数据库 Redis 实战之薄荷 timeline 的优化
Redis 可谓开发工具中的瑞士军刀,小巧易用而又功能强大。但是毕竟只是工具,合适的用法加上不断优化的算法组合起来方能达到高效。最近在优化薄荷的 timeline, 积累了一些小小的经验,这里来和大家分享一下。
薄荷是中国领先移动健康公司,主要产品包括“薄荷”、“轻卡减肥”和“食物库”长期位于 App Store 健康健美榜前列,长期位于各大 Android 应用市场健康或生活类应用前列,总用户已达千万级。
timeline 是一个类似于微博的系统,薄荷的用户可以在上面交流一些自己减肥、健身等等等一堆事。对于薄荷这样一个用户量级的 APP, timeline 这里面临的挑战还是挺大的。合理的利用 cache 等等之类的这些大体都提过,这里主要来说一些容易忽视的地方。
Redis 中的 N + 1 Query
都说过早优化比 gcd 还邪恶,真到了要优化的时候我们也应该根据数据来寻找突破口,而不是靠猜。这是 timeline 首页接口的数据,它返回了固定条数的关注用户发布的动态,可以看出,这个接口确实挺慢的。尤其是 Redis 的请求那里,简直慢的不正常,居然用了 36.9 ms !!! 这完全不应该是 Redis 应有的表现。
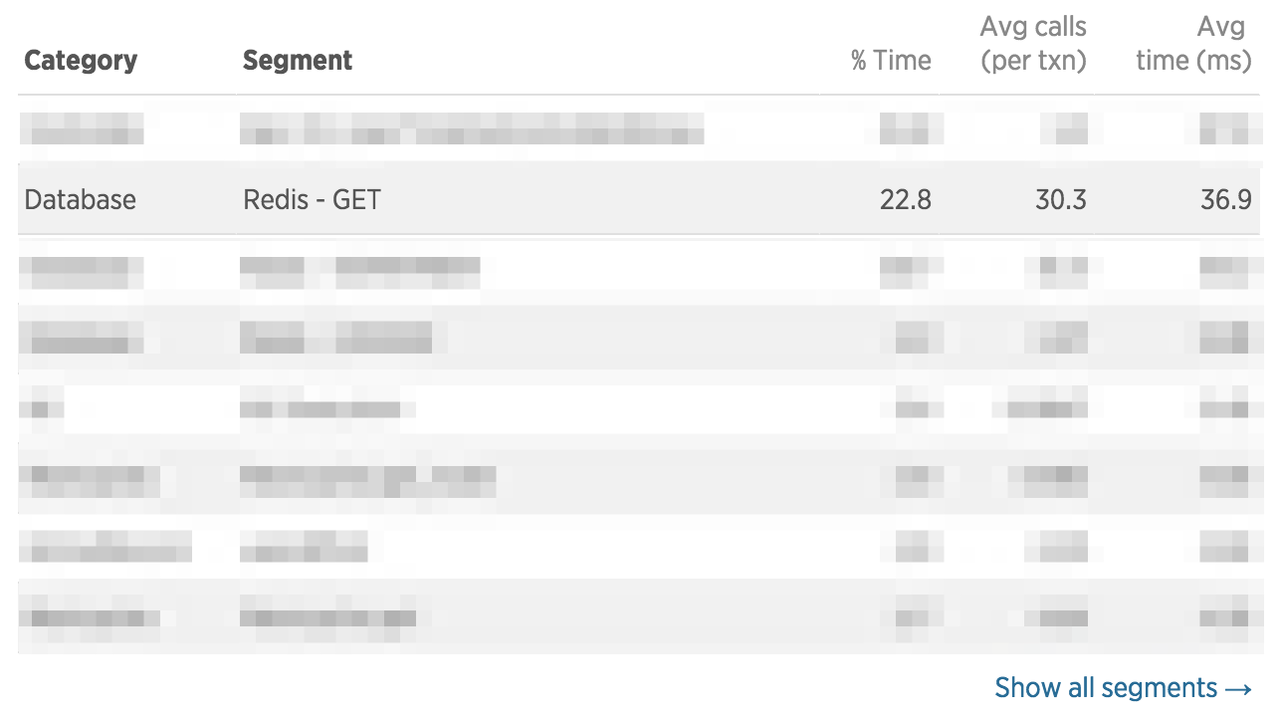
检查了一下代码,发现是构建 response 的过程中,每一条动态都会要获取这条动态获得了多少赞、有多少评论、自己是否点过赞以及是否转发过。而这四个属性都是从 Redis 中读取出来的。也就是说如果这个接口返回了 20 条动态的话,我们需要 call 80 次 Redis。在以前的观念中,Redis 中的数据就像是一个 local variable 一样,可以随便调来调去。但是 Redis 也毕竟是数据库,这每一次调用都是一次 IO 操作。
Redis 中直接为我们提供了解决的办法,pipeline 指令,通过这个指令我们可以把这些操作批量执行,原本 80 次请求降到 1 次,最终的效果也是立竿见影。可见即使对于 Redis 这样的内存数据库,我们也是会遇到所谓的 N + 1 query 的问题的。
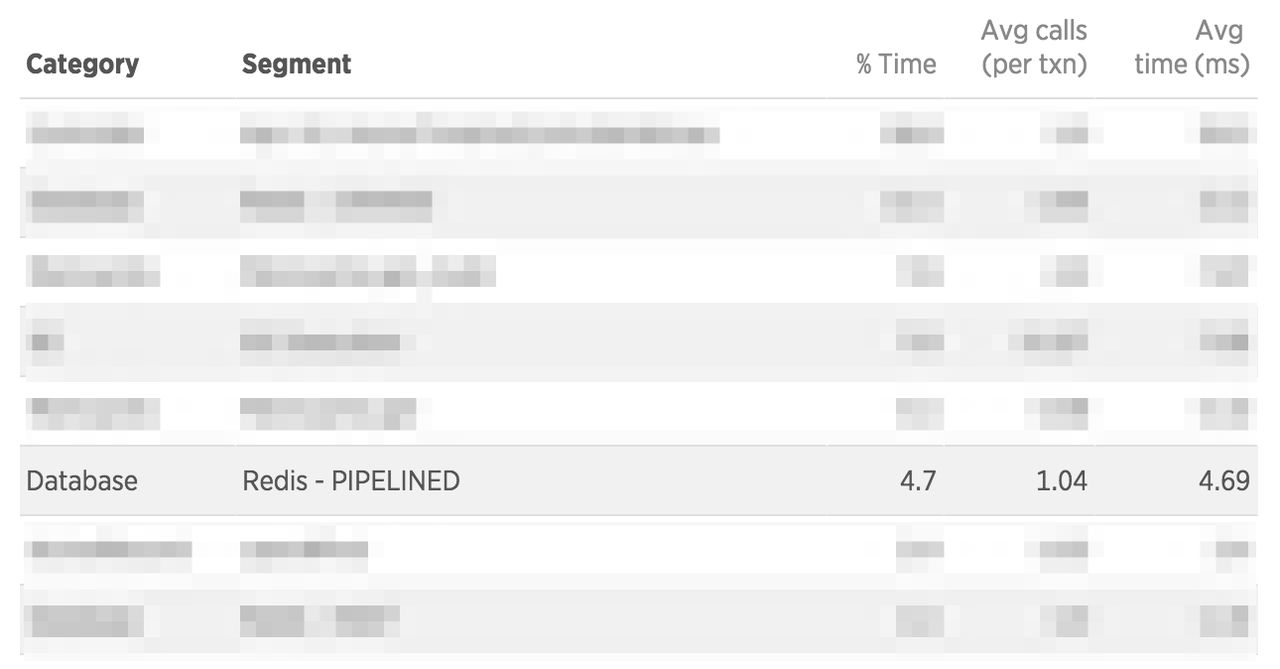
整个请求的响应时间也是骤减,不得不说,这感觉真爽 ^..^
大 V 用户发动态时的处理
大 V 发动态的时候也是让我们一直头疼的一个问题,我们的 timeline 采用的是主动推的策略,每个用户的 timeline 是由一个 Redis list 来维护,里面存放着用户关注的好友发布的动态的 ID。每当一个用户发布动态的时候,会把动态的 ID 推到他的粉丝的 timeline 中。大部分时候,这个工作的都是很好的,但是对于那些大 V 用户,这个让人有些头痛了。拿薄荷的官号来说,他的粉丝数已经过千万了,每当发布一条动态的时候,会需要推 ID 的异步任务去向上千万个用户的 timeline 里去推。这样一来,我们遇到了下面几个问题:
- 执行很慢,有时需要 2 个小时以上,消耗资源大
- 速度慢导致了实效性差,别人发一条动态自己肯能过两个小时才能看到,进而降低了用户使用时长
- 由于这些都是在一个 sidekiq 任务中,所以如果执行过程中重启了,又会从头再来,天啊。。。
期间我们想过很多解决的办法,譬如统计活跃用户只给活跃用户推,执行异步任务的时候统计已经推过的用户,这样防止遇到重启之后重复执行任务的情况。总之想了一堆的解决方案,后来发现事情越来越复杂。拿统计活跃用户来说,即使活跃用户只有 1/5, 拿薄荷的官号来说还是有 200 万的用户要推,而且说别人不活跃,万一刚推完别人就登陆了呢。。。最后想来想去,既然主动推这么麻烦,那就用户主动去拉取吧。大致流程如下:
首先
对于粉丝数超过一定数量的用户,他们发动态的时候直接推到一个专门的 sorted set 中,sorted set 是 Redis 中一个很强大的数据结构,感觉类似于 list 和 hash 的结合。存储的方式还是有一些小小的设计,key 是 "#{user_id}/#{post_id}" 的形式,score 是一个时间戳。为什么要这么做呢,后面细细说来。同时存放一个 redis 的 value, 是大 V 用户最后发动态的时间,每当这些大 V 用户发动态的时候更新一下这个时间。
然后
每次用户去刷 timeline 的时候,会去检查他最后刷 timeline 的时间,和那些大 V 用户最后发动态的时间对比,如果大的话,说明 timeline 已经是最新的了,就不用管了。如果小的话,说明上一次到这一次刷动态的时间段内有大 V 发动态了。如果小的话,说明可能自己关注的大 V 发动态了,因为前面那个 sorted set 维护的是所有大 V 用户的动态,所以并不一定是自己关注的大 V 用户发布的动态。因此,
再然后
前面说到的那个 key 派上用途了,先来说说我们拿数据的过程吧。Redis sorted set 可以根据 score 的范围来拿出 key(ZRANGEBYSCORE min max), 我们使用这条指令根据用户上一次刷动态的时间和当前的时间来做范围来拿出没刷的这个时间段的新动态。这个数据的结构大概类似于下面这样。
users_posts = ["21/13", "22/15", "22/16", "28/33", "55/60"]
前面说到了我们并不一定关注了所有大 V, 所以对于大 V 用户我们专门用一个 set 来存放他们的 ID, 自己关注的用户的 ID 存在一个 set 中。这样我们只需要使用 SINTER 来求两个 set 的交集。假如返回的数据是 ['21', '55']。
我们需要对 users_posts 的数据进行结构化,因为我们只需要自己关注的大 V 的动态的 ID, 这也是前面 sorted set 的 key 这样设置的原因。结构化后的数据如下:
{
'21' => ['13'],
'22' => ['15', '16'],
'28' => ['33'],
'55' => ['60']
}
再根据我们关注的大 V 的 ID 我们就可以很轻松的拿到需要的动态的 ID 了,再合并到自己的 timeline 中即可。最后再更新一下自己最后自己同步 timeline 的时间即可。
上线之后效果果然还是很赞的,薄荷发动态也是直接秒刷了。不过这个解决方案还是存在一些问题的,比如:
- 当大 V 数量增多的时候,这个的维护是一个问题
- 当大 V 数量增多时,比对选出自己关注的耗时也会增长
- 特定情况会存在有些动态丢失刷不到的问题
- 暂时想到这几个,不过肯定还是有不少问题
所以,欢迎一起来和我们迎接挑战,把它优化的更棒~ 有兴趣请看,薄荷热聘
