最近想把一个 1.8.7 上做的一个内部测试框架,转到 ruby2.0 上。因为是在 window 上用的,而我们的代码都是 utf-8 编码编写的,在 windows 上的 ruby1.8.7 编码很多不能满足我们要求的地方,我们做了很多 hack 操作,比如在文件路径做一下 utf-8 到 gbk 的转码等等。
现在 ruby2.0 来了,而且编码上有了很大的变化,而且据说 windows 上启动速度也快很多,所以就动了升级的念头。过程中碰到了很多的问题,通过修改 ruby 的底层 C 代码解决了一些问题,也给社区提交了一些 bug 和补丁,但是和 ruby 开发团队的交流有点儿问题,谁让咱英语不过关呢。所以把自己的一些收获和问题发出来,希望大家能一起交流一下。
现在主要修改的是 Ruby 的 trunk 版,所以以下的 ruby 指的都是 trunk 版。所有问题也是在 windows 下出现的。
ruby 内部有四个 encoding,internal encoding,external encoding,locale encoding,filesystem encoding,好像还有一个 src 的 encoding,我没怎么接触到,默认好像是 utf-8。 一般我们能够指定的是内部和外部编码,用-E 参数可以指定。
我的理解是:
- internal encoding 是内部的编码,默认情况下 ruby 代码的字符串都应该编码成这个编码。
- external encoding 是外部的编码,从外部加载进入的内容大多是这个编码。
- locale encoding 是本地 locale 的编码,和 external encoding 有一定关系,如果没有指定 external encoding 的话,应该默认就是这个编码(我没有确认)
- filesystem encoding 是文件系统的编码,例如打开文件,枚举目录都返回的内容的编码。
locale encoding 和 filesystem encoding 都是内部实现使用的,如不要代码中一般用不到。
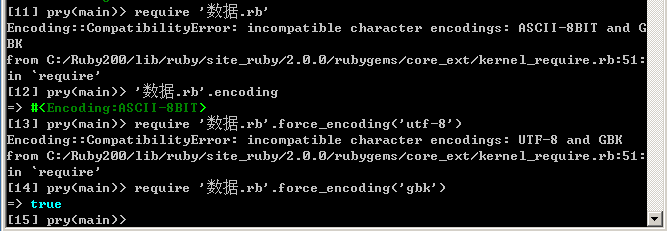
现在的问题是,ruby 内部代码中并没有在所有的边界的地方把编码转换成 internal encoding,比如$LOADPATH 是 locale encoding。导致直接 require 中文文件会编码不兼容错误。
好像 ruby 内部实现并不是按照我说的这个编码原则,我也不知道 ruby 编码原则是啥,也找不到相关的文档,不知道大家有没有相关的信息,或者有知道的也一起讨论一下。