-
ZT 不要复杂化 Vim at 2013年08月19日
颜色插件 c.vim airline vundle vim 插件排行榜前 10 名的不错
-
每个回帖是不是应该有个淡淡的背景色 at 2013年08月19日
嗯
-
放眼望去都是 Ubuntu,有用 Arch 的玩家么? at 2013年08月19日
玩过 arch 和 gentoo 之后,再玩 ubuntu.
-
(已解决) 一个 map reduce 的脚本,求和以及求平均值,但是却得到一堆 undefined at 2013年08月18日
文档格式是 json 吗? 直接
require 'json' obj = JSON.parse open('doc.txt').read p obj -
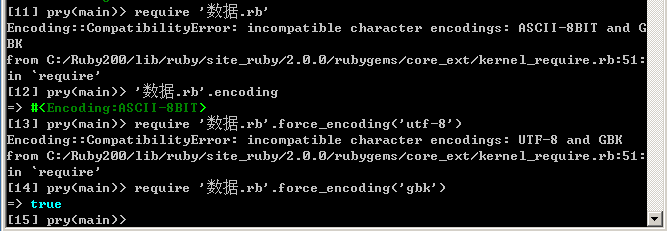
Ruby2.0+ 的内部编码设计,以及 Windows 的问题 at 2013年08月18日
不过文件名用中文,感觉是不规范的行为。就像数据库字段名用中文一样,不规范。
而且 NTFS 文件系统,文件名存入硬盘时,其实是 UTF-16 的。
-
Ruby2.0+ 的内部编码设计,以及 Windows 的问题 at 2013年08月15日
-
如何获得数组里面连续的多部分 at 2013年08月15日
学到了 Array#chunk,和 slice_before
:) -
Ruby2.0+ 的内部编码设计,以及 Windows 的问题 at 2013年08月15日
你的源代码 xxx.rb 里面都这样写:
#!/usr/bin/env ruby # -*- coding: utf-8 -*-当然 xxx.rb 本身也是 utf-8 存储。(用记事本打开,另存为时显示的是 UTF-8,或找个能显示编码的编辑器)
然后你的项目的数据库存储也用 utf-8 . (不然需要 iconv 转换一下,ruby2.0 用 Converter 转换。)
你的项目的配置文件或其他 dat 格式,bin 格式用 utf-8 存储。File.open('xx.dat', "wb:UTF-8")
这样就符合你的需求了。ruby2.0 不用关心文件名是用什么存储的。
-
发现一个 Array 的坑 at 2013年08月15日
-
发现一个 Array 的坑 at 2013年08月14日
-
如何获得数组里面连续的多部分 at 2013年08月14日
这个只能 a.each 一个个遍历吧。。
-
如何获得数组里面连续的多部分 at 2013年08月14日
哦,搞错了,哈。
-
写 ruby 用神马编辑器咧? at 2013年08月14日
越是智能的语言,IDE 的计算量就越大。对 IDE 的要求就越高。 eclipse 不错。
-
一份 Ruby 面试题 at 2013年08月14日
每题都很高深。
-
学习 Ruby 一定得了解 Rails 么 at 2013年08月14日
没学过 rails 的路过。。
-
一小段代码重构 at 2013年08月13日
h={} h[/^$/] = "Fine. Be that way!" h[/^[A-Z]+$/] = "Woah, chill out!" h[/.*?&/] = "Sure" h.default = "Whatever." print h[words]关键是 key 和 value 的对应关系。
如果添加一个也很简单:
h[/xxx/] = 'not xxx ' -
造云记 (1):从零打造一个私人云 (提纲) at 2013年08月09日
高端 大气 上档次
-
有没有人和我一样,Vim 保存的时候经常按成:W at 2013年08月08日
ommand W w -
Windows 生存手册 for Rubyists at 2013年08月08日
awesome 不错
-
2.1 复数的写法 at 2013年08月07日
1% 的程序需要用到复数吧?
-
Ruby 写 Arduino 不靠谱! at 2013年08月07日
-
Ruby 写 Arduino 不靠谱! at 2013年08月06日
unsigned char local_ip[] = {192,168,1,2};
[192,168,1,2].map{|x| x.chr}.join.unpack('L')[0]
L | Integer | 32-bit unsigned, native endian (uint32_t) http://ruby-doc.org/core-2.0/String.html#method-i-unpack
-
UCloud 正式成为 Ruby China 的赞助商 at 2013年08月04日

-
服务器迁移,停机一小会儿 [已完成] at 2013年08月02日
变快很多啊。 :)
为啥换个机房呢?
-
奇怪的环境变量,是不是 ruby 的 bug 啊? at 2013年08月02日
#10 楼 @wongyouth 确实,bash 没这个 bug 哈
-
奇怪的环境变量,是不是 ruby 的 bug 啊? at 2013年08月02日
U=a ; echo $U 这样呢?