多 Ruby 代码之前,当前线程会释放 GIL 并调用sched_yield。sched_yield是一个系统方法提示线程调度器安排另一个线程。一旦完成这个工作,该中断线程尝试重新获取 GIL,现在不得不等待另一个线程释放 GIL 了。
嘿,这就是我们问题的答案。array << nil是原子性的。多亏了 GIL,所有用 C 实现的 Ruby 方法都是原子性的。
所以这个例子:
array = []
5.times.map do
Thread.new do
1000.times do
array << nil
end
end
end.each(&:join)
puts array.size
运行在 MRI 上每次都保证产生预期的结果。
但请记住,这个保证并不针对 Ruby 写成的那些代码。如果你把这段代码放到没有 GIL 的其他实现里,它将会产生叵测的结果。很有必要了解一个 GIL 保证,但依赖它来写代码就不是个好主意了。在此过程中,你基本就把自己和 MRI 捆绑在一块儿了。
相似的,GIL 不是公开的 API。没有文档和规程说明。虽说 Ruby 代码是隐式依赖 GIL 的,但之前的 MRI 团队曾谈及想摆脱 GIL 或改变其语义。出于这些原因,你当然不希望,写出来的代码只能依赖于现下 GIL 的行为吧。
非原生方法
目前为止,我说到array << nil是原子性的。这很简单,因为Array#<<方法只带一个参数。这个表达式里只有一个方法调用,并且它是用 C 实现的。如果它在过程中被中断了,只会继续直到完成,之后释放 GIL。
那类似这样的呢?
array << User.find(1)
在Array#<<方法执行前,它先要对右侧的表达式进行求值,然后才能把表达式的值作为参数。所以User.find(1)必须先被调用。如你所知,User.find(1)会调用一大堆其他 Ruby 代码。
所以,在上面的例子中 Array#<< 依然是原子性的吗?是的,但是一旦右手边被求值。换句话说,没有原子性保证User.find(1)方法将被调用。之后返回值会传给 有原子性保证的Array#<<。
更新: @headius 发了一个极好的评论,扩展了 GIL 提供的保证。如果你读到这个,考虑必读一下。
这一切意味着什么?
GIL 使得方法调用原子性。这个对你意味着什么呢?
在 Part I 中,我举例展示了在 C 函数中发生上下文切换时会发生什么。使用 GIL,这种情况不会再发生了。相反,如果上下文切换发生了,其他线程会保持空闲以待 GIL,给当前线程机会继续不中断。此行为只适用于 MRI 用 C 实现的 Ruby 方法。
这种行为消除了竞争条件的源头,不然 MRI 的内部竞争会防不胜防。从这个角度,GIL 是一个严格的 MRI 内部实现细节。它保持 MRI 的安全。
但是还有一个挥之不去的问题尚无答案。GIL 能提供给你的 Ruby 代码线程安全保证吗?
这是一个 MRI 使用中的重要问题,要是你熟悉其他环境的多线程编程,你可能已经知道了,答案是一个大写的不行。但是这篇文章已经足够长了,我将会在Part III更彻底地解决这个问题。
Part III: GIL 能让你的 Ruby 代码线程安全吗?
围绕着 MRI 的 GIL,ruby 社区中有一些错误观念。要是你今天只想从这篇文章获取一个观点,那就是:GIL 不会使你的 Ruby 代码线程安全。
但请别这么相信我。
这个系列一开始只是为了从技术层面上了解 GIL。Part I 解释了竞争条件是如何在实现 MRI 的 C 源码中发生的。还有,GIL 貌似排除了风险,至少我们看到 Array#<<方法是这样。
Part II 证实了 GIL 的作为,实际上,它使得 MRI 的原生 C 方法实现原子化了。换而言之,这些原生方法是对竞争条件免疫的。这个保证只针对 MRI 的 C 原生方法,你自己写的那些 Ruby 可不行。 于是我得到一个遗留问题:
GIL 能否保证我们的 Ruby 代码是线程安全的?
我已经回答过这个问题了。现在我想确保谣言止于智者。
归来的竞争条件
竞争条件发生在一些数据块在多个线程之间共享,并且这些线程企图同时在数据上进行操作的时候。当发生时没有一种同步机制,比如锁,你的程序会开始做一些意料之外的事,并且数据也会遗失。
让我们回过头来回顾一下这种竞争状态是如何发生的。我们将使用如下 Ruby 代码作为本节的示例:
class Sheep
def initialize
@shorn = false
end
def shorn?
@shorn
end
def shear!
puts "shearing..."
@shorn = true
end
end
这个类定义应该很常见。一头羊在初始化的时候是没被薅过的。shear!方法执行薅羊毛并标记这头羊为薅过。

sheep = Sheep.new
5.times.map do
Thread.new do
unless sheep.shorn?
sheep.shear!
end
end
end.each(&:join)
这一小段代码创建了头羊并且衍生出 5 个线程。每个线程竞相检查羊是不是被薅过?要是没有,就调用 shear! 方法。
以下结果是我在 MRI2.0 里多次执行得到的。
$ ruby check_then_set.rb
shearing...
$ ruby check_then_set.rb
shearing...
shearing...
$ ruby check_then_set.rb
shearing...
shearing...
有的时候一只羊被薅了两回。
如果你有 GIL 是你的代码在多线程面前一马平川,赶快忘了吧。 GIL 不能做出这样的担保。需要注意第一次运行时产生了预期结果。随后的几次运行,意外的结果才出现。如果继续试几次,会看到不同的变化。
这些意外的结果归咎于 Ruby 代码中的竞争条件。这实际上是一个足够典型的竞争条件,这一模式被称为:检查 - 后-设置 竞争条件。在检查 - 后-设置竞争条件中,两个以上线程检查某值,之后设置基于这个值的一些状态。在没有提供原子性的情况下,很有可能两个线程竞争通过"检查"阶段,之后一同执行"设置"阶段。
认出竞争条件
在我们解决这个问题之前,首先我想让大家理解怎么认出竞争条件。向我介绍交错这个术语的@brixen,我欠你个人情。这真的很有帮助。
记得吗,上下文切换可以发生在代码的任何一行上。当一个线程切换到另一个线程时,想象你的程序被切分了一组互不关联的块。有序的一组块就是一组交错。
一种极端情况是,每行代码后面都可能都发生了上下文切换!这组交错会将每行代码穿插起来。另一种极端是,线程体中可能并没有发生上下文切换,这组交错会为每个线程保持各自原来代码的顺序。
一些交错是无害的。不是没行代码都会进入竞争条件。但是把你的程序想象成一组可能的交错可以帮助你辨识到什么时候竞争竞争条件确实发生了。我会用一系列图示来展现:这段代码可能被两个 Ruby 线程交错的情况。

为了使图示简单明了,我将shear!方法调用替换成了其方法体。
考虑这个图示:红色标注的代码是线程 A 中的一组交错,蓝色标出的是线程 B 的一组交错。
现在让我们模拟上下文切换来看一下代码是怎么被穿插起来的。最简单的情况是在运行中的线程没有被中断过。这样就没有竞争条件并会产生我们预期的输出。看起来就像是这样。

如图中所示这是一系列的有序事件组成的。注意 GIL 锁环绕着 Ruby 代码,所以两个线程不能真的并行跑。事件是有序的,从上到下依次发生。
在这样的交错中,线程 A 做完了它所有的工作,之后线程调度器触发了一个上下文切换到线程 B。由于线程 A 已经薅完了羊毛并更新了shorn变量,线程 B 其实什么也没做。
但事情不总是这样简单。注意线程调度器可以在这块代码的任意一点触发上下文切换。这次只是我们运气好而已。
来看看更凶残一些的例子,这回会产生意外的输出。
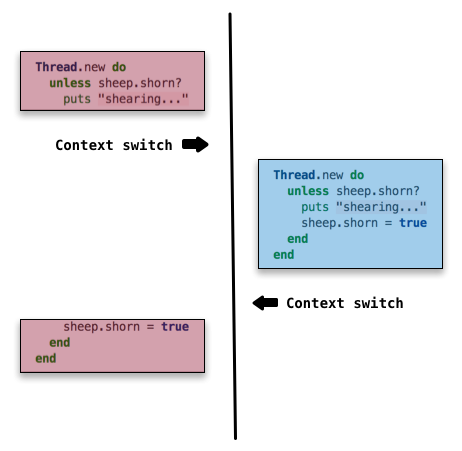
在这样的交错时,上下文切换真发生在会产生问题的地方。线程 A 检查了条件并且开始薅羊毛了。之后线程调度器调度了一个上下文切换,线程 B 上位了。尽管线程 A 已经执行了薅羊毛的工作,但尚未有机会更新shorn属性,于是线程 B 对此一无所知。
线程 B 自己也检查了条件,发现是false,又薅了一回这只羊。一旦其完成了,线程 A 又被调度回来,完成执行。即使线程 B 在执行期间已经通过代码设置了shorn = true,线程 A 也需要在做一遍,因为它就是在这退出又恢复的。
一只羊被薅两次也没什么大不了的,但是试将羊替换成发票,薅羊毛替换成集款,那一些客户就该不 happy 了。
我会分享更多例子来阐述事物不确定性的本质。
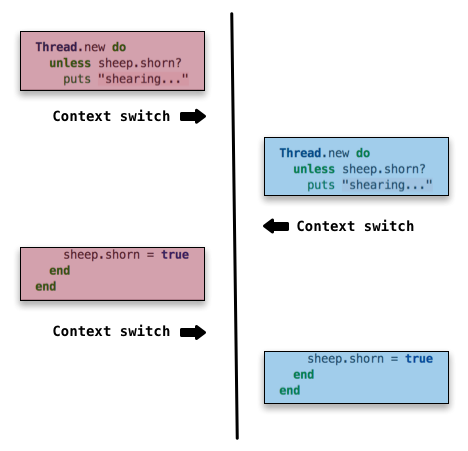
这里加入了更多的上下文切换,于是每个线程占小步前进,而且来回切换。请注意这里展示的是理论上的情况,上下文切换可以发生在程序的任何一行。每次代码执行交错的发生也不尽相同,所以这一次它可能会得到预期结果,下回就可能得到意外结果。
这真的是思考竞争条件的一种好方法。当你执笔多线程代码时,你需要考虑到程序可能背怎样切开和穿插,并产生多种多样的交错。如果一些交错貌似会带来错误的结果,你也许就要重新考虑解决问题的方法或者是用Mutex引入同步机制。
真糟糕!
此刻正应告诉你用Mutex引入同步机制可以使示例代码线程安全。这是真的,你可以试一下。但我有意举例证明这一观点,这些槽糕的代码可不要用在多线程环境中啊。
无论何时你有多个线程共享一个对象引用时,并对其做了修改,你就要有麻烦了,除非有锁来阻止修改中的上下文切换。
然而,不在代码中使用显示锁,也能简单解决这种特定的竞争条件。这里有个Queue的解决方案。
require 'thread'
class Sheep
# ...
end
sheep = Sheep.new
sheep_queue = Queue.new
sheep_queue << sheep
5.times.map do
Thread.new do
begin
sheep = sheep_queue.pop(true)
sheep.shear!
rescue ThreadError
# raised by Queue#pop in the threads
# that don't pop the sheep
end
end
end.each(&:join)
因为没有变化,我忽略了Sheep的实现。现在,不在是每个线程共享sheep对象并竞争去薅它,队列提供了同步机制。
用 MRI 或其他真正并行的 Ruby 实现来运行,这段程序总会返回预期的结果。我们已经消除了这段代码的竞争条件。即使所有的线程可能多多少少会在同一时间掉用 Queue#pop,但是其内部使用了Mutex来保证只有一个线程可以得到羊。
一旦这个线程得到了羊,竞争条件就消失了。这个线程也没有竞争对手了!
我建议使用Queue作为锁的替代品,是因为它只简单地正确利用了队列。众所周知锁是很容易出错的。一旦使用不当,它们就会带来像死锁和性能下降这样的担忧。利用依赖抽象的数据结构。它严格包装了复杂的问题,提供简便的 API。
惰性初始化
我会一笔带过:惰性初始化是检查 - 后-设置另一种形式的竞争条件。||=操作符实际上扩展为:
@logger ||= Logger.new
# expands to
if @logger == nil
@logger = Logger.new
end
@logger
看看扩展版本,然后想象一下交错在哪会发生。在多线程和无同步的情况下,@logger确实可能被初始化两次。再此强调,两次创建Logger可能没什么的,但是我见过一些 Bug 像是in the wild就是这个原因造成的。
反思
在最后我想给大家一些忠告。
5 个牙医里有 4 个同意多线程编程很难做到正确。
最终,GIL 保证了 MRI 中 C 实现的原生 Ruby 方法执行的原子性(即便有些警告)。这一行为有时可以帮助作为 Ruby 开发者的我们,但是 GIL 其实是为了保护 MRI 内部而设计的,对 Ruby 开发者没有可靠的 API。
所以 GIL 不能解决线程安全的问题。就像我说的,使多线程编程正确很难,但是我们每天都在解决棘手的问题。我们面对棘手问题的方法之一是良好的抽象。
举例来说,当我的代码需要发一个 HTTP 请求时,我需要用一个套接字。但我并不直接使用套接字,这样既笨重又容易出错。相反,我使用一个抽象。一个 HTTP 客户端来提供更具体,简便的 API,把与套接字的交互和相关边界问题隐藏起来。
如果多线程编程很难保持正确,也许你不应该直接干。
如果程序里增加一个线程,可能同时增加 5 个新 Bug。
我看到越来越多围绕线程的抽象出现了。在 Ruby 社区里流行起了并发的角色模型,最受欢迎的实现是Celluloid。Celluloid 结合 Ruby 对象模型和并发原语提供了良好的抽象。Celluloid 无法保证你的代码线程安全或对竞争条件免疫,但它包装了最佳实践。我希望你试一试Celluloid。
我们谈论这些不特定于 Ruby 或者 MRI。这是一个多核编程的真实世界。我们设备上的核数只会越来越多,MRI 仍然在寻找解决方案。尽管它的保证,GIL 限制并行执行的方向似乎是错误的。这也是 MRI 的成长的烦恼吧。其他实现,如 JRuby 和 Rubinius 中已经没有了 GIL,现实了真正的并行。
我们看到许多新的语言,具有内置在语言核心内的并发抽象。Ruby 没有,至少目前还没有。依赖于抽象的另一个好处是,抽象可以改进它们的实现,同时保持(业务逻辑)代码不变。例如,如果队列的现实从依靠锁切换到无锁同步,而得益于抽象,你的代码无需任何修改。
目前,Ruby 开发者应该在这些问题上自我提高!了解并发。警惕竞争条件。以交错方式思考代码可以帮助你研究竞争条件。
我会引用这句话,它对今天并发领域工作的影响是巨大的。
别用状态共享通信,用通信共享状态。
使用数据结构来提供同步机制;角色模型即使如此。这一理念也存在于 Go,Erlang 和其他一些语言的并发模型内核里。
Ruby 需要看看别的语言里做了什么并且拥抱变化。作为一个 Ruby 开发人员,你现在就可以尝试和支持这些可替代方案(指其他语言中的)。随着越来越多人参与进来,这些方案有可能会成为 Ruby 的新标准。
感谢 Brian Shirai 为我校队本文草稿。
